El Servicio de búsqueda de texto completo ofrece ahora mejor rendimiento de búsqueda y utilización de recursos en todo tu cluster con la introducción de Scopes y Collections en Couchbase 7.0.
Demos un rápido paso atrás: El Versión 7.0 de Couchbase Server introduce el concepto de Ámbitos y colecciones que permiten asignar nombres a los datos de un bucket de Couchbase. En lugar de todos los JSON tienen que residir en un único espacio de nombres compartido, los Ámbitos y las Colecciones le proporcionan una capacidad integrada para agrupar documentos en lugar de tener que añadir atributos manuales como tipo a un documento.
Exploremos cómo puede indexar y buscar los datos en sus Ámbitos y Colecciones utilizando el Servicio de Búsqueda en Couchbase.
Cómo indexar datos para su búsqueda dentro de una misma colección
En Servicio de búsqueda de texto completo (FTS) de Couchbase funciona exactamente igual que antes cuando se trata de operar y definir nuevos índices en documentos que residen dentro de un Bucket. Con Ámbitos y Colecciones, todos los documentos existentes (anteriores a la versión 7.0) en un Bucket se clasifican en el índice Por defecto Ámbito de aplicación Por defecto Colección. Y los índices existentes siguen indexando las nuevas mutaciones y todas las consultas funcionan como de costumbre.
Una vez que tu equipo adopte Ámbitos y Colecciones, los usuarios de bases de datos empezarán a asignar nombres a documentos multi-esquema en varias Colecciones. Aquí es donde Couchbase Full-Text Search cambia con la versión 7.0.
El Servicio de Búsqueda admite creación de índices en una única colección de origen, así como en varias colecciones de origen, siempre que todas las colecciones pertenezcan a una colección solo Alcance.
Esencialmente, el Los índices de búsqueda pueden abarcar varias colecciones, pero no varios ámbitos..
Ejemplo: Búsqueda de texto completo con un CRM
Profundicemos en los detalles con la ayuda de un ejemplo.
Considere un caso de uso de CRM en el que los detalles de sus clientes se capturan en un Clientes Bucket y los datos de su pedido en un Pedidos Cubo.
Supongamos que ha organizado varios clientes en diferentes Ámbitos en función de las regiones geográficas. Por ejemplo, asignar todos los clientes de la región Asia-Pacífico a un Alcance específico denominado apac etc.
El siguiente diagrama ilustra cómo podría organizar sus Cubos, Ámbitos y Colecciones para su CRM.
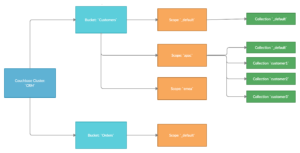
Con las colecciones, la indexación y búsqueda de datos a partir de una única fuente es el caso de uso más común y natural. Funciona de forma similar al proceso de creación de índices basado en cubos. La única diferencia es que el usuario debe especificar el ámbito y los detalles de la colección al crear la definición del índice.
Si está indexando el Ámbito y la Colección por defecto dentro de un Cubo, entonces la función pasos para la creación de índices se ven exactamente igual que en los días anteriores a la Colecta.
Si quieres indexar un Ámbito y/o Colección(es) no predeterminados, tienes que marcar la casilla "Usar Ámbito/Colección(es) no predeterminados" en la interfaz web de Couchbase. Una vez completado este paso, el proceso de creación del índice te pedirá que introduzcas los detalles del Ámbito y la Colección de origen, tal y como se muestra en el siguiente diagrama.
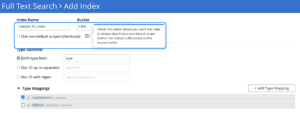
Una vez activada la casilla Ámbito/Colección(es) no predeterminada(s), puede elegir el Ámbito de origen de los documentos (véase más abajo). Observe que el desplegable Ámbito muestra ahora todos los Ámbitos disponibles dentro del Cubo elegido (el CRM, en nuestro ejemplo).
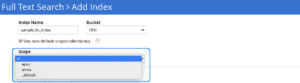
Como se muestra en la captura de pantalla anterior, puede seleccionar el Ámbito al que pertenece la Colección en la lista desplegable, como se muestra arriba.
Especificación de asignaciones de tipos
Una vez seleccionado el Ámbito, ya puede especificar el tipo de documentos que desea indexar.
La convención es especificar el tipo de documentos sobre las asignaciones de tipos, y este mismo patrón de definición de asignaciones de tipos continúa aquí también. Al añadir una nueva correspondencia de tipos, el usuario tiene la opción de especificar la colección de origen, como se muestra a continuación.
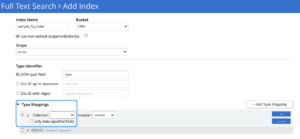
El usuario debe poder ver todas las Colecciones disponibles en el Ámbito mencionado (por ejemplo, emea) como una lista desplegable como arriba.
Indexación de todos los tipos de documentos de una colección determinada
Puede indexar cada tipo de documento en una colección seleccionando el nombre de la colección en la lista desplegable del nombre de la asignación de tipos. Vea un ejemplo en la imagen siguiente.
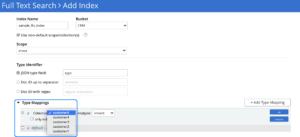
Indexación de varios tipos de documentos en una colección
Si la colección contiene varios tipos de documentos, puede especificar cualquier número de nombres de asignación de tipos interesados seguido del nombre de la colección, como se muestra a continuación.
