A los científicos de datos les encantan los cuadernos Jupyter - y hace una pareja natural con la base de datos de documentos Couchbase.

¿Por qué? En Cuaderno Jupyter le permite crear y compartir documentos que contienen texto narrativo, ecuaciones y similares para casos de uso como la visualización de datos y el aprendizaje automático. Couchbase le permite almacenar y procesar grandes cantidades de datos (semiestructurados y no estructurados) a escala y admite los tipos de datos de los que está lleno el mundo: texto narrativo (publicaciones en redes sociales, etc.), ecuaciones y mucho más.
En este post, aprenderás a establecer la conectividad entre un clúster de Couchbase y un Jupyter Notebook, luego extraer datos de Couchbase y utilizarlos para entrenar un modelo de regresión lineal para el aprendizaje automático. Vamos a caminar a través de un ejemplo para predecir el valor de una variable de destino utilizando variables categóricas a través de una ecuación de regresión lineal.
Carga de datos
Para empezar, siga estos pasos para cargar el conjunto de datos de muestra:
- En la consola de administración del cluster de Couchbase, ve a Buckets > Add Bucket para crear un nuevo bucket, como se muestra aquí:
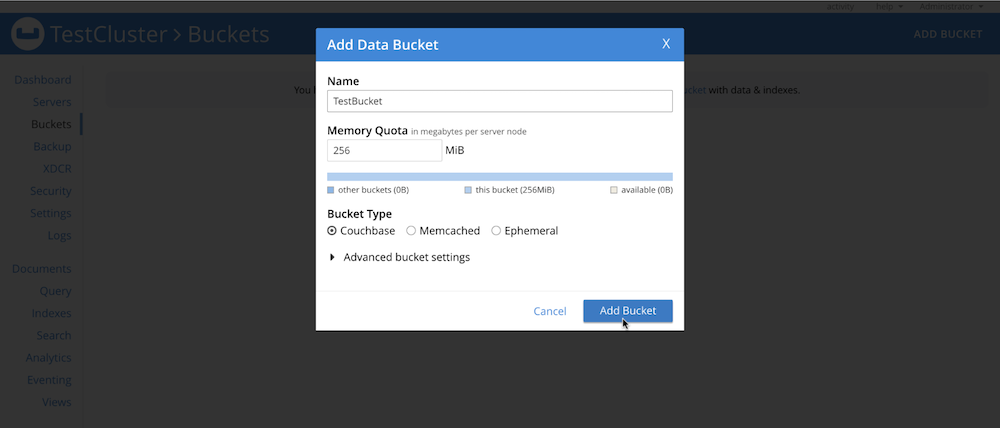
-
Para añadir documentos a su cubo, vaya a Documentos > Añadir documento, como se muestra a continuación:
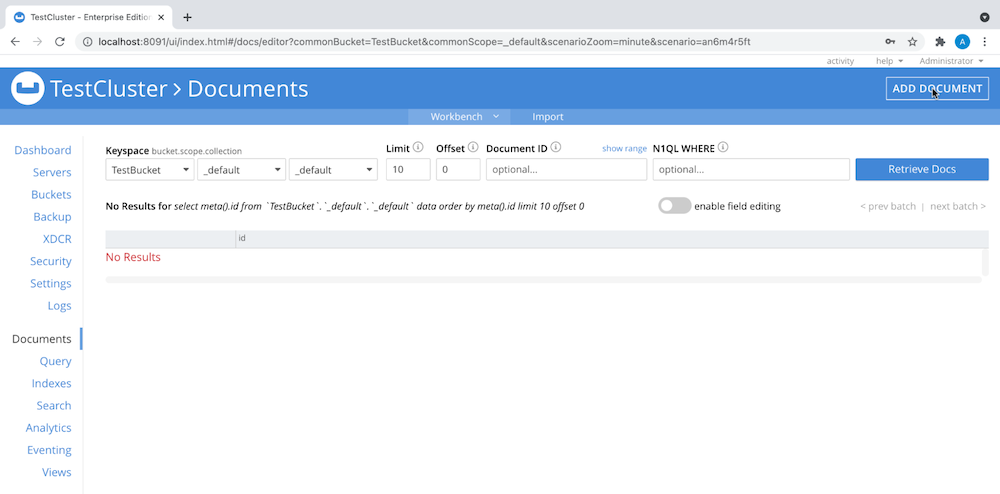
