
The Full-Text Search Service now offers better search performance and resource utilization across your cluster with the introduction of Scopes and Collections in Couchbase 7.0.
Let’s take a quick step back: The 7.0 release of Couchbase Server introduces the concept of Scopes and Collections that enable you to namespace data within a Couchbase Bucket. Instead of all JSON documents having to reside in a single shared namespace, Scopes and Collections provide you a built-in capability to group documents together rather than having to add manual attributes like type to a document.
Let’s explore how you can index and search the data in your Scopes and Collections using the Search Service in Couchbase.
How to Index Data for Search within a Single Collection
The Couchbase Full-Text Search (FTS) Service works exactly the same as before when it comes to operating and defining new indexes on documents residing within a Bucket. With Scopes and Collections, all existing (pre-7.0) documents in a Bucket are sorted into the _default Scope and _default Collection. And existing indexes continue to index newer mutations and all queries work as usual.
Once your team adopts Scopes and Collections, database users will start to namespace multi-schema documents into various Collections. Here’s where Couchbase Full-Text Search changes with the 7.0 release.
The Search Service supports index creations on a single source Collection as well as on multiple source Collections as long as all the Collections belong to a single Scope.
Essentially, the search indexes can span across multiple Collections but not across multiple Scopes.
Example: Full-Text Search with a CRM
Let’s delve into more details with the help of an example.
Consider a CRM use case where your customer details are captured in a Customers Bucket and your Order details into an Orders Bucket.
Let’s assume that you’ve organized various customers into different Scopes based on the geographical regions. For example, mapping all the customers from the Asia Pacific region to a specific Scope named apac and so on.
The diagram below illustrates how you might organize your Buckets, Scopes and Collections for your CRM.
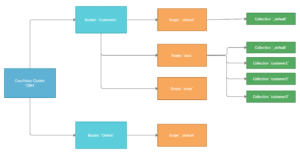
With Collections, indexing and searching data from a single source Collection is the most common and natural use case. It works similar to the existing Bucket-based index creation process. The only difference is that the user has to specify the Scope and Collection details while creating the index definition.
If you’re indexing the default Scope and Collection within a Bucket, then the index creation steps look exactly the same as in the pre-Collection days.
If you want to index a non-default Scope and/or Collection(s), then you need to tick the checkbox for “Use non-default Scope/Collection(s)” in the Couchbase Web UI. Once you complete this step, the index creation process asks you to enter the source Scope and Collection details, as in the diagram below.
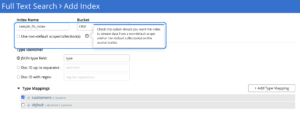
Once you enable the non-default Scope/Collection(s) checkbox, then you can choose the source Scope for the documents (see below). You may note that the Scope dropdown now lists all the available Scopes within your chosen Bucket (the CRM, in our example).

As shown in the screenshot above, you can select the Scope that the Collection belongs to from the dropdown list as shown above.
Specifying Type Mappings
Once you select the Scope, you’re all set to specify the type of documents you want to index.
The convention is to specify the type of documents over the Type mappings, and this same type mapping definition pattern continues here too. Upon adding a new Type mapping, the user is given an option to specify the source Collection as shown below.
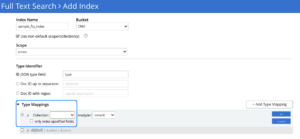
The user should be able to see all the available Collections in the aforementioned Scope (e.g., emea) as a dropdown list like above.
Indexing All Document Types within a Given Collection
You can index every type of document in a Collection by selecting the Collection name from the drop-down list for the type mapping name. See the image below for an example.

Indexing Multiple Document Types within a Collection
If the Collection hosts multiple document types, then you can specify any number of the interested type mapping names followed by the Collection name as shown below.
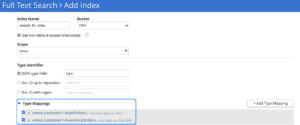
The above example would index document types like deptOrders and inventoryOrders from the Collection customer1 under the Scope emea.
