Aaron Benton es un arquitecto experimentado especializado en soluciones creativas para desarrollar aplicaciones móviles innovadoras. Tiene más de 10 años de experiencia en desarrollo full stack, incluyendo ColdFusion, SQL, NoSQL, JavaScript, HTML y CSS. Aaron es actualmente Arquitecto de Aplicaciones para Shop.com en Greensboro, Carolina del Norte y es un Campeón de la comunidad Couchbase.

FakeIt Serie 2 de 5: Datos compartidos y dependencias
En FakeIt Serie 1 de 5: Generación de datos falsos aprendimos que FakeIt puede generar una gran cantidad de datos aleatorios basados en un único archivo YAML y enviar los resultados a varios formatos y destinos, incluyendo Couchbase Server. Hoy vamos a explorar lo que hace FakeIt verdaderamente único y poderoso en el mundo de la generación de datos.
Hay montones de generadores de datos aleatorios disponibles, un simple Búsqueda en Google le dará más que suficiente donde elegir. Sin embargo, casi todos ellos tienen el mismo defecto frustrante: sólo pueden trabajar con un único modelo. Rara vez como desarrolladores tenemos el lujo de tratar con un solo modelo, más a menudo que no estamos desarrollando contra múltiples modelos para nuestros proyectos. Aquí es donde FakeIt se destaca, que permite múltiples modelos y los modelos que tienen dependencias.
Echemos un vistazo a los posibles modelos que tendremos dentro de nuestra aplicación de comercio electrónico:
- Usuarios
- Productos
- Carrito
- Pedidos
- Reseñas
Usuarios, el primer modelo que definimos no tiene dependencias y lo mismo puede decirse del modelo Productos, que definiremos a continuación. Sin embargo, sería lógico decir que nuestro modelo de Pedidos dependería tanto del modelo de Usuarios como del de Productos. Si realmente queremos datos de prueba, los documentos creados por nuestro modelo Pedidos deberían ser los datos aleatorios reales generados a partir de los modelos Usuarios y Productos.
Productos Modelo
Antes de ver como funcionan las dependencias de modelos en FakeIt definamos como va a ser nuestro modelo de Productos.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 |
name: Products type: object key: _id properties: _id: type: string description: The document id data: post_build: `product_${this.product_id}` doc_type: type: string description: The document type data: value: product product_id: type: string description: Unique identifier representing a specific product data: build: faker.random.uuid() price: type: double description: The product price data: build: chance.floating({ min: 0, max: 150, fixed: 2 }) sale_price: type: double description: The product price data: post_build: | let sale_price = 0; if (chance.bool({ likelihood: 30 })) { sale_price = chance.floating({ min: 0, max: this.price * chance.floating({ min: 0, max: 0.99, fixed: 2 }), fixed: 2 }); } return sale_price; display_name: type: string description: Display name of product. data: build: faker.commerce.productName() short_description: type: string description: Description of product. data: build: faker.lorem.paragraphs(1) long_description: type: string description: Description of product. data: build: faker.lorem.paragraphs(5) keywords: type: array description: An array of keywords items: type: string data: min: 0 max: 10 build: faker.random.word() availability: type: string description: The availability status of the product data: build: | let availability = 'In-Stock'; if (chance.bool({ likelihood: 40 })) { availability = faker.random.arrayElement([ 'Preorder', 'Out of Stock', 'Discontinued' ]); } return availability; availability_date: type: integer description: An epoch time of when the product is available data: build: faker.date.recent() post_build: new Date(this.availability_date).getTime() product_slug: type: string description: The URL friendly version of the product name data: post_build: faker.helpers.slugify(this.display_name).toLowerCase() category: type: string description: Category for the Product data: build: faker.commerce.department() category_slug: type: string description: The URL friendly version of the category name data: post_build: faker.helpers.slugify(this.category).toLowerCase() image: type: string description: Image URL representing the product. data: build: faker.image.image() alternate_images: type: array description: An array of alternate images for the product items: type: string data: min: 0 max: 4 build: faker.image.image() |
Este modelo es un poco más complejo que nuestro anterior modelo de Usuarios. Examinemos algunas de estas propiedades con más detalle:
- _id: Este valor se establece después de que todas las propiedades del documento hayan sido construidas y está disponible para la función de post-construcción. El contexto es el del documento actual que se está generando.