o cargar una lista de documentos JSON o un archivo CSV. En este ejemplo cargaremos un archivo CSV utilizando
cbimport. Este es el aspecto de mi documento: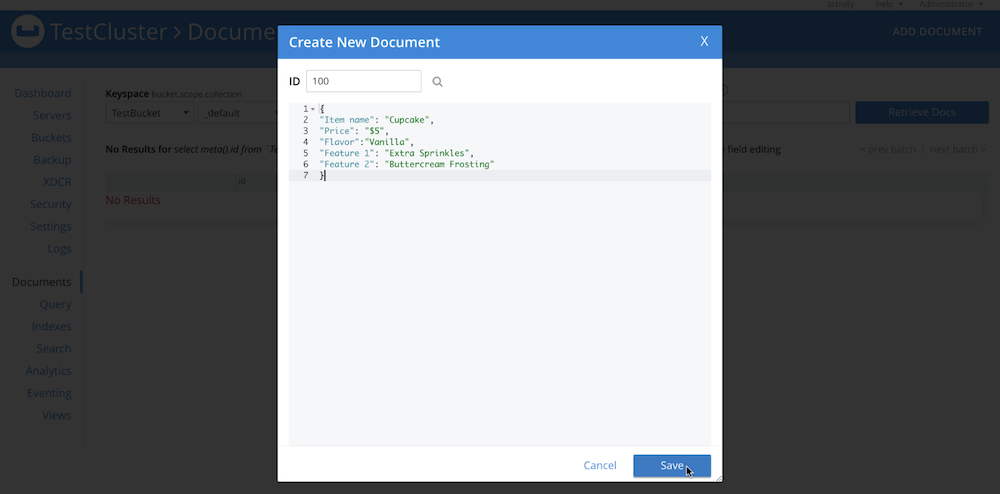
- El archivo puede ser cualquier dato con el que desee trabajar. En este ejemplo se utiliza el archivo Conjunto de datos de publicidad de Kaggle.
- Vaya a Documentos > Importar, como se muestra aquí:
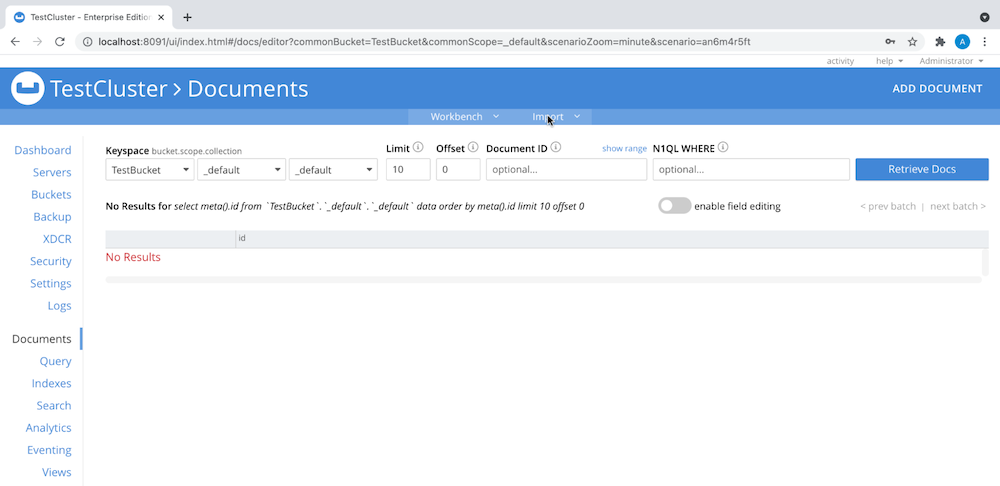
-
Seleccione el archivo que desea importar y el bucket de datos donde residen los documentos:
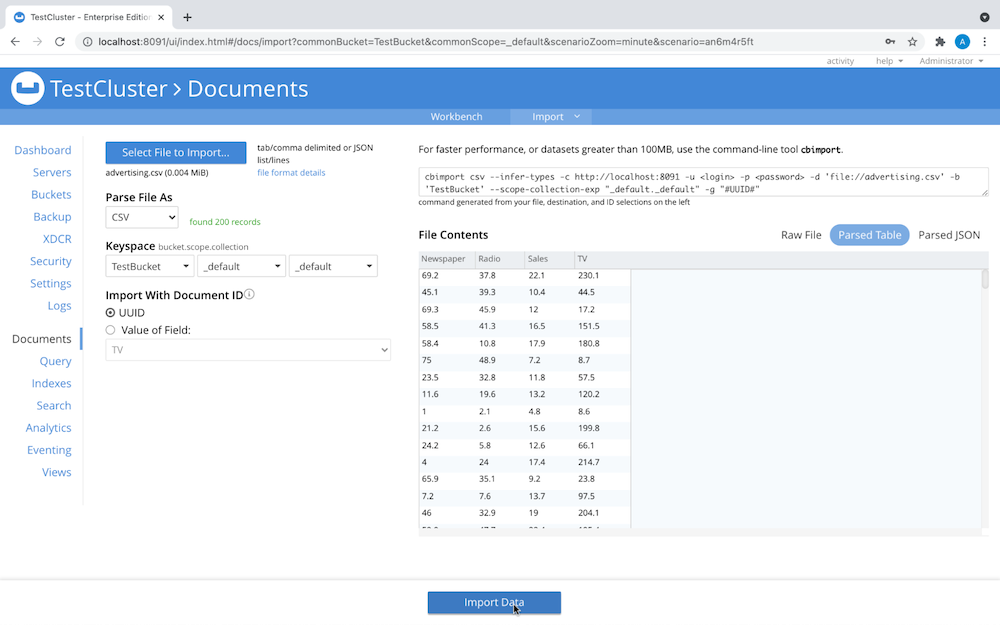
Su menú Documentos debería tener ahora este aspecto:
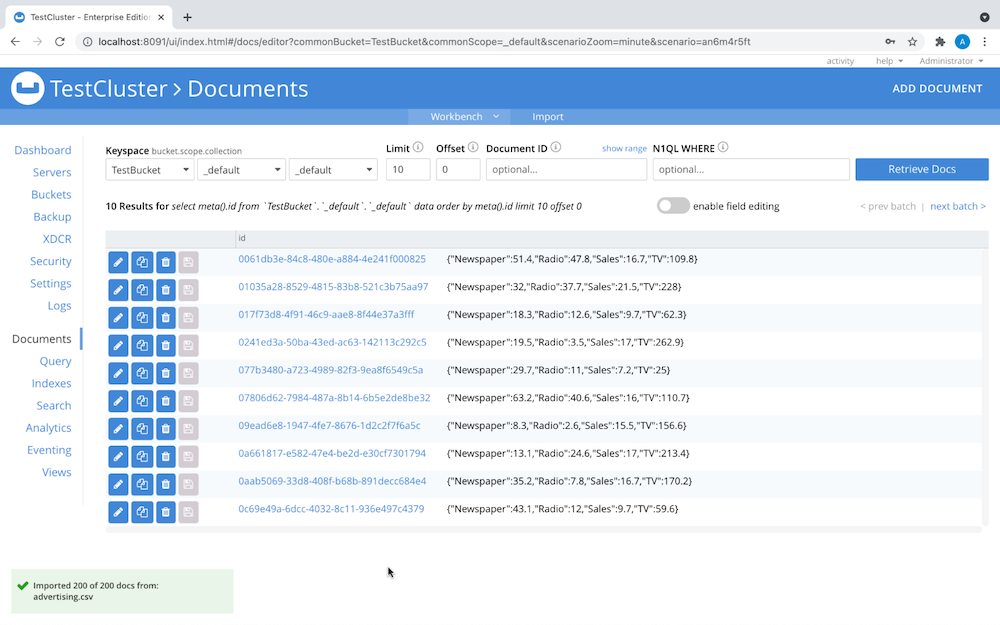
