La monitorización de consultas N1QL y las actualizaciones de perfiles son sólo algunas de las bondades que puedes encontrar en la versión preliminar para desarrolladores de febrero de Couchbase Server 5.0.0.
Vaya a descargue la versión para desarrolladores 5.0.0 de febrero de Couchbase Server hoy, haz clic en la pestaña "Desarrollador" y compruébalo. Aún tienes tiempo de hacernos llegar tus comentarios antes del lanzamiento oficial.
Como siempre, ten en cuenta que estoy escribiendo esta entrada del blog en las primeras versiones, y algunas cosas pueden cambiar en menor medida en el momento en que se obtiene la versión.
¿Para qué sirve la elaboración de perfiles y la supervisión?
Cuando escribo consultas N1QL, necesito ser capaz de entender lo bien (o lo mal) que mi consulta (y mi clúster) está funcionando con el fin de hacer mejoras y diagnosticar problemas.
Con esta última versión para desarrolladores de Couchbase Server 5.0, se han añadido algunas herramientas nuevas a tu caja de herramientas de escritura N1QL.
Revisión de la redacción de N1QL
Primero, un repaso.
Existen múltiples formas para que un desarrollador ejecute consultas N1QL.
- Utiliza el SDK de su elección.
- Utiliza el herramienta de línea de comandos cbq.
- Utiliza el Workbench de consulta en la consola web de Couchbase
- Utiliza el Puntos finales N1QL de la API REST
En este post, utilizaré principalmente Query Workbench.
Hay dos catálogos de sistemas que ya están disponibles en Couchbase Server 4.5 y de las que hablaré hoy.
- sistema:solicitud_activa - Este catálogo enumera todas las peticiones o consultas activas actualmente en ejecución. Puede ejecutar la consulta N1QL
SELECT * FROM sistema:solicitudes_activas;y listará todos esos resultados. - sistema:solicitudes_realizadas - Este catálogo enumera todas las solicitudes completadas recientemente (que se han ejecutado durante más tiempo que algún umbral de tiempo, por defecto 1 segundo). Puede ejecutar
SELECT * FROM sistema:solicitudes_realizadas;y se listarán estas consultas.
Nuevo en N1QL: META().plan
Ambos solicitudes_activas y solicitudes_realizadas devuelven no sólo el texto original de la consulta N1QL, sino también información relacionada: tiempo de solicitud, id de solicitud, tiempo de ejecución, consistencia del escaneo, etc. Esta información puede ser muy útil. He aquí un ejemplo de una consulta simple (select * from ) mientras se ejecuta viaje-muestraselect * from sistema:solicitudes_activas;
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
{ "active_requests": { "clientContextID": "805f519d-0ffb-4adf-bd19-15238c95900a", "elapsedTime": "645.4333ms", "executionTime": "645.4333ms", "node": "10.0.75.1", "phaseCounts": { "fetch": 6672, "primaryScan": 7171 }, "phaseOperators": { "fetch": 1, "primaryScan": 1 }, "phaseTimes": { "authorize": "500.3µs", "fetch": "365.7758ms", "parse": "500µs", "primaryScan": "107.3891ms" }, "requestId": "80787238-f4cb-4d2d-999f-7faff9b081e4", "requestTime": "2017-02-10 09:06:18.3526802 -0500 EST", "scanConsistency": "unbounded", "state": "running", "statement": "select * from `travel-sample`;" } } |
En primer lugar, quiero señalar que phaseTimes es una nueva adición a los resultados. Es una forma rápida y sucia de hacerse una idea del coste de la consulta sin mirar el perfil completo. Le da el coste global de cada fase de la consulta sin entrar en el detalle de cada operador. En el ejemplo anterior, por ejemplo, se puede ver que analizar tardó 500µs y primaryScan tardó 107,3891 ms. Esto puede ser suficiente información para que usted pueda seguir sin bucear en META().plan.