- precio_venta: Esto mediante la definición de una probabilidad 30% de un precio de venta y si hay un precio de venta de garantizar que el valor es inferior a la de la propiedad de precio
- palabras clave: Es un array. Esto se define de manera similar a Swagger, definimos nuestros elementos de matriz y cómo queremos que se construyan utilizando las funciones build / post_build. Adicionalmente, podemos definir valores min y max y FakeIt generará un número aleatorio de elementos del array entre estos valores. También hay una propiedad fija que se puede utilizar para generar un número determinado de elementos de la matriz.
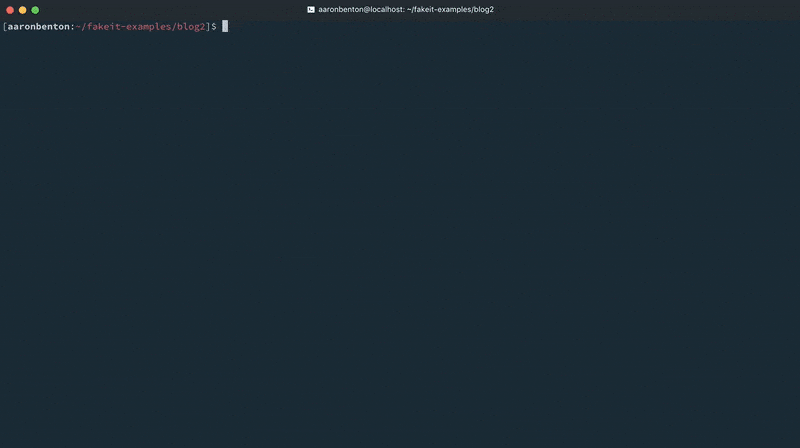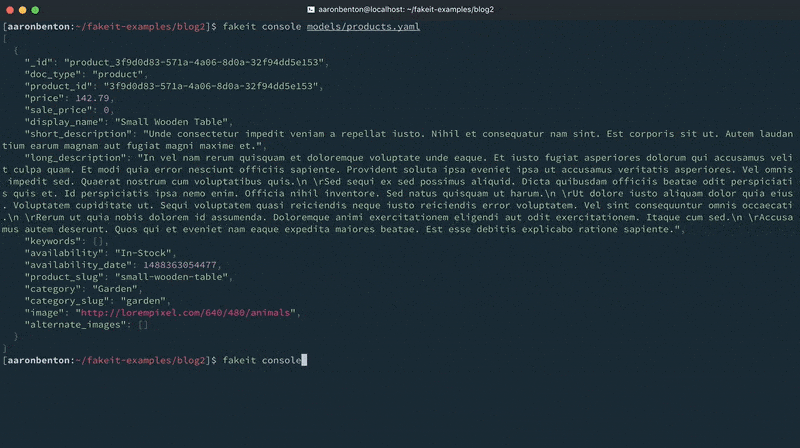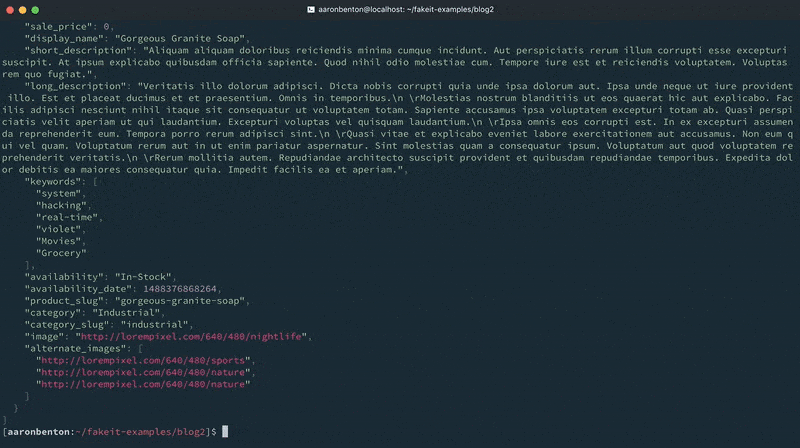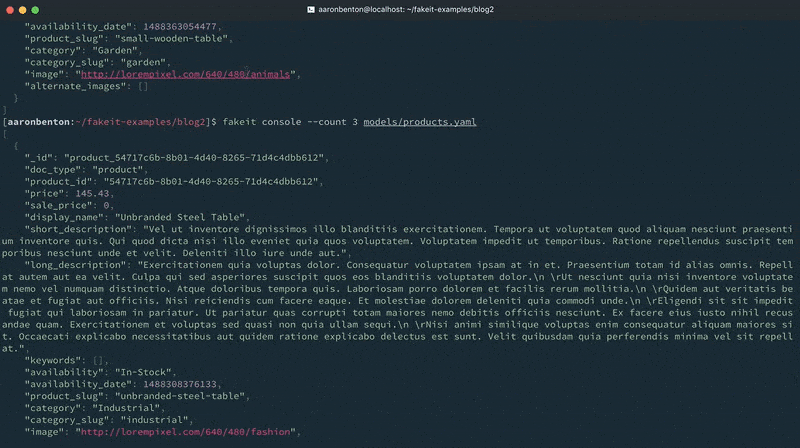
Ahora que hemos construido nuestro modelo de Productos generemos algunos datos aleatorios y enviémoslos a la consola para ver cómo se ven usando el comando:
|
1 |
fakeit console models/products.yaml |
Modelo de pedidos
Para nuestro proyecto ya hemos definido los siguientes modelos:
- usuarios.yaml
- productos.yaml
Empecemos definiendo un modelo de Órdenes sin propiedades y especificando sus dependencias:
|
1 2 3 4 5 6 7 8 |
name: Orders type: object key: _id data: dependencies: - products.yaml - users.yaml properties: |
Hemos definido dos dependencias para nuestro modelo de Pedidos, y las hemos referenciado por su nombre de fichero. Dado que todos nuestros modelos se almacenan en el mismo directorio no hay razón para especificar la ruta completa. En tiempo de ejecución, FakeIt primero analizará todos los modelos antes de intentar generar documentos, y determinará un orden de ejecución basado en cada una de las dependencias de los modelos (si las hay).
