Si preguntara a cinco a la gente qué es el "edge computing", seguramente obtendría cinco respuestas diferentes. Y lo más confuso es que probablemente todas tendrían razón.
El edge computing es una arquitectura estratégica que está ganando popularidad, pero sus diferentes permutaciones y sus innumerables casos de uso hacen que sea difícil de precisar.
¿La computación de borde es móvil, IoT o entornos inteligentes? ¿Tiene que ver con la nube, con la tecnología local o con los dispositivos? ¿Se trata de computación, redes o 5G? ¿Se aplica a los robots de una fábrica, a los monitores de un quirófano o a los coches sin conductor?
Edge computing es todo esto y mucho más.
En este artículo, te explicaré los conceptos esenciales de la computación perimetral y lo que necesitas para construir con éxito tu propia arquitectura perimetral. Pero (¡alerta de spoiler!) aprovechar las ventajas del edge computing se reduce básicamente a una cosa: los datos: dónde y cómo los procesas, y cómo los haces fluir hacia y desde el edge.
En primer lugar, definamos computación periférica.
¿Qué es la arquitectura Edge Computing?
Wikipedia describe la computación de borde como:
La computación de borde es un paradigma informático distribuido que acerca la computación y el almacenamiento de datos a las fuentes de los mismos. Se espera así mejorar los tiempos de respuesta y ahorrar ancho de banda. El término se refiere a una arquitectura más que a una tecnología específica.
Edge computing consiste en almacenar y procesar datos más cerca de los usuarios y las aplicaciones que los consumen. Al final, reduce la latencia y aísla de las interrupciones de Internet. Las arquitecturas Edge Computing prometen impulsar innovaciones como
-
- Hogares conectados
- Vehículos autónomos
- Cirugía robótica
- Juegos avanzados en tiempo real
Edge computing es una arquitectura alternativa a la computación en nube para aplicaciones que requieren alta velocidad y disponibilidad. Esto se debe a que las aplicaciones que dependen exclusivamente de la nube para almacenar y procesar datos se vuelven dependientes de la conectividad a Internet y, por tanto, están sujetas a su falta de fiabilidad inherente. Cuando Internet se ralentiza o deja de estar disponible, toda la aplicación se ralentiza o falla a su vez.
La computación de borde sortea las dependencias de Internet ubicando los datos lo más cerca posible de donde se producen y consumen, lo que acelera las aplicaciones y mejora su disponibilidad.
Un ejemplo real de Edge Computing
Veamos un ejemplo concreto.
Imaginemos una plataforma petrolífera en medio del Mar del Norte. Los operarios recogen datos de sensores por toda la plataforma como parte de una rutina diaria, midiendo cosas como la presión, la temperatura, la altura de las olas y otros factores que afectan a la capacidad operativa. Este tipo de datos llegan rápido, cambian a menudo y requieren una respuesta en tiempo real.
Supongamos que los datos de las plataformas petrolíferas se almacenan y procesan en un centro de datos en la nube. Los operadores de las plataformas tendrían que enviar sus datos por internet -y en el Mar del Norte eso significa vía satélite, que es lenta y cara- solo para evaluar sus mediciones.
Ahora imaginemos que un sensor de un componente crítico de la plataforma empieza a detectar indicios de un posible fallo, una posible avería que podría provocar un peligroso giro de los acontecimientos. Lleva demasiado tiempo recopilar datos sobre el componente, enviarlos a la nube para su procesamiento y esperar a que se recomiende una actuación. ¿Y si la conexión se ralentiza o falla aunque sólo sea un poco? Se pierde un tiempo crítico. Cuando los operadores de la plataforma reciben una respuesta de la nube, puede ser demasiado tarde.
Cuando los segundos cuentan y la diferencia entre tiempo de actividad y tiempo de inactividad determina la seguridad o el desastre, depender de una conexión a Internet poco fiable no es una opción.
Aquí entra en juego el edge computing. Es una solución sencilla: eliminar los riesgos de catástrofe colocando un centro de datos en la propia plataforma de perforación petrolífera. Cuando trasladas el procesamiento de datos críticos al lugar dónde ocurreCon la solución de la nube, se resuelven los problemas de latencia y tiempo de inactividad. En lugar de enviar los datos a la nube, se procesan en un centro de datos periférico: se acabó esperar a una conexión lenta para realizar análisis críticos.
