Un RDBMS con un esquema bien establecido es útil cuando las funciones de la aplicación permanecen estáticas. Aunque esta estructura rígida puede garantizar la estabilidad, no se presta a los rápidos cambios de los requisitos empresariales. Hoy en día, las organizaciones deben plantearse modernizar su infraestructura de aplicaciones y pasar de RDBMS a NoSQL.
Este artículo examina algunos beneficios del modelo de documentos NoSQL, y cómo los datos y los índices pueden ser organizados para optimizar el rendimiento de las consultas y la configuración de los índices. También discutiré la estrategia de índices que puedes considerar al migrar tu modelo de datos RDBMS a la base de datos NoSQL de Couchbase, y cómo la característica FLATTEN_KEYS de Couchbase 7.1 puede ayudar a mejorar el rendimiento de las consultas y reducir el número de índices.
Una estrategia de índices eficaz es uno de los factores más importantes en el funcionamiento de una base de datos. Nos ayuda a conseguir el equilibrio adecuado entre el rendimiento de las consultas y la gestión de los recursos. La base de datos no sólo debe capturar datos de forma eficiente, sino que también debe proporcionar el acceso más óptimo a esos datos. Las bases de datos NoSQL no difieren de los RDBMS cuando se trata de una estrategia de índices eficaz.
Un caso de uso de RDBMS
Consideremos la hotel en Couchbase viaje-muestra y supongamos que utilizamos el modelo RDBMS para capturar esta información. El modelo relacional sería el siguiente
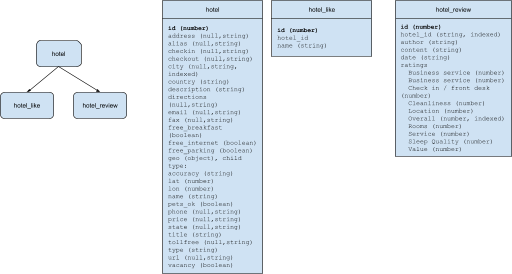
En hotel tiene toda la información detallada sobre el hotel. También hay un hotel_like que registra los nombres de los clientes que han hecho clic en como en la página del hotel en las redes sociales. También hay una hotel_review objeto que registra todas las opiniones sobre hoteles, incluidos comentarios y valoraciones detalladas de los diferentes servicios y comodidades.
Necesidades de la empresa
Cree una consulta que permita a los usuarios obtener una vista resumida de todos los hoteles de una ciudad concreta que tengan previsto visitar. El resumen debe incluir las valoraciones de cada hotel y el número de personas que se han alojado en él. le gusta el hotel. Para acotar la lista, la consulta debe centrarse en las opiniones recientes (2015 para este conjunto de datos) y las valoraciones de las opiniones deben ser de 4 o más (5 es la valoración más alta).
Consulta del modelo relacional
|
1 2 3 4 5 6 7 8 9 10 11 12 |
SELECCIONE h.nombre hotel, cuente(distinto l.nombre) me_gusta, cuente(distinto r.autor) autor_revisión, media(r.clasificaciones.En general) valoraciones_avg DESDE hotel h INTERIOR ÚNASE A hotel_revise r EN r.hotel_id = h.id INTERIOR ÚNASE A hotel_como l EN l.hotel_id = h.id DONDE h.ciudad=Londres Y r.clasificaciones.En general >= 4 Y r.fecha > '2015-01-01' GRUPO POR h.nombre PEDIR POR media(r.clasificaciones.En general) DESC |
El índice para una consulta de modelo relacional
hotel: Dado que hay un filtro sobre la ciudad y el nombre, debería existir un índice. Tenga en cuenta que el hotel id se añade al índice porque puede ayudar con el JOIN.
|
1 |
CREAR ÍNDICE adv_nombre_ciudad_id EN `hotel`(`ciudad`,`nombre`,`id`) |
hotel_review: Hay dos filtros en las reseñas de hoteles: la fecha de la reseña y las valoraciones de la reseña. También es necesario eliminar la doble contabilización, ya que no existe una relación explícita entre hotel_like y hotel_reviewpor lo que el autor de la reseña se añade aquí a tal efecto. En hotel_id también se añade al índice porque es la clave foránea y puede ayudar con el campo ÚNASE A.
|
1 |
CREAR ÍNDICE adv_ratings_Overall_date_hotel_id_author EN `hotel_review`(`clasificaciones`.`En general`,`fecha`,`hotel_id`,`autor`) |
hotel_review: Aunque no hay filtros en hotel_likeEn el caso de los "Me gusta", es necesario eliminar el doble recuento de los "Me gusta", ya que no existe relación entre reseña y "Me gusta". El sitio hotel_id se añade al índice porque es la clave externa y puede ayudar con el JOIN.