Cada una de las funciones de construcción en un modelo FakeIt es un cuerpo de función, con los siguientes argumentos que se le pasan.
|
1 2 3 |
function (documents, globals, inputs, faker, chance, document_index, require) { return faker.internet.userName(); } |
Una vez establecido el orden de ejecución, cada una de las dependencias se guarda en memoria y se pone a disposición del modelo dependiente a través del argumento documentos. Este argumento es un objeto que contiene una clave para cada modelo cuyo valor es un array de cada documento que se ha generado. Para nuestro ejemplo de la propiedad documents tendrá un aspecto similar a este:
|
1 2 3 4 5 6 7 8 |
{ "Users": [ ... ], "Products": [ ... ] } |
Podemos aprovechar esto para recuperar documentos aleatorios de Producto y Usuario asignando sus propiedades a propiedades dentro de nuestro modelo de Pedidos. Por ejemplo, podemos recuperar un user_id aleatorio de los documentos generados por el modelo Users y asignarlo al user_id del modelo Orders a través de una función build
|
1 2 3 4 5 |
user_id: type: integer description: The user_id that placed the order data: build: faker.random.arrayElement(documents.Users).user_id; |
Definamos cómo será el resto de nuestro modelo de Pedidos:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 |
name: Orders type: object key: _id data: dependencies: - products.yaml - users.yaml properties: _id: type: string description: The document id data: post_build: `order_${this.order_id}` doc_type: type: string description: The document type data: value: "order" order_id: type: integer description: The order_id data: build: document_index + 1 user_id: type: integer description: The user_id that placed the order data: build: faker.random.arrayElement(documents.Users).user_id; order_date: type: integer description: An epoch time of when the order was placed data: build: new Date(faker.date.past()).getTime() order_status: type: string description: The status of the order data: build: faker.random.arrayElement([ 'Pending', 'Processing', 'Cancelled', 'Shipped' ]) billing_name: type: string description: The name of the person the order is to be billed to data: build: `${faker.name.firstName()} ${faker.name.lastName()}` billing_phone: type: string description: The billing phone data: build: faker.phone.phoneNumber().replace(/x[0-9]+$/, '') billing_email: type: string description: The billing email data: build: faker.internet.email() billing_address_1: type: string description: The billing address 1 data: build: `${faker.address.streetAddress()} ${faker.address.streetSuffix()}` billing_address_2: type: string description: The billing address 2 data: build: chance.bool({ likelihood: 50 }) ? faker.address.secondaryAddress() : null billing_locality: type: string description: The billing city data: build: faker.address.city() billing_region: type: string description: The billing region, city, province data: build: faker.address.stateAbbr() billing_postal_code: type: string description: The billing zip code / postal code data: build: faker.address.zipCode() billing_country: type: string description: The billing region, city, province data: value: US shipping_name: type: string description: The name of the person the order is to be billed to data: build: `${faker.name.firstName()} ${faker.name.lastName()}` shipping_address_1: type: string description: The shipping address 