Con un centro de datos de borde, cuando las mediciones o lecturas necesitan atención inmediata, se detectan al instante y los operadores pueden responder en tiempo real. Las operaciones son más eficientes y los riesgos de seguridad se reducen significativamente. Y cuando la conectividad lo permite, solo es necesario enviar los datos agregados a la nube para su almacenamiento a largo plazo, con el consiguiente ahorro en costes de ancho de banda.
Este es el poder y la promesa de la computación de borde.
Visualización de una arquitectura Edge Computing
La computación de borde acerca el procesamiento y el almacenamiento de datos a las aplicaciones y los dispositivos de los clientes aprovechando los centros de datos de borde escalonados, junto con el almacenamiento de datos integrado directamente en los dispositivos, cuando procede.
Este enfoque por niveles aísla las aplicaciones de las interrupciones de los centros de datos centrales y regionales. Cada nivel aprovecha cada vez más la conectividad local, que es más fiable, y sincroniza los datos dentro de los niveles y entre ellos en la medida en que la conectividad lo permite. Edge computing es la forma de alimentar aplicaciones siempre rápidas y siempre activas.
Me gusta visualizar las arquitecturas de borde como un conjunto de capas, lo que facilita la comprensión del concepto. Echa un vistazo al siguiente diagrama:
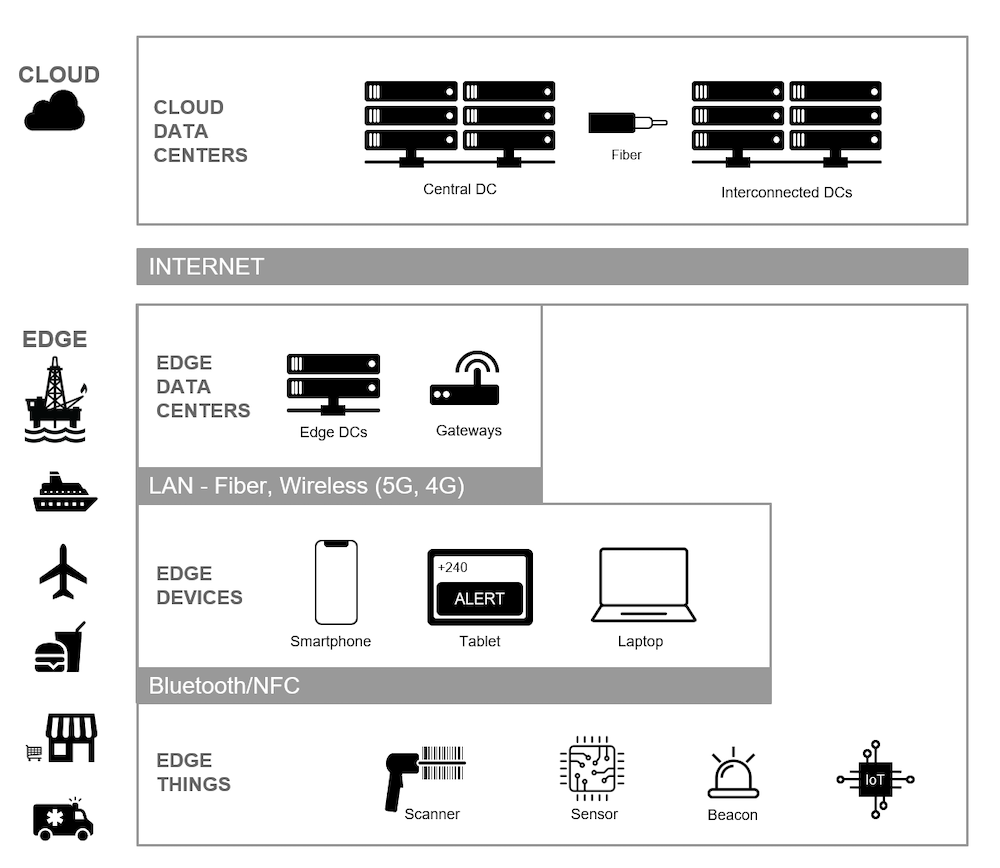
En el diagrama anterior, la capa superior representa los centros de datos en la nube, compuestos por un centro de datos central y centros de datos regionales interconectados. Los centros de datos en la nube siguen desempeñando un papel crucial en una arquitectura de computación de borde porque son el repositorio final de la información. Sin embargo, no se depende de los centros de datos en la nube para las aplicaciones locales.
