En Couchbase, la latencia y el rendimiento se ven afectados significativamente por la replicación de datos.
Existen diferentes tipos de modelos de replicación de datos, principalmente maestro-esclavo (Couchbase, MongoDB, Espresso), maestro-maestro (BDR para PostgreSQL, GoldenGate para Oracle) y sin maestro (Dynamo, Cassandra). En este artículo solo se analiza la replicación maestro-esclavo en almacenes de clave-valor (KV).
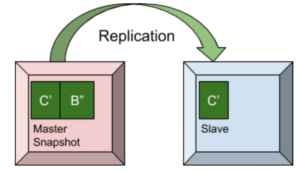
En el modelo de replicación maestro-esclavo, hay un maestro para una única partición de datos y una o más réplicas, que son esencialmente esclavos y siguen los datos de la partición maestra. Las aplicaciones cliente envían los valores clave al maestro y, posteriormente, los valores clave se envían a las réplicas desde el maestro.
Este artículo comienza con algunos conceptos como ordenación, números de secuencia monotónicamente crecientes, instantáneas, MVCC utilizando sólo escrituras append y compactación. A continuación, el artículo explica cómo puede realizarse la replicación maestro-esclavo con (1) Instantáneas Delta o con (2) Punto en el tiempo snapshots, las ventajas y desventajas entre ellas y cuándo es mejor utilizar una u otra. Por último, el artículo analiza brevemente cómo Couchbase, una popular plataforma de Big Data, las utiliza para la replicación de datos.
Particionar los datos, asignar las particiones a los nodos físicos, detectar y manejar los fallos de los nodos, reconciliar ramas divergentes de datos y muchas cosas más son importantes para potenciar un almacén KV distribuido. Este artículo no discute ninguno de ellos, sino que sólo discute la replicación maestro-esclavo de una única partición de datos - incluyendo, específicamente, Couchbase y la replicación.
Fondo
Replicación ingenua
Una forma de replicar datos es obtener una copia completa del origen siempre que queramos una copia. Aunque esto es muy sencillo de implementar, no es de gran utilidad en bases de datos OLTP o en almacenes KV con carga de trabajo en tiempo real donde los datos de origen siguen recibiendo nuevas actualizaciones, ya que las copias de réplica no pueden obtener esas actualizaciones en tiempo real.
La resumibilidad, enviar sólo los cambios (delta), es una característica importante para cualquier protocolo de replicación que a menudo tenga que tratar con grandes cantidades de datos. Pero eso tiene el coste de la complejidad adicional de la necesidad de ordenación e instantáneas que analizamos en las secciones siguientes.
Ordenar con números de secuencia
El orden es importante porque permite a las aplicaciones razonar sobre la causalidad de los datos o, en otras palabras, permite a las aplicaciones saber si una operación ocurrió antes o después de otra operación. En los almacenes KV, el orden se utiliza para identificar el último valor de una clave determinada en el almacén y también para indicar el orden en que el almacén recibe las claves. Los números de secuencia monotónicamente crecientes son una forma de obtener el "orden" de los valores-clave en el almacén. Cada par clave-valor del almacén tiene asociado un número de secuencia único que aumenta monotónicamente a medida que el almacén recibe nuevos valores clave.
| OPERACIÓN | CLAVE | VALOR | NÚMERO DE SECUENCIA |
| INSERTAR | K1 | V1 | SEQ1 |
| INSERTAR | K2 | V2 | SEQ2 |
| ACTUALIZACIÓN | K1 | V1' | SEQ3 |
| INSERTAR | K3 | V3 | SEQ4 |
En el ejemplo anterior, K2-V2 se recibe en el almacén después de K1-V1; K1-V1' se recibe en el almacén después de K2-V2 y así sucesivamente. Por lo tanto, SEQ4 > SEQ3 > SEQ2 > SEQ1. Si el almacén es sólo append, con la ayuda de SEQ3 > SEQ1 podemos identificar que el (último) valor de K1 es V1' y no V1.
El uso de números de secuencia monotónicamente crecientes se da sobre todo en las instantáneas puntuales, de las que hablaremos más adelante.
Instantáneas
En el sentido más básico, una instantánea (una instantánea completa) es una vista inmutable del almacén de KV en una instancia. También es una vista consistente del almacén KV en esa instancia.
Definimos un "Instantánea de Delta" como una copia inmutable de los pares clave-valor recibidos por el almacén KV en una duración de tiempo. La llamamos instantánea delta porque la instantánea no contiene todos los valores clave del almacén y sólo contiene los valores clave que se reciben después de que se forme una instantánea delta inmediatamente anterior, hasta el momento en que se crea la instantánea actual. Las sucesivas instantáneas delta ofrecen una visión coherente del almacén KV hasta un punto determinado, es decir, hasta el momento en que se crea la última instantánea.