Sin embargo, con el nuevo META().planpuedes obtener información muy detallada sobre el plan de consulta. Esta vez, ejecutaré SELECT *, META().plan FROM system:active_requests;
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 |
[ { "active_requests": { "clientContextID": "75f0f401-6e87-48ae-bca8-d7f39a6d029f", "elapsedTime": "1.4232754s", "executionTime": "1.4232754s", "node": "10.0.75.1", "phaseCounts": { "fetch": 12816, "primaryScan": 13231 }, "phaseOperators": { "fetch": 1, "primaryScan": 1 }, "phaseTimes": { "authorize": "998.7µs", "fetch": "620.704ms", "primaryScan": "48.0042ms" }, "requestId": "42f50724-6893-479a-bac0-98ebb1595380", "requestTime": "2017-02-15 14:44:23.8560282 -0500 EST", "scanConsistency": "unbounded", "state": "running", "statement": "select * from `travel-sample`;" }, "plan": { "#operator": "Sequence", "#stats": { "#phaseSwitches": 1, "kernTime": "1.4232754s", "state": "kernel" }, "~children": [ { "#operator": "Authorize", "#stats": { "#phaseSwitches": 3, "kernTime": "1.4222767s", "servTime": "998.7µs", "state": "kernel" }, "privileges": { "default:travel-sample": 1 }, "~child": { "#operator": "Sequence", "#stats": { "#phaseSwitches": 1, "kernTime": "1.4222767s", "state": "kernel" }, "~children": [ { "#operator": "PrimaryScan", "#stats": { "#itemsOut": 13329, "#phaseSwitches": 53319, "execTime": "26.0024ms", "kernTime": "1.3742725s", "servTime": "22.0018ms", "state": "kernel" }, "index": "def_primary", "keyspace": "travel-sample", "namespace": "default", "using": "gsi" }, { "#operator": "Fetch", "#stats": { "#itemsIn": 12817, "#itemsOut": 12304, "#phaseSwitches": 50293, "execTime": "18.5117ms", "kernTime": "787.9722ms", "servTime": "615.7928ms", "state": "services" }, "keyspace": "travel-sample", "namespace": "default" }, { "#operator": "Sequence", "#stats": { "#phaseSwitches": 1, "kernTime": "1.4222767s", "state": "kernel" }, "~children": [ { "#operator": "InitialProject", "#stats": { "#itemsIn": 11849, "#itemsOut": 11848, "#phaseSwitches": 47395, "execTime": "5.4964ms", "kernTime": "1.4167803s", "state": "kernel" }, "result_terms": [ { "expr": "self", "star": true } ] }, { "#operator": "FinalProject", "#stats": { "#itemsIn": 11336, "#itemsOut": 11335, "#phaseSwitches": 45343, "execTime": "6.5002ms", "kernTime": "1.4157765s", "state": "kernel" } } ] } ] } }, { "#operator": "Stream", "#stats": { "#itemsIn": 10824, "#itemsOut": 10823, "#phaseSwitches": 21649, "kernTime": "1.4232754s", "state": "kernel" } } ] } }, ... ] |
La salida anterior procede del Query Workbench.
Observe la nueva parte "plan". Contiene un árbol de operadores que se combinan para ejecutar la consulta N1QL. El operador raíz es una Secuencia, que a su vez tiene una colección de operadores hijos como Authorize, PrimaryScan, Fetch, y posiblemente aún más Secuencias.
Activar la función de perfil
Para obtener esta información al utilizar cbq o la API REST, tendrás que activar la función "perfil".
Puede hacerlo en cbq introduciendo set -perfil timings; y, a continuación, ejecute su consulta.
También puede hacerlo con la API REST por cada solicitud (utilizando la función /consulta/servicio y pasando un parámetro querystring de perfil=tiempospor ejemplo).
Puedes activar la configuración para todo el nodo haciendo una petición POST a https://localhost:8093/admin/settings, usando autenticación Basic, y un cuerpo JSON como:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
{ "completed-limit": 4000, "completed-threshold": 1000, "controls": false, "cpuprofile": "", "debug": false, "keep-alive-length": 16384, "loglevel": "INFO", "max-parallelism": 1, "memprofile": "", "pipeline-batch": 16, "pipeline-cap": 512, "pretty": true, "profile": "timings", "request-size-cap": 67108864, "scan-cap": 0, "servicers": 32, "timeout": 0 } |
Fíjese en el perfil ajuste. Antes estaba desactivado, pero lo he puesto en "temporización".
Puede que no quieras hacerlo, especialmente en nodos que están siendo utilizados por otras personas y programas, porque afectará a otras consultas que se estén ejecutando en el nodo. Es mejor hacerlo por petición.
También es lo que hace Query Workbench por defecto.
Utilización del Query Workbench
Hay mucha información en META().plan sobre cómo se ejecuta el plan. Personalmente, prefiero ver una versión gráfica simplificada del mismo en Query Workbench haciendo clic en el icono "Plan" (que mencioné brevemente en un post anterior sobre la nueva Couchbase Web Console UI).