La siguiente capa es el borde. El borde puede ser una plataforma petrolífera, como en nuestro ejemplo anterior, pero también podría ser un crucero, un avión, un restaurante, una tienda o una clínica médica móvil. La capa periférica contiene centros de datos periféricos y pasarelas de Internet de las Cosas (IoT). Estos se ejecutan en una red de área local, que puede ser de fibra, inalámbrica, 5G o redes más antiguas como 4G y anteriores.
En la capa periférica se encuentran dispositivos individuales, teléfonos inteligentes, tabletas y ordenadores portátiles que llevan los usuarios, así como dispositivos IoT que se comunican con el centro de datos periférico. También hay comunicación entre dispositivos a través de una red de área privada como RF o Bluetooth.
Aunque esta representación muestra un único centro de datos de borde para simplificar, podría haber n número de centros de datos de borde adicionales para facilitar la computación en todo un ecosistema empresarial. Por ejemplo, podría alimentar los sistemas POS de una cadena de tiendas minoristas utilizando centros de datos de borde en cada ciudad donde se concentran las tiendas.
Edge Computing y bases de datos
Todas las arquitecturas de computación de borde tienen un requisito importante: utilizar el derecha tipo de base de datos. Si estás construyendo una arquitectura de borde, necesitas usar una base de datos que:
-
- Funciona en todas las capas
- Distribuye su huella de datos por todas las capas
- Sincroniza al instante los cambios de datos en todas las capas
En esencia, es necesario crear un tejido síncrono de procesamiento de datos que abarque toda la arquitectura: desde la nube hasta el dispositivo, pasando por el perímetro. Echemos un vistazo más de cerca a nuestro diagrama de arquitectura de antes:
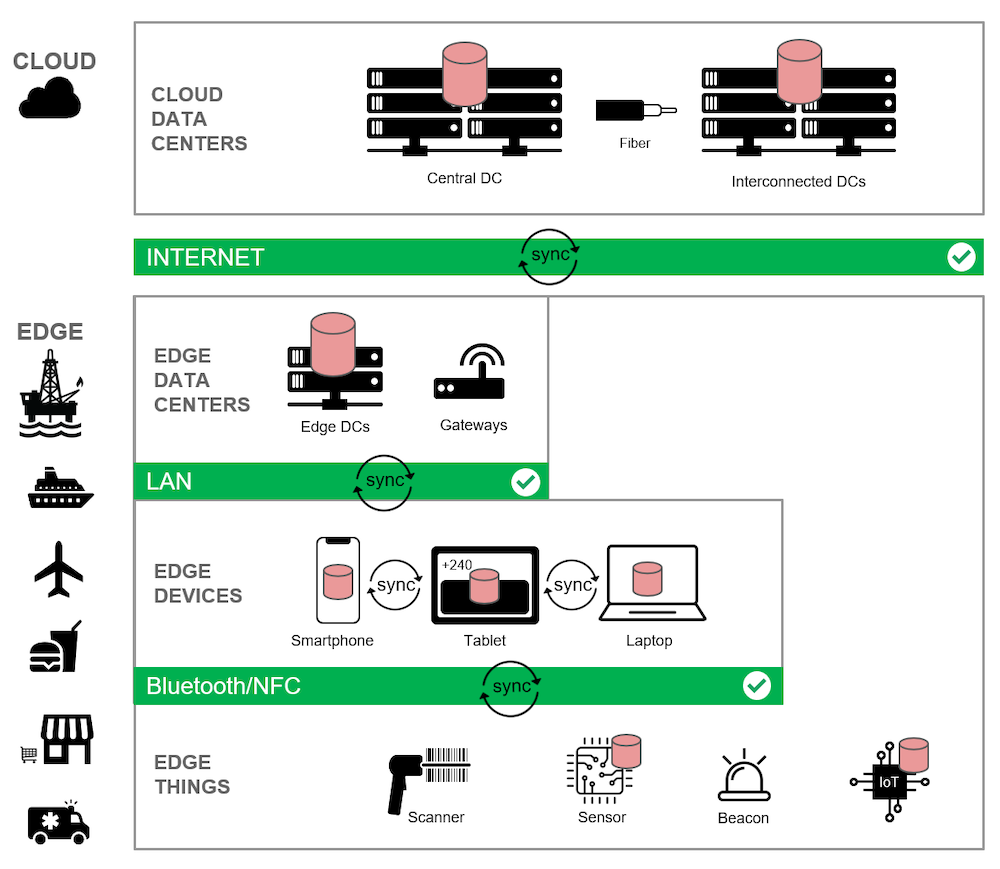
En esta versión de la arquitectura Edge Computing, he añadido iconos rojos de bases de datos para destacar dónde se almacenan y procesan los datos.