MVCC utilizando sólo escrituras de apéndice
El control de concurrencia de múltiples versiones (MVCC) es un método de control de concurrencia utilizado en los almacenes KV para permitir lectores y escritores concurrentes. La forma más sencilla de gestionar la concurrencia sería utilizar bloqueos de lectura-escritura. Pero en los almacenes KV distribuidos que manejan grandes cantidades de datos, MVCC ha demostrado ser extremadamente útil sobre el bloqueo. MVCC ayuda a lograr mayores rendimientos y menores latencias para lecturas y escrituras.
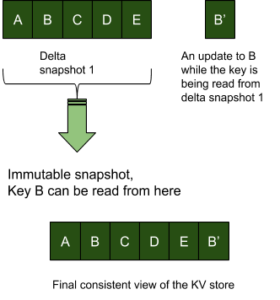
La MVCC se consigue utilizando snapshots y escrituras append only en el almacén KV. En el ejemplo siguiente, supongamos que un escritor actualiza la "clave B" mientras hay lectores en la instantánea 1 delta. El control de concurrencia con bloqueo requeriría que la entidad mutante esperara hasta que se completara la replicación de toda la instantánea. Sin embargo, con un enfoque MVCC de sólo apéndice, la escritura en la clave B puede continuar incluso mientras se lee la instantánea actual.
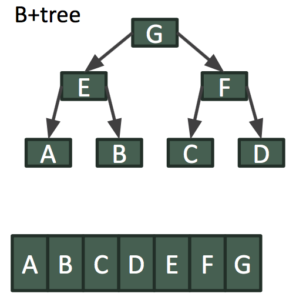
Para los lectores más avanzados, MVCC también se puede hacer cuando el almacén KV utiliza estructuras de datos más complicadas para almacenar datos. El siguiente ejemplo muestra cómo se puede conseguir MVCC en un árbol B+Tree de sólo anexión. Digamos que la 'clave B' es actualizada por un escritor mientras hay lectores en la instantánea delta actual.
Con un enfoque MVCC de sólo anexión, la escritura en la "clave B" y la rama asociada en el árbol B+ puede continuar incluso mientras se lee la instantánea actual, como se muestra a continuación.
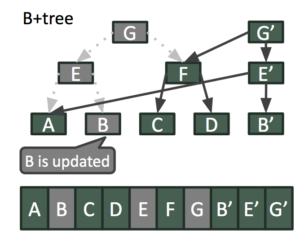
Las dos instantáneas superpuestas representadas por las raíces B+Tree de G y G' representan vistas coherentes del almacén KV en dos momentos del tiempo.
Compactación
Dado que las instantáneas son inmutables, las actualizaciones de las claves sólo se añaden al final del almacén de KV, por lo que el uso de memoria del almacén acabará siendo mucho mayor que la memoria necesaria para los valores clave activos. Por ello, el almacén KV debe fusionar periódicamente las instantáneas más antiguas y deshacerse de los valores clave duplicados o obsoletos mediante una tarea en segundo plano denominada compactación. La compactación reduce la memoria utilizada por el almacén de KV.
Los disparadores para la compactación pueden estar en un umbral de memoria o un intervalo de tiempo fijo o una combinación de ambos.
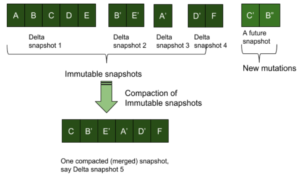
Instantáneas Delta
Los almacenes KV pueden replicarse enviando una secuencia de instantáneas delta sucesivas. Como se ha explicado anteriormente, en un enfoque de escritura de sólo anexión, los nuevos valores clave y las actualizaciones sólo se anexan al almacén. Tras recibir un lote de elementos, se crea una instantánea inmutable que está lista para ser enviada a los nodos réplica. Los valores clave recibidos por el almacén tras la creación de esta instantánea se añaden al almacén y formarán parte de la siguiente instantánea. Los clientes de replicación recogen estas instantáneas delta inmutables una tras otra y obtienen una vista del almacén que es coherente con la fuente. Tenga en cuenta que esto no necesita números de secuencia para cada par de KV, pero necesitará identificar el orden de las instantáneas delta.