- En Admin Console, cree un índice primario para el bucket de datos para que los datos se puedan consultar, como se ve aquí:
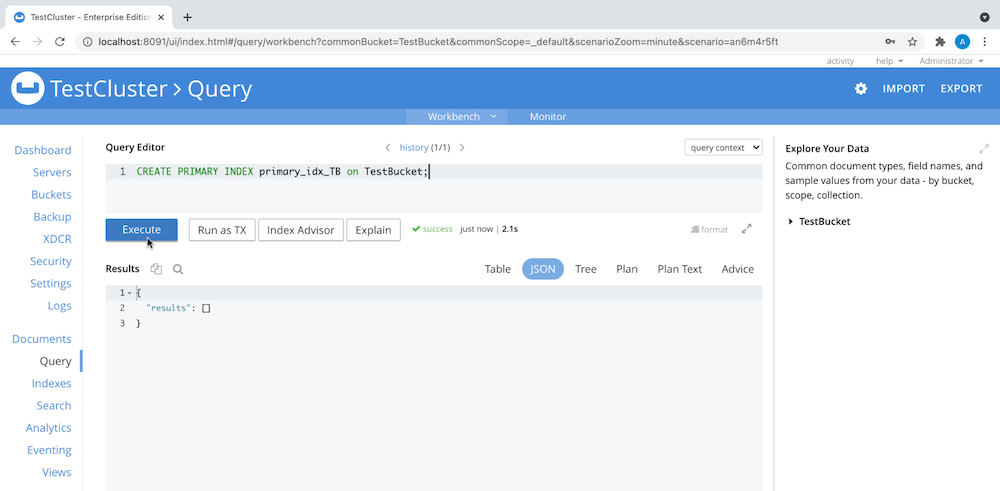
Instalación de Jupyter Notebook
En primer lugar, descargar el ejemplo couchbase-jupyter del repositorio de GitHub de Couchbase Labs. A continuación, sigue estos pasos:
- Instalar Jupyter Notebook a través del sistema de gestión de paquetes de Python (
pip) o Anaconda. - Instale las dependencias de este proyecto mediante
pipdelrequisitosen su shell:
1$ pip instale -r requisitos.txt - Abra Jupyter Notebook desde el shell.
- Crea un nuevo bloc de notas con Python 3, como se muestra aquí:
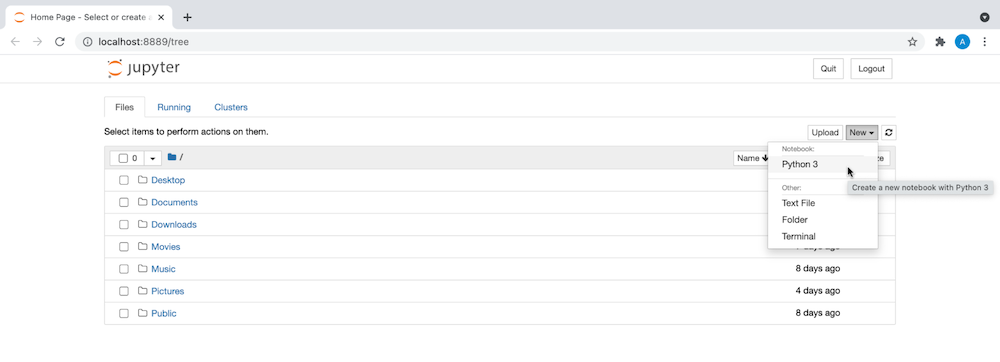
¿Qué es un modelo de regresión lineal?