En la capa de la nube, se ve un servidor de base de datos instalado en el centro de datos central, así como los centros de datos interconectados a través de las regiones de la nube.
A continuación, en la capa periférica, se instala un servidor de base de datos en el centro de datos periférico.
Por último, se integra una base de datos directamente en determinados dispositivos móviles y de IoT, lo que les permite seguir procesando incluso en caso de fallo total de la red.
Pero el edge computing es mucho más que la simple instalación de una base de datos en cada nivel. Las bases de datos deben ser capaces de trabajar juntos en tándem como un todo cohesionado, replicando y sincronizando los datos capturados en el borde en el resto del entorno para garantizar que los datos estén siempre disponibles y nunca se pierdan o corrompan.
Como tal, en el diagrama también se ven datos que se sincronizan:
-
- Entre la nube y los servidores de bases de datos periféricos
- Entre bases de datos integradas en dispositivos y servidores de bases de datos en el perímetro o en la nube.
- Entre las bases de datos integradas en dispositivos y cosas, utilizando redes de área privada.
Al distribuir el procesamiento de datos en todas las capas de su arquitectura, conseguirá mayor velocidad, resistencia, seguridad y eficiencia del ancho de banda.
Si la conexión a Internet con el centro de datos en la nube se ralentiza o se interrumpe, las aplicaciones procesan los datos en los centros de datos periféricos, sin que ello afecte en absoluto a la capacidad de respuesta. Y si el centro de datos en la nube y Las aplicaciones con bases de datos integradas siguen funcionando según lo previsto -y en tiempo real- procesando y sincronizando datos directamente en los dispositivos y entre ellos. Y si ocurre una catástrofe y todos Cuando las capas de red dejan de estar disponibles, los dispositivos periféricos con procesamiento de datos integrado actúan como sus propios microcentros de datos, funcionando de forma aislada con disponibilidad 100% y capacidad de respuesta en tiempo real hasta que se restablece la conectividad.
Otra gran ventaja del modelo de computación periférica es su sólido soporte para la privacidad y seguridad de los datos. Estas consideraciones son críticas para las aplicaciones que manejan datos sensibles, como las de sanidad o finanzas. Uno de los principales valores del edge computing es que los datos sensibles nunca tienen que salir del borde.
Con una arquitectura de computación periférica, los usuarios y dispositivos siempre tienen acceso rápido a los datos, incluso en caso de latencia o interrupción de Internet. Y tu base de datos desempeña un papel fundamental para que todo esto suceda.
Cómo construir su propia arquitectura Edge Computing
¿Cómo se construye una arquitectura de computación perimetral?
Hay que tener en cuenta dos cosas: la infraestructura y el tratamiento de datos. Ambos son temas en profundidad, pero los trataré brevemente.
Infraestructura Edge Computing
En los primeros tiempos de la computación de borde, los arquitectos tenían que construirlo todo desde cero.
Tuvieron que crear su propia infraestructura extendida más allá de la nube y tuvieron que considerar dónde viviría esa infraestructura: ¿en las instalaciones? ¿en una nube privada? ¿colocada? ¿en contenedores? Tuvieron que considerar las implicaciones de la coexistencia de una infraestructura personalizada con nubes públicas.