1 data: build: `${faker.address.streetAddress()} ${faker.address.streetSuffix()}` shipping_address_2: type: string description: The shipping address 2 data: build: chance.bool({ likelihood: 50 }) ? faker.address.secondaryAddress() : null shipping_locality: type: string description: The shipping city data: build: faker.address.city() shipping_region: type: string description: The shipping region, city, province data: build: faker.address.stateAbbr() shipping_postal_code: type: string description: The shipping zip code / postal code data: build: faker.address.zipCode() shipping_country: type: string description: The shipping region, city, province data: value: US shipping_method: type: string description: The shipping method data: build: faker.random.arrayElement([ 'USPS', 'UPS Standard', 'UPS Ground', 'UPS 2nd Day Air', 'UPS Next Day Air', 'FedEx Ground', 'FedEx 2Day Air', 'FedEx Standard Overnight' ]); shipping_total: type: double description: The shipping total data: build: chance.dollar({ min: 10, max: 50 }).slice(1) tax: type: double description: The tax total data: build: chance.dollar({ min: 2, max: 10 }).slice(1) line_items: type: array description: The products that were ordered items: type: string data: min: 1 max: 5 build: | const random = faker.random.arrayElement(documents.Products); const product = { product_id: random.product_id, display_name: random.display_name, short_description: random.short_description, image: random.image, price: random.sale_price || random.price, qty: faker.random.number({ min: 1, max: 5 }), }; product.sub_total = product.qty * product.price; return product; grand_total: type: double description: The grand total of the order data: post_build: | let total = this.tax + this.shipping_total; for (let i = 0; i < this.line_items.length; i++) { total += this.line_items[i].sub_total; } return chance.dollar({ min: total, max: total }).slice(1); |