El modelo de regresión lineal es potente para el análisis predictivo, ya que nos permite determinar la fuerza de variables categóricas o independientes y predecir el efecto de esas variables e identificar tendencias en los datos.
Como se puede deducir del nombre regresión linealla "curva" que utilizamos para ajustar los datos es una recta. La forma más sencilla de la ecuación de regresión es y = mx + cdonde y representa la variable objetivo, x representa una única variable categórica y m y c son constantes. En nuestro ejemplo utilizaremos una ecuación de regresión lineal simple.
Las variables categóricas de nuestro ejemplo son TV, Radio y Periódico. La variable objetivo es Ventas.
Entrenamiento de nuestro modelo de regresión lineal
- En el nuevo Jupyter Notebook, utiliza el código que se muestra a continuación para conectarte al servidor Couchbase. Utilice su nombre de usuario y contraseña, por supuesto, en lugar de
Administradory123456.

- Importa las librerías necesarias, mostradas en la captura de pantalla aquí. Si estas librerías no están presentes en tu entorno, descarga las últimas versiones de estas librerías al entorno correcto usando el gestor de paquetes de Python,
pip.

- Utilización de la
SELECCIONEse obtienen los datos de su cubo de datos en un marco de datos de pandas:

- Puede ver el contenido de su marco de datos pandas utilizando la función
describir()como se muestra aquí:
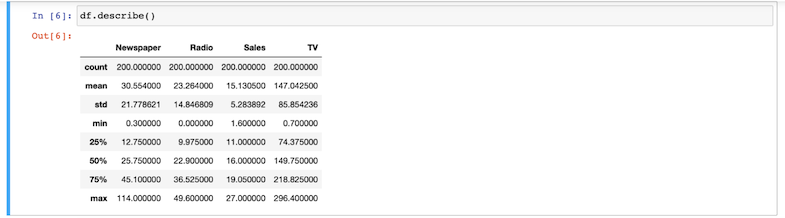
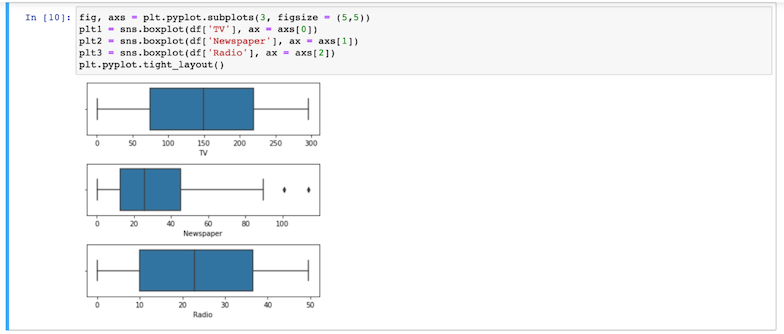
- Cree gráficos de caja correspondientes a los valores de cada variable categórica para detectar valores atípicos:
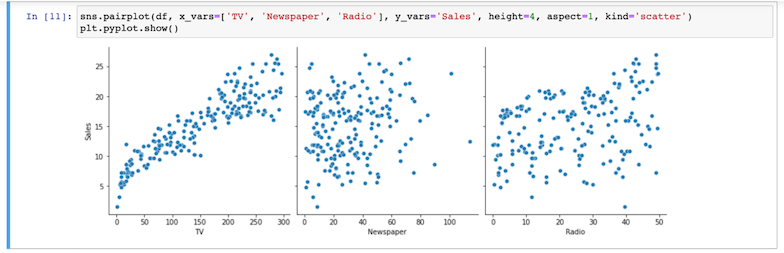
- Cree gráficos de dispersión para cada variable categórica frente a la variable objetivo para determinar el grado de correlación.
Observe queTVparece tener el mayor grado de correlación.