Si construyeran un centro de datos periférico en una ubicación, ¿cómo podrían conectarlo a la nube para centralizar el almacenamiento y ampliarlo a otras ubicaciones según fuera necesario? ¿Y cómo podrían garantizar la estandarización y coherencia de los componentes arquitectónicos entre ubicaciones, así como la redundancia y la alta disponibilidad? Este tipo de preguntas hizo que el establecimiento de una infraestructura de computación de borde fuera una empresa compleja en sus inicios.
Afortunadamente, esa complejidad está desapareciendo.
Muchos de los principales proveedores de servicios en la nube ofrecen ahora servicios de computación de borde. Por ejemplo, AWS ha desplegado un amplio conjunto de servicios que facilitan la computación de borde para diversos casos de uso. Esencialmente, extienden su infraestructura de nube hasta el borde y permiten establecer centros de datos a nivel local en ciudades específicas, en las instalaciones y/o dentro de las redes 5G.
Servicios como estos, de AWS y otros proveedores de servicios en la nube, aportan más opciones, flexibilidad y simplicidad a las iniciativas de computación de borde. A su vez, estos servicios permiten a su organización comenzar rápidamente aprovechando la infraestructura bajo demanda y evolucionar de forma eficiente manteniendo un entorno estandarizado y repetible.
Procesamiento de datos en la periferia
Como he dicho antes, no se puede esperar para instalar cualquier base de datos antigua para edge computing y alcanzar el éxito. Es importante elegir una base de datos con las capacidades y características adecuadas.
En una arquitectura distribuida que abarca desde la nube hasta el borde, debe facilitar el procesamiento de datos en todas las capas de su ecosistema. Todas las capas deben compartir una comprensión de los datos en tiempo real, y cualquier capa debe poder funcionar de forma aislada en caso de pérdida de conectividad.
Esto significa que necesita una base de datos que distribuya de forma nativa su almacenamiento y carga de trabajo entre los distintos niveles de una arquitectura de borde. Su base de datos también debe tener la capacidad de replicar y sincronizar instantáneamente los datos entre las instancias de la base de datos, ya estén en la nube o en un centro de datos de borde.
Además, su base de datos debe ser integrable. El almacenamiento de datos debe integrarse directamente en el dispositivo periférico para facilitar el procesamiento de datos cuando esté completamente desconectado. Como tal, la base de datos integrada debe ser capaz de funcionar sin ningún punto de control central en la nube, y debe sincronizarse automáticamente con el resto de su ecosistema de datos cuando vuelva la conectividad.
Además, la sincronización debe ser bidireccional y controlable para proporcionar un flujo de datos seguro y óptimo en toda la arquitectura de borde. Por ejemplo, en el escenario de una fábrica inteligente, los datos de alta velocidad capturados de una línea de montaje pueden procesarse y analizarse en el borde, pero -por eficiencia del ancho de banda de la red- solo los datos agregados se sincronizan con la nube para su almacenamiento final.
Cuando planifique sus propias iniciativas de edge computing, sólo debería considerar una base de datos que cumpla todos los requisitos de procesamiento de datos mencionados.
Construir con audacia en la periferia
Una arquitectura edge computing garantiza baja latencia y resistencia a los problemas de Internet. Al procesar los datos más cerca de donde se producen, la computación de borde hace que las aplicaciones sean más rápidas y fiables.
Este sencillo enfoque impulsará una nueva clase de aplicaciones modernas e innovaciones futuras. La clave del éxito de las arquitecturas de computación periférica está en aprovechar una base de datos preparada para ello.
Obtenga más información sobre edge computing y edge services en este informe de IDC: "Rendimiento y toma de decisiones con Couchbase." El informe cubre el panorama emergente de los servicios de borde y destaca los resultados de las pruebas comparativas de latencia de Couchbase en zonas de servicios de borde de AWS y Verizon, ¡no te lo pierdas!
Obtenga el informe aquí

[...] Introducción a las arquitecturas Edge Computing (Mark Gamble) [...]