Y la salida a la consola utilizando el comando:
|
1 |
fakeit console models/orders.yaml |
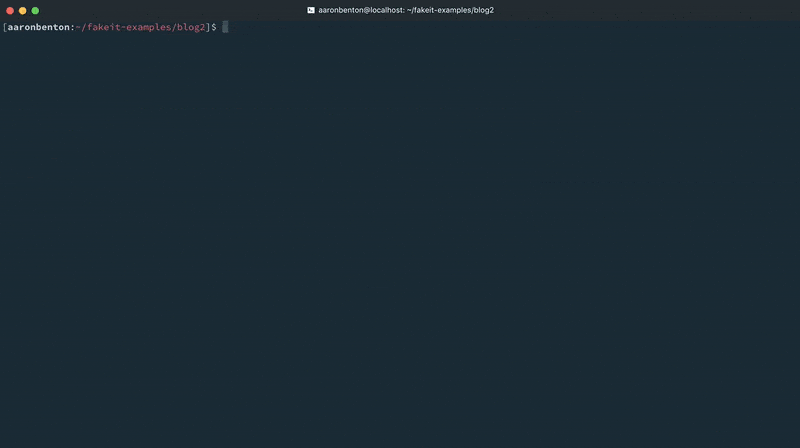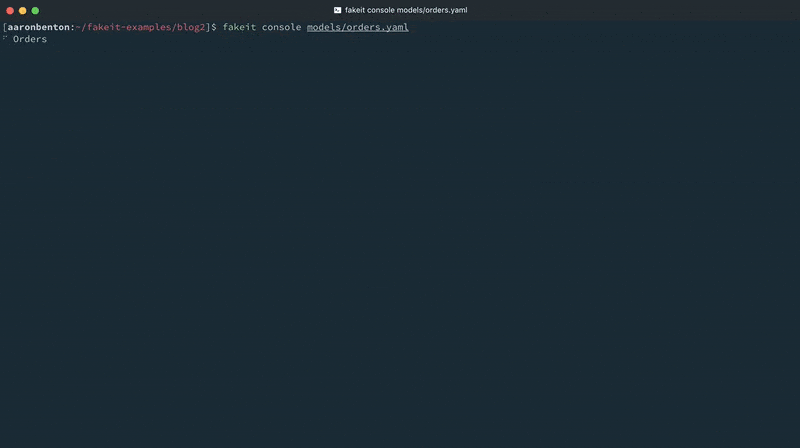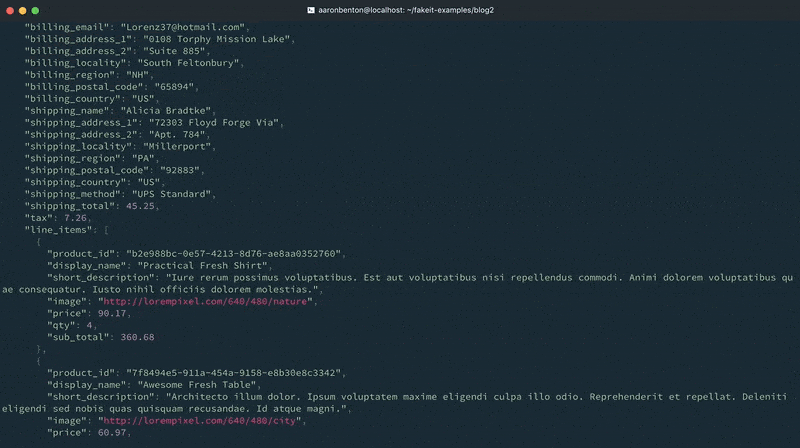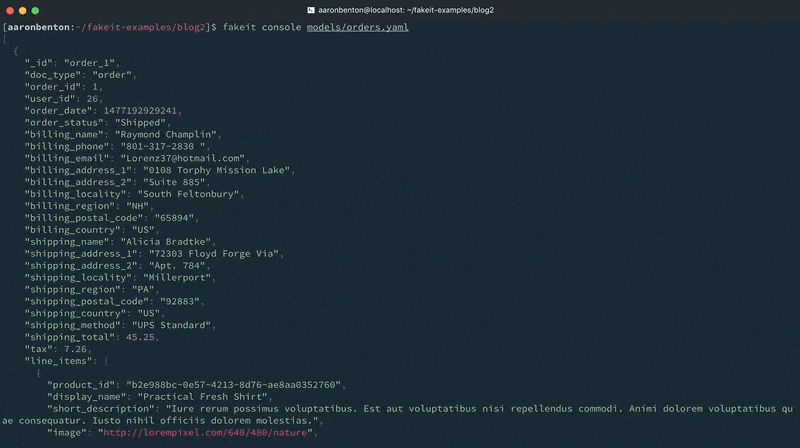
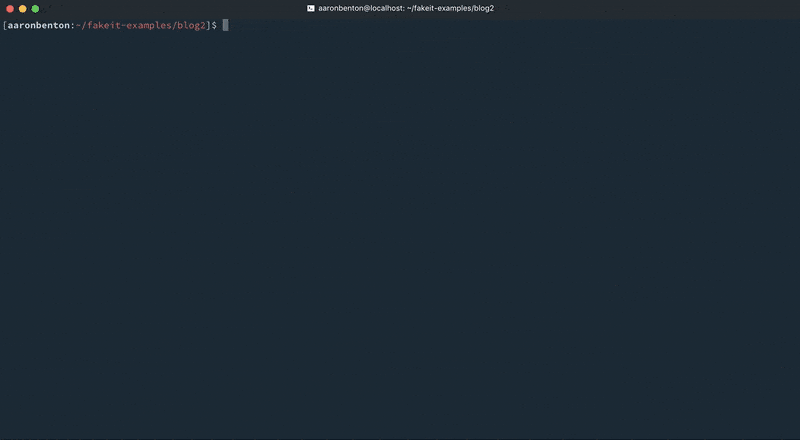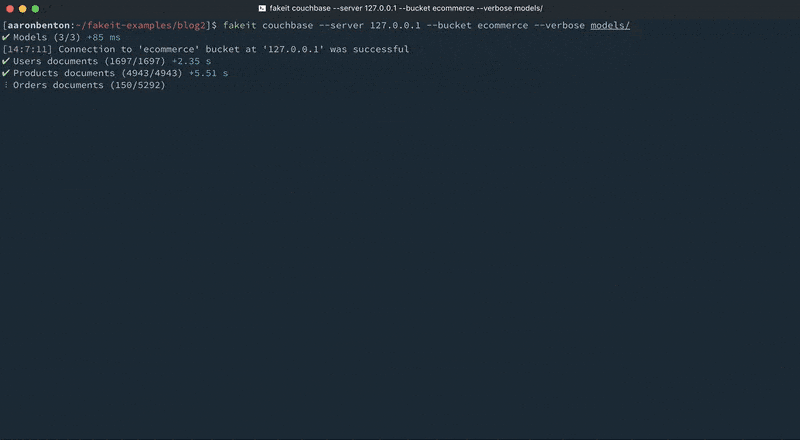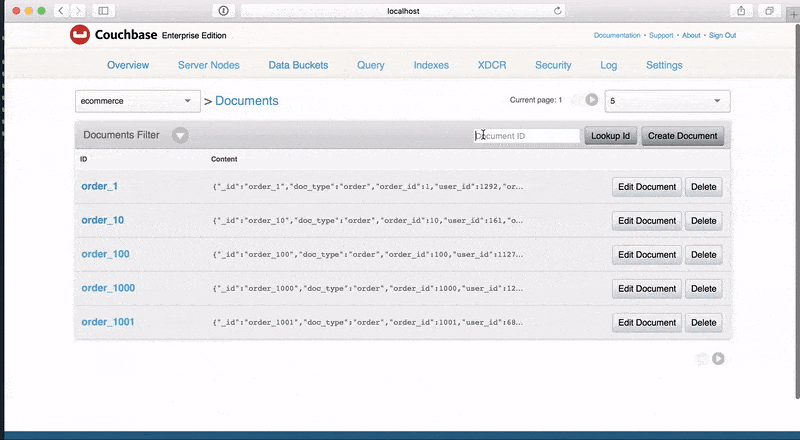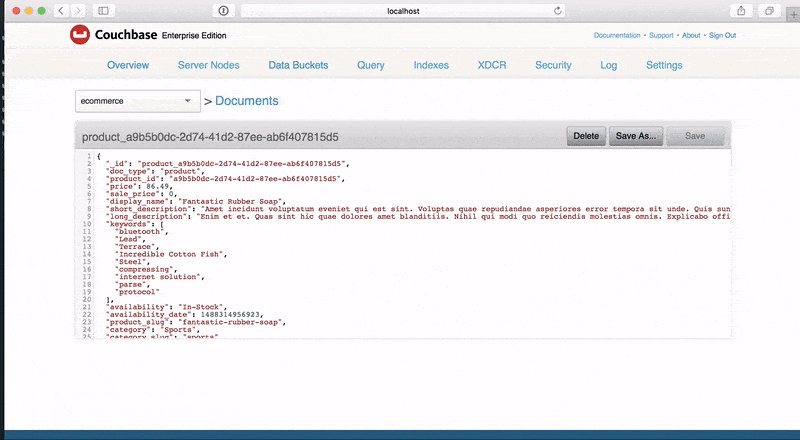
Como se puede ver en la salida de la consola, los documentos se generaron para los modelos Usuarios y Productos, y esos documentos se pusieron a disposición del modelo Pedidos. Sin embargo, se excluyeron de la salida porque todo lo que se pidió que saliera fue el modelo Pedidos.
Ahora que hemos definido 3 modelos con dependencias (Usuarios, Productos y Pedidos), necesitamos ser capaces de generar múltiples documentos para cada uno de ellos y enviarlos a Couchbase Server. Hasta ahora hemos especificado el número de documentos a generar mediante el argumento de línea de comandos -count. Podemos especificar el número de documentos o un rango de documentos utilizando la propiedad data: en la raíz del modelo.
|
1 2 3 4 5 6 7 8 |
users.yaml name: Users type: object key: _id data: min: 1000 max: 2000 |
|
1 2 3 4 5 6 7 8 |
products.yaml name: Products type: object key: _id data: min: 4000 max: 5000 |
|
1 2 3 4 5 6 7 8 9 10 11 |
orders.yaml name: Orders type: object key: _id data: dependencies: - products.yaml - users.yaml min: 5000 max: 6000 |