|
1 |
CREAR ÍNDICE adv_hotel_id_name EN `hotel_like`(`hotel_id`,`nombre`) |
El plan de ejecución de la consulta del modelo relacional
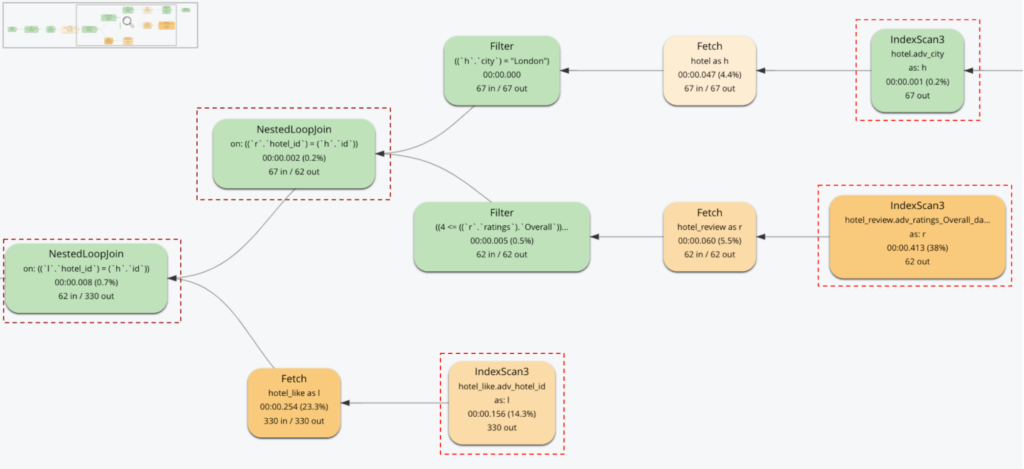
Observa la necesidad de actuar:
-
- Dos JOIN
- Tres exploraciones de índices (una por cada objeto)
La vista Modelo de documento
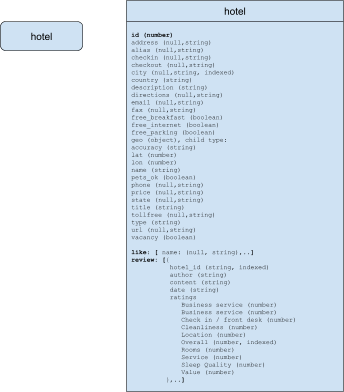
Para el modelo de documento, tanto el hotel_like y el hotel_review se almacenan como matrices en el objeto hotel. No existe una regla estricta que indique que siempre se deben incluir los objetos hijos como una matriz en el objeto padre, pero tiene sentido hacerlo en este caso porque siempre se accede a estos objetos juntos.
La consulta del modelo documental desnormalizado
|
1 2 3 4 5 6 7 8 9 10 11 12 |
SELECCIONE h.nombre hotel, CONTAR(distinto l) me_gusta, CONTAR(distinto r.autor) autor_revisión, AVG(r.clasificaciones.En general) valoraciones_avg DESDE hotel h UNNEST h.reseñas AS r UNNEST h.me gusta_público AS l DONDE h.ciudad=Londres Y r.clasificaciones.En general >= 0 Y r.fecha > '2015-01-01' GRUPO POR h.nombre PEDIR POR media(r.clasificaciones.En general) DESC |
El índice del modelo de documento desnormalizado
|
1 2 3 4 5 6 |
CREAR ÍNDICE adv_ALL_reviews_ratings_Overall_date_ciudad EN `hotel`( TODOS ARRAY FLATTEN_KEYS(`r`.`clasificaciones`.`En general`,`r`.`fecha` DESC) PARA r EN `reseñas` FIN, `ciudad`) |
Algunos puntos a tener en cuenta:
-
- En SQL hace referencia a una única hotel por lo que no es necesario realizar ningún JOIN explícito entre el objeto padre hotel y el hijo como o review
- La consulta utiliza un único índice que cubre todos los predicados de la consulta, es decir, el índice hotel.ciudad, el reseñas.valoracionesy el revisiones.fecha
- Cuando una matriz está indexada, el índice sólo puede estar en una única clave. FLATTEN_KEYS() permite campos compuestos de la matriz, permitiendo así que los predicados estén en múltiples campos de la matriz.
El plan de ejecución de la consulta del modelo documental

Observe la necesidad de realizar
-
- Dos UNNEST (no se necesitan JOINs ya que está en un solo documento)
- Sólo UNA exploración de índices
Resumen
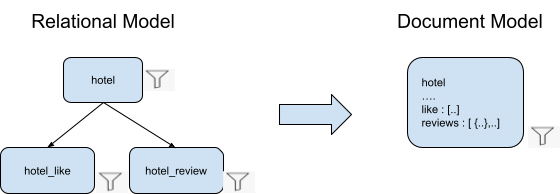
Cuando un modelo relacional se desnormaliza en un único objeto en el modelo documental:
-
- La consulta SQL++ es más sencilla porque no es necesario realizar ningún JOIN
- Múltiples índices de modelos relacionales podrían combinarse en un único modelo documental
- La característica FLATTEN_KEYS de Couchbase 7.1 combina múltiples predicados de elementos de array en un único índice.
Esta es sólo una de las novedades que hemos presentado recientemente. Novedades de Couchbase Server 7.1.