Veamos un ejemplo algo más complejo. Para este ejercicio, estoy utilizando el cubo de muestras de viajes, pero he eliminado uno de los índices (DROP INDEX ).viaje-muestra.def_sourceairport;
A continuación, ejecuto una consulta N1QL para encontrar vuelos entre San Francisco y Miami:
|
1 2 3 4 5 6 7 8 |
SELECT r.id, a.name, s.flight, s.utc, r.sourceairport, r.destinationairport, r.equipment FROM `travel-sample` r UNNEST r.schedule s JOIN `travel-sample` a ON KEYS r.airlineid WHERE r.sourceairport = 'SFO' AND r.destinationairport = 'MIA' AND s.day = 0 ORDER BY a.name; |
Ejecutar esta consulta (en mi máquina local de un solo nodo) tarda unos 10 segundos. Definitivamente no es una cantidad de tiempo aceptable, así que echemos un vistazo al plan para ver cuál puede ser el problema (lo he dividido en dos líneas para que las capturas de pantalla quepan en la entrada del blog).

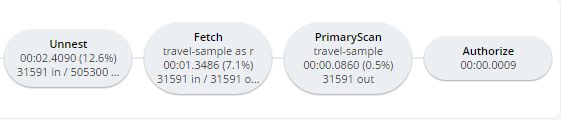
Si se observa el plan, parece que las partes más costosas de la consulta son las siguientes Filtro y el Únete a. ÚNASE A funcionan con teclas, por lo que normalmente deberían ser muy rápidas. Pero parece que hay un lote de los documentos que se unen.
El filtro (el DONDE parte de la consulta) también lleva mucho tiempo. Está mirando el fuenteaeropuerto y destinoaeropuerto campos. Mirando en otra parte del plan, veo que hay un PrimaryScan. Esto debería ser una señal de alarma cuando se intenta escribir consultas de alto rendimiento. PrimaryScan significa que la consulta no ha podido encontrar un índice distinto del índice primario. Esto es más o menos el equivalente a un "escaneo de tabla" en términos de bases de datos relacionales. (Puede que quieras eliminar el índice primario para que estos problemas se solucionen más rápidamente, pero ese es un tema para otro momento).
Vamos a añadir un índice en fuenteaeropuerto campo y ver si eso ayuda.
|
1 |
CREATE INDEX `def_sourceairport` ON `travel-sample`(`sourceairport`); |
Ahora, ejecutando la misma consulta anterior, obtengo el siguiente plan:


Esta consulta tardó ~100ms (en mi máquina local de un solo nodo), lo que es mucho más aceptable. El Filtro y el Únete a siguen ocupando un gran porcentaje del tiempo, pero gracias a la IndexScan sustituyendo el PrimaryScanEn el caso de los operadores de búsqueda, son muchos menos los documentos con los que tienen que trabajar. Tal vez la consulta podría mejorarse aún más con un índice adicional sobre el índice destinoaeropuerto campo.
Más allá del ajuste de las consultas
La respuesta a los problemas de rendimiento no siempre está en ajustar las consultas. A veces es necesario añadir más nodos al clúster para solucionar el problema subyacente.
Mira el PrimaryScan información en META().plan. He aquí un fragmento:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
"~children": [ { "#operator": "PrimaryScan", "#stats": { "#itemsOut": 13329, "#phaseSwitches": 53319, "execTime": "26.0024ms", "kernTime": "1.3742725s", "servTime": "22.0018ms", "state": "kernel" }, "index": "def_primary", "keyspace": "travel-sample", "namespace": "default", "using": "gsi" }, ... ] |
En servTime indica cuánto tiempo emplea el servicio de consulta en esperar en el almacenamiento de datos Clave/Valor. Si el valor servTime es muy alta, pero hay un número pequeño de documentos siendo procesados, eso indica que el indexador (o el servicio clave/valor) no puede seguir el ritmo. Tal vez tienen demasiada carga procedente de otro lugar. Así que esto significa que algo raro se está ejecutando en algún otro lugar o que su clúster está tratando de manejar demasiada carga. Puede que sea el momento de añadir más nodos.
Del mismo modo, el kernTime es cuánto tiempo se pasa esperando en otras rutinas N1QL. Esto podría significar que algo más aguas abajo en el plan de consulta tiene un problema, o que el nodo de consulta está saturado de peticiones y está teniendo que esperar mucho.
Queremos conocer su opinión.
El nuevo META().plan y el nuevo Plan UI se combinan en Couchbase Server 5.0 para mejorar el proceso de escritura y perfilado de N1QL.
Permanezca atento a la Blog de Couchbase para más información sobre la próxima versión para desarrolladores.
¿Le interesa probar algunas de estas nuevas funciones? Descargar Couchbase Server 5.0 ¡hoy!