Ahora podemos generar conjuntos aleatorios de modelos de documentos relacionados y enviar esos documentos directamente a Couchbase Server usando el comando:
|
1 |
fakeit couchbase --server 127.0.0.1 --bucket ecommerce --verbose models/ |
Conclusión
Hemos visto a través de tres sencillos modelos YAML de FakeIt cómo podemos crear dependencias entre modelos permitiendo que los datos generados aleatoriamente se relacionen entre modelos y se transmitan a Couchbase Server. También hemos visto cómo podemos especificar el número de documentos a generar por modelo usando la propiedad data: en la raíz de un modelo.
Estos modelos pueden ser almacenados en el repositorio de tus proyectos, ocupando muy poco espacio y permitiendo a tus desarrolladores generar las mismas estructuras de datos con datos completamente diferentes. Otra ventaja de poder generar documentos a través de relaciones multimodelo es explorar diferentes modelos de documentos y ver cómo se comportan con varias consultas N1QL.
A continuación
- FakeIt Series 3 de 5: Modelos Lean a través de definiciones
- FakeIt Series 4 de 5: Trabajar con datos existentes
- FakeIt Series 5 de 5: Desarrollo móvil rápido con Sync-Gateway
Anterior
- FakeIt Serie 1 de 5: Generación de datos falsos
 Este post forma parte del Programa de Escritura de la Comunidad Couchbase
Este post forma parte del Programa de Escritura de la Comunidad Couchbase
[...] nuestro post anterior FakeIt Serie 2 de 5: Datos Compartidos y Dependencias vimos cómo crear dependencias multi-modelo con FakeIt. Hoy [...]
[...] hasta ahora en nuestra serie FakeIt hemos visto cómo podemos Generar Datos Falsos, Compartir Datos y Dependencias, y utilizar Definiciones para modelos más pequeños. Hoy vamos a ver la última característica importante de [...]