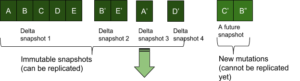
Una desventaja de este enfoque es que el lado de origen del almacén KV puede compactar varias instantáneas delta inmutables en una sola instantánea. Ahora bien, si la compactación se produce antes de que un cliente de replicación haya recibido la última instantánea compactada, el cliente tendrá que recibir la instantánea totalmente compactada desde el principio de la instantánea. Digamos que hay 5 instantáneas delta inmutables snp1, snp2, snp3, snp4 y el cliente ha recibido hasta snp3; entonces se ejecuta la compactación y las 4 instantáneas del lado origen se compactan en una única instantánea snp1'. Ahora el cliente no puede reanudar desde snp3, tendrá que deshacer las instantáneas que recibió antes (hasta snp3) y tendrá que recibir snp1' por completo.
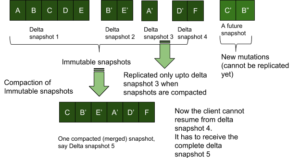
Podemos hacer una optimización teniendo un número de secuencia (monotónicamente creciente) en cada par clave-valor y luego sólo enviar por red los números de secuencia que sean mayores que el snap_end de snp3. Sin embargo, el almacén KV todavía tendrá que leer desde el principio de snp1' para llegar al snap_end de snp3.
Otro inconveniente de este enfoque es que los últimos pares clave-valor no pueden replicarse hasta que se forman en una instantánea delta inmutable. Esto aumenta la latencia del envío de las claves a las réplicas.
Las instantáneas Delta sirven para replicar lotes de elementos bastante grandes, es decir, alto rendimiento, pero también alta latencia.
Instantáneas puntuales
Las instantáneas puntuales son las instantáneas que se crean sobre la marcha. Es decir, mientras se escriben nuevos datos y actualizaciones en el almacén de KV, el almacén crea la instantánea si un cliente de replicación solicita datos. Esto implica que, para recibir los valores clave más recientes, las réplicas no necesitan esperar a que se cree una instantánea en el origen.
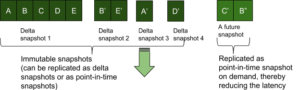
Las instantáneas puntuales pueden crearse muy rápidamente (baja latencia) en un almacén KV de sólo anexión y son las más adecuadas para la replicación de elementos en memoria y en estado estable. Por estado estable entendemos que todos los clientes de replicación casi han alcanzado a la fuente.
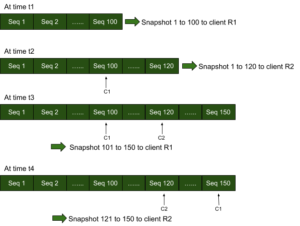
Este modelo requiere que cada par clave-valor tenga un número de secuencia monotónicamente creciente. Una instantánea puntual se define mediante la tupla {start_seqno, end_seqno}.
Supongamos que el origen tiene pares clave-valor del número de secuencia 0 al 100 y que un cliente de replicación R1 realiza una solicitud de copia de datos. Los pares clave-valor del número de secuencia 0 a 100 se envían como una instantánea (instantánea puntual) a R1 y se marca en el almacén un cursor C1 que corresponde al cliente R1. En un momento posterior, digamos que el almacén ha añadido 20 pares KV más y tiene el número de secuencia más alto, 120. Si otro cliente R2 solicita datos, los pares clave-valor del número de secuencia 0 a 120 se envían como una instantánea a R2 y se marca en el almacén un cursor C2 que corresponde al cliente R2. Cuando se añaden más datos al almacén, digamos hasta el número de secuencia 150, el cliente R1 puede obtener hasta 150 en una instantánea sucesiva de 101 a 150 y el cliente R2 en una instantánea sucesiva de 121 a 150. Nótese que los cursores C1 y C2 son importantes para volver a empezar rápidamente desde donde los clientes R1 y R2 habían dejado antes. A medida que se mueven los cursores, los pares clave-valor con número de secuencia inferior al número de secuencia en el que está marcado cualquier cursor pueden compactarse sin ninguna contención de lectura-escritura o eliminarse de la memoria (en caso de replicación de datos en memoria en un almacén KV persistente).
Las instantáneas puntuales son buenas para la replicación en estado estable, ya que los clientes de replicación obtienen sus propias instantáneas que se crean bajo demanda y, por lo tanto, evitan tener que esperar a que se cree una instantánea. Por lo tanto, los clientes pueden ponerse al día con la fuente muy rápidamente con los últimos pares clave-valor enviados tan pronto como sea posible. Además, los clientes no tienen que volver a empezar si se produce una compactación entre sus sucesivas instantáneas y el origen no necesita mantener instantáneas delta para que todos los clientes las lean.