Queremos tu opinión Todos los meses se publican versiones para desarrolladores, así que tienes la oportunidad de influir en lo que estamos construyendo.
Bichos: Si encuentra un error (algo que no funciona o que no funciona como cabría esperar), presente un problema en nuestra sección Sistema JIRA en issues.couchbase.com o envíe una pregunta a Foros de Couchbase. O ponte en contacto conmigo con una descripción del problema. Estaré encantado de ayudarte o de enviar el error por ti (mis gestores de Couchbase me chocan los cinco cada vez que envío un buen error).
Comentarios: Dígame lo que piensa. ¿Algo que no te guste? ¿Algo que te guste mucho? ¿Falta algo? Ahora puedes dar tu opinión directamente desde la Consola Web de Couchbase. Busca el icono ![]() en la parte inferior derecha de la pantalla.
en la parte inferior derecha de la pantalla.
En algunos casos, puede resultar difícil decidir si su comentario es un error o una sugerencia. Usa tu criterio o, de nuevo, no dudes en ponerte en contacto conmigo para pedirme ayuda. Quiero saber de ti. La mejor forma de ponerse en contacto conmigo es Twitter @mgroves o envíeme un correo electrónico matthew.groves@couchbase.com.
blog muy útil. esperar más información detallada sobre META().plan.
algunas preguntas:
"El valor servTime indica cuánto tiempo emplea el servicio de consulta en esperar en el almacenamiento de datos clave/valor. Si el servTime es muy alto, pero hay un pequeño número de documentos siendo procesados, eso indica que el indexador (o el servicio de clave/valor) no puede seguir el ritmo. Tal vez tienen demasiada carga procedente de otro lugar. Así que esto significa que algo raro se está ejecutando en algún otro lugar o que su clúster está tratando de manejar demasiada carga. Puede que sea el momento de añadir más nodos".
¿Significa esto que es hora de añadir más nodos que ejecuten el Servicio de Datos?
y
"l kernTime es el tiempo de espera de otras rutinas N1QL. Esto puede significar que algo más aguas abajo en el plan de consulta tiene un problema, o que el nodo de consulta está saturado de peticiones y están teniendo que esperar mucho."
¿Significa esto que es hora de añadir más nodos que ejecuten Query Service?
La respuesta a ambas es: tal vez. Depende de lo que esté pasando en tu sistema en ese momento. Puede ser que haya otra consulta problemática en ejecución, o puede significar que has tocado techo con el número actual de nodos.
OK, gracias.
[...] en caso de que te lo hayas perdido, echa un vistazo al post que escribí en febrero sobre el nuevo perfilado y monitorización en Couchbase Server 5.0 Preview, ya que este post [...]
system:completed_requests parece muy útil para consultar los metadatos del sistema y averiguar las consultas con tiempo de espera, las consultas ejecutadas después de los datos/tiempo especificados, etc. Sin embargo, es difícil de consultar porque el tiempo que tarda en completarse es excesivamente alto. A menudo obtengo tiempos de espera para esta consulta. Utilicé la interfaz de administración con un valor de tiempo de espera mayor, pero sigue tardando mucho. Luego utilicé la herramienta cbq y no tuve suerte. Aunque la función es útil, no se puede utilizar en la práctica. Esto es lo que he experimentado.
Susantha, tal vez quieras considerar hacer dos cosas:
1) Publica una pregunta en los foros N1QL. Ese foro es muy sensible y debe ser capaz de ayudarle a cabo -. https://www.couchbase.com/forums/c/sql/16
2) Únete al directorio de la comunidad Couchbase - https://community.couchbase.com/ - este es un lugar que te ayuda a encontrar e interactuar con otros expertos en Couchbase, campeones y miembros de la comunidad como tú. Tal vez quieras publicar tu experiencia y luego preguntar para ver si alguien ha tenido una experiencia similar con el catálogo completed_requests, y qué hicieron al respecto.
Gracias por este artículo. Es de gran ayuda. Especialmente, porque no pude encontrar el significado de las fases en la documentación oficial. Sin embargo, todavía no entiendo lo que es la fase de autorización (estoy tratando de entender esto porque para una de mis consultas la autorización está tomando más de 3 minutos o al menos eso es lo que muestra el plan).
Además, si hay una página oficial en la documentación que explique las fases y los tiempos, por favor, indíquemela.
Saludos
¡Hola Purav! Esta entrada de blog es para una versión anterior de Couchbase Server. Te recomiendo que publiques tu pregunta en el foro de Couchbase para N1QL aquí: https://www.couchbase.com/forums/c/sql/16