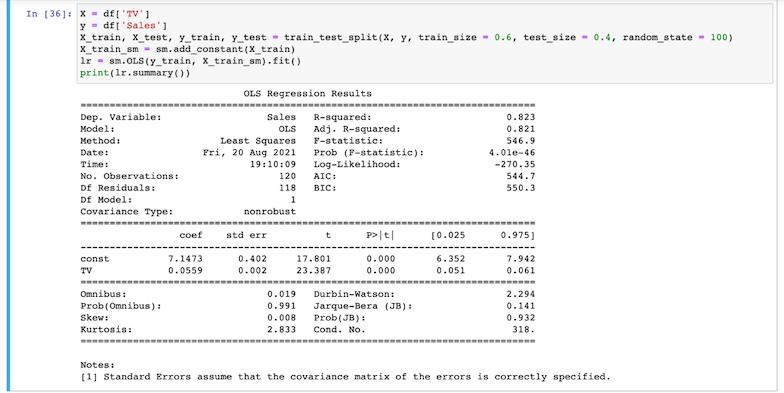
- Divida el conjunto de datos, utilizando 60% del mismo para el entrenamiento y los 40% restantes para las pruebas. Ahora podemos determinar el valor de los coeficientes en la ecuación de regresión, cuando la variable categórica es
TVy la variable objetivo esVentasutilizando el Método de mínimos cuadrados ordinarios.
- Ahora entrena el modelo usando el código que ves aquí:
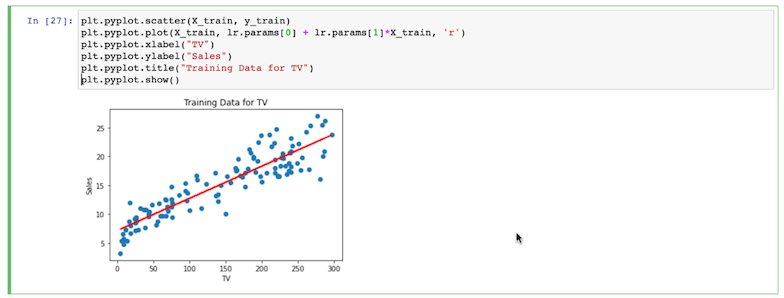
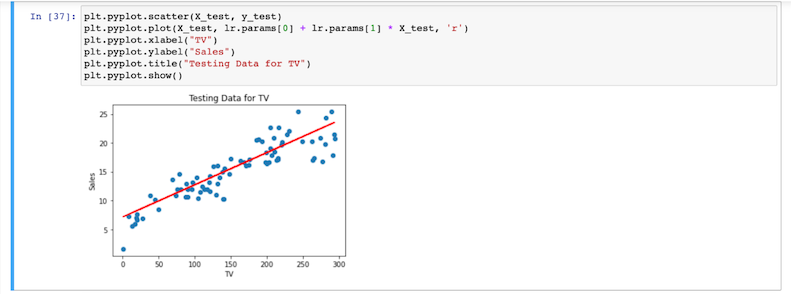
- A continuación, sustituye
pruebaparatrenpara utilizar el modelo para predecir los valores del conjunto de prueba, así:
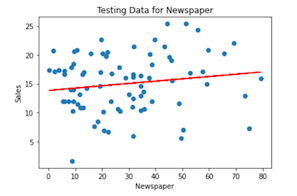
Utilizando el mismo enfoque, podemos entrenar y probar un modelo con las variables categóricas Radio y Periódicotambién:

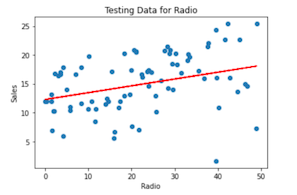
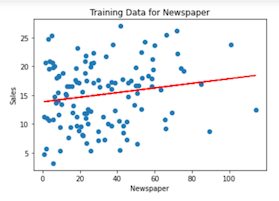
Más allá con Machine Learning y Couchbase
Ahora que ya te has mojado los pies conectando Servidor Couchbase a Jupyter Notebook y ha explorado el concepto de aprendizaje automático de la regresión lineal, amplíe sus conocimientos con estas entradas sobre cómo utilizar Couchbase como almacén de modelos de aprendizaje automático y Obtención de información basada en IA mediante Couchbase.