Los clientes lentos y los clientes retrasados (diferidos) no funcionan bien con las instantáneas puntuales. Como no podemos compactar sin contención de lectura-escritura o expulsar de la memoria los pares clave-valor con un número de secuencia inferior al número de secuencia del cursor con el menor número de secuencia, un cliente lento puede ralentizar la velocidad de creación de instantáneas puntuales para todos los demás clientes y también aumentar el uso de memoria.
Las instantáneas puntuales sirven para replicar rápidamente los elementos más recientes, es decir, baja latencia, pero también bajo rendimiento.
Utilización de instantáneas delta y puntuales
Ambos alto rendimiento y baja latencia puede lograrse cambiando dinámicamente entre el modo de instantánea delta o el modo de instantánea puntual según sea necesario durante la replicación de una partición.
Cuando un cliente de replicación se conecta a una fuente, inicialmente obtiene instantáneas delta a un alto rendimiento para alcanzar pronto a la fuente y llegar así al estado estacionario. A continuación, la replicación pasa al modo de instantáneas puntuales, con lo que el cliente sigue recibiendo los elementos más recientes con una latencia muy baja. Si por alguna razón un cliente se vuelve lento, la replicación vuelve al modo de instantánea delta incremental para reducir cualquier aumento no saludable del uso de memoria. Y una vez que el cliente lento se pone al día con la fuente y alcanza de nuevo el estado estable, la replicación cambia al modo de instantánea puntual.
Otras consideraciones de diseño
Purga de borrados
En el modo de sólo anexar, los borrados se anexan siempre al final del almacén. En la replicación mediante instantáneas, es esencial anexar los borrados para reflejar que una clave se ha borrado en todas las réplicas. Sin embargo, no podemos mantener los borrados para siempre, ya que suponen una sobrecarga para la memoria de almacenamiento. Por lo tanto, con el tiempo, los borrados deben ser eliminados.
Pero la purga de borrados puede tener efectos en clientes de replicación lentos y a veces puede romper la replicación incremental, especialmente en clientes que no han alcanzado la instantánea en la que se ha purgado un borrado. Estos clientes pueden tener que reconstruir todas las instantáneas desde el principio para obtener una copia que sea coherente con la fuente.
Ramificación
Los fallos graves pueden dar lugar a diferentes ramas de datos en las réplicas. Estas ramas pueden reconciliarse y todas las réplicas pueden tener finalmente las mismas copias consistentes. Existen protocolos y algoritmos para hacer esto y se cruzan muy bien con el mundo de las instantáneas. Sin embargo, los mantendremos fuera del alcance de este artículo. Este artículo sólo discute esquemas de replicación e instantáneas cuando no hay fallos graves.
Deduplicación
La deduplicación es la eliminación de versiones duplicadas de la misma clave en una instantánea y la retención de sólo la versión final de la clave en esa instantánea. El objetivo principal de la deduplicación es reducir el uso de memoria.
La deduplicación se realiza en las instantáneas delta durante la compactación. En las instantáneas puntuales, la deduplicación puede realizarse durante la compactación y también mientras se añaden elementos. La deduplicación junto con las instantáneas puntuales crea una complejidad adicional, como la imposibilidad de escribir cuando se está leyendo una instantánea puntual y la no resumibilidad cuando cambia el origen de un cliente en caso de fallo. Como ya se ha mencionado, la discusión de estos escenarios de fallo queda fuera del alcance de este artículo.
Uso en Couchbase
En Couchbase, la latencia y el rendimiento se benefician de la replicación que elige dinámicamente instantáneas delta del disco o instantáneas puntuales de la memoria. Las instantáneas delta del disco también utilizan números de secuencia monotónicamente crecientes para reanudar desde donde los clientes habían dejado para reducir el tráfico de red.
Couchbase también realiza deduplicación, detección y manejo de fallos de nodo, reconciliación de ramas divergentes de datos, proporcionando clientes de datos que son más sofisticados que los simples clientes de replicación (indexación, búsqueda de texto completo), almacenamiento en caché, particionamiento y muchos más son importantes para proporcionar una plataforma de datos altamente disponible, de alto rendimiento y que prioriza la memoria.
Conclusión
En la replicación maestro-esclavo, las "instantáneas delta" son adecuadas para replicar un lote de elementos y, por tanto, ofrecen un alto rendimiento. Las "instantáneas puntuales" son adecuadas para la replicación en estado estable, por lo que proporcionan una baja latencia. Utilizando una u otra, según lo requiera la situación, podemos obtener una replicación maestro-esclavo de alto rendimiento y baja latencia.
Autor

Sundar Sridharan, Ingeniero Superior de Software