Scaling Notes
Since your Bucket data is now sliced up to a higher granularity from Scopes and Collections, it’s more likely that documents within each of your Collections will have a smaller cardinality.
Depending on the specific of your Collections, you might not need to use the default partition settings of 6 per index to power a smaller dataset.
Using the appropriate partition count for a given amount of data helps support:
- Better utilization of resources on a node
- A higher number of indexes on any given node
- Better search performance
As a result, we recommend you explore overriding the default partition count to a lower value during the cluster sizing.
RBAC Notes
You can now administer role-based access control (RBAC) for full-text search indexes at a Bucket, Scope or Collection(s) level.
A user with at least search reader permissions at the source Collection level will be able to access the full-text search index.
How to Index Data for Search across Multiple Collections
Multi-Collection indexes help your users index and search across multiple Collections within a single Scope – all from a single index. A few multi-Collection-favorable use cases include:
- Users have sliced the data across many Collections where each Collection or namespace could be either a customer account or the brand of a product, etc. (i.e., homogeneous data across Collections).
- Users have a lot of relatively small-sized Collections in their data set due to the logical partitioning of the data (i.e., heterogeneous data across Collections).
In all such cases, you might have to create numerous indexes to enable full-text search on data across multiple Collections. However, it’s a cumbersome mandate for you to have to create – and maintain – such a large number of indexes.
That’s where multi-Collection indexes come in.
Multi-Collection indexes alleviate overhead by just letting you create an umbrella index covering many Collections. These Collections can contain homogeneous or heterogeneous data.
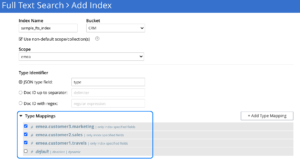
Specifying Type Mappings
In the screenshot below, you can see the definition of type mappings for indexing heterogeneous data types from different Collections like customer1, customer2 and customer3. You could also use similar data types from various Collections like customer1.travels and customer3.travels and the like.
Lifecycle Notes
If any of the source Collections get deleted in a multi-Collection index, then the index is deleted too(!).
Hence multi-Collection indexes are best suited for Collections with similar lifespans.
RBAC Notes
Under Couchbase RBAC security, you must have search reader permissions for all source Collections in order to access a multi-Collection index.
How to Search the Data in a Collection Using Full-Text Search
Single-Collection Index: You can search and retrieve data from a single-Collection index in the same way as you did before with a Bucket-based index.
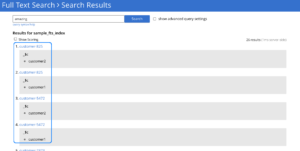
Multi-Collection Index: You can search multi-Collection indexes using the same old search requests. Since a multi-Collection index contains data from multiple source Collections, it’s useful to know the source Collection of their relevant hits.
With multi-Collection indexes, each hit in the search results contains information about the Collection to which it belongs. This source Collection detail is available in the Fields section of each hit under the key _$c. See the image below for an example.
You can also narrow your full-text search requests to only specific Collection(s) within the multi-Collection index. This focus speeds up your searches on a large index.
Below is a sample Collection search request for Collections customer1 and customer3.
|
1 2 3 4 5 6 7 8 9 |
{ “query”: { “match_phrase”: “exceeding budget” }, “collections”: [ “customer1”, “customer3” ] } |
Upgrade Notes
You can only take advantage of Collection(s) support for the Full-Text Search Service on a fully upgraded Couchbase 7.0 cluster.
You can’t enable Collections support for FTS on a mixed-version cluster.
Conclusion
I hope you enjoy using the Couchbase Full-Text Search Service with the new Scopes and Collections features introduced in the 7.0 release.
If you want to learn more about Couchbase Server 7, check out What’s New and/or the 7.0 release notes.
Give Full-Text Search a test run:<br/ >Try out Couchbase 7
Deixe um comentário
Você precisa fazer o login para publicar um comentário.