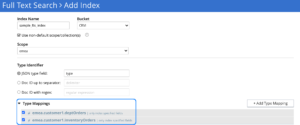
El ejemplo anterior indexaría tipos de documentos como deptOrders y inventoryOrders de la Colección cliente1 en el ámbito de aplicación emea.
Notas de escalado
Dado que los datos de los buckets se dividen ahora en una granularidad mayor a partir de los ámbitos y las colecciones, es más probable que los documentos de cada una de las colecciones tengan una cardinalidad menor.
Dependiendo de la especificidad de sus Colecciones, podría no necesita utilizar la configuración de partición predeterminada de 6 por índice para alimentar un conjunto de datos más pequeño.
Utilizar el recuento de particiones adecuado para una determinada cantidad de datos ayuda a soportar:
-
- Mejor utilización de los recursos de un nodo
- Un mayor número de índices en un nodo determinado
- Mejor rendimiento de búsqueda
Como resultado, le recomendamos que explore la posibilidad de anular el recuento de particiones por defecto a un inferior durante el dimensionamiento del cluster.
Notas sobre RBAC
Ahora puede administrar control de acceso basado en roles (RBAC) para índices de búsqueda de texto completo a nivel de Bucket, Scope o Collection(s).
Un usuario con al menos buscar lector en el nivel de la colección de origen podrán acceder al índice de búsqueda de texto completo.
Cómo indexar datos para realizar búsquedas en varias colecciones
Los índices multicolección ayudan a los usuarios a indexar y buscar en varias colecciones de un mismo ámbito, todo desde un único índice. Algunos casos de uso favorables a las colecciones múltiples son:
-
- Los usuarios han dividido los datos en muchas colecciones en las que cada colección o espacio de nombres puede ser una cuenta de cliente o la marca de un producto, etc. (es decir, datos homogéneos en todas las colecciones).
- Los usuarios tienen muchas colecciones de tamaño relativamente pequeño en su conjunto de datos debido a la partición lógica de los datos (es decir, datos heterogéneos en las colecciones).
En todos estos casos, es posible que tenga que crear numerosos índices para permitir la búsqueda de texto completo en los datos de varias colecciones. Sin embargo, la creación y el mantenimiento de un número tan elevado de índices es una tarea engorrosa.
Ahí es donde entran en juego los índices multicolección.
Los índices multicolección alivian la sobrecarga permitiéndole crear un índice paraguas que cubra varias colecciones. Estas colecciones pueden contener o datos heterogéneos.
Especificación de asignaciones de tipos
En la siguiente captura de pantalla, puede ver la definición de las asignaciones de tipos para indexar tipos de datos heterogéneos de diferentes colecciones como cliente1, cliente2 y cliente3. También puede utilizar tipos de datos similares de varias colecciones como cliente1.viajes y cliente3.viajes y similares.
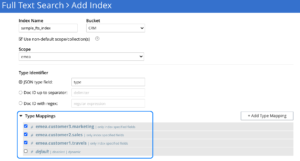
Notas sobre el ciclo de vida
Si se elimina alguna de las colecciones de origen en un índice multicolección, también se elimina el índice.
Por lo tanto, los índices multicolección son los más adecuados para colecciones con periodos de vida similares.
Notas sobre RBAC
En la seguridad RBAC de Couchbase, debe tener buscar lector para todas las colecciones de origen con el fin de acceder a un índice de varias colecciones.
Cómo buscar datos en una colección mediante la búsqueda de texto completo
Índice de una sola colección: Puede buscar y recuperar datos de un índice de una sola colección de la misma forma que lo hacía antes con un índice basado en cubos.
Índice multicolección: Puede realizar búsquedas en índices multicolección utilizando las mismas solicitudes de búsqueda de siempre. Dado que un índice multicolección contiene datos de varias colecciones de origen, resulta útil conocer la colección de origen de los resultados relevantes.
En los índices multicolección, cada resultado de búsqueda contiene información sobre la colección a la que pertenece. Esta información sobre la colección de origen está disponible en el Campos sección de cada acierto bajo la clave $c. Vea un ejemplo en la imagen siguiente.
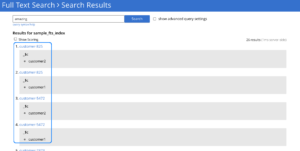
También puede limitar sus solicitudes de búsqueda de texto completo a colecciones específicas dentro del índice de varias colecciones. Este enfoque acelera sus búsquedas en un índice grande.
A continuación se muestra un ejemplo de solicitud de búsqueda de colecciones cliente1 y cliente3.
|
1 2 3 4 5 6 7 8 9 |
{ "consulta": { "frase_de_coincidencia": "superando el presupuesto" }, "colecciones": [ "cliente1", "cliente3" ] } |
Notas de actualización
Sólo puede aprovechar la compatibilidad de Collection(s) con el servicio de búsqueda de texto completo en un clúster Couchbase 7.0 totalmente actualizado.
No se puede habilitar el soporte de Recogidas para FTS en un clúster de versión mixta.
Conclusión
Espero que disfrutes usando el Servicio de Búsqueda de Texto Completo Couchbase con las nuevas características de Ámbitos y Colecciones introducidas en la versión 7.0.
Si desea obtener más información sobre Couchbase Server 7, Novedades y/o las notas de la versión 7.0.
Pruebe Couchbase 7