
If I asked five different people what “edge computing” is, I’d most certainly get five different answers. Confusingly, they’d probably all be right.
Edge computing is a strategic architecture that’s growing in popularity, but its different permutations and its myriad use cases make it difficult to pin down.
Is edge computing about mobile? or IoT? or smart environments? Is it cloud? or on-prem? or on-device? Is it about computing? or networking? or 5G? Does it apply to robots in a factory? or monitors in an operating room? or driverless cars?
Edge computing is all of these things and more.
In this article, I’ll walk you through the essential concepts of edge computing and what you need in order to successfully build your own edge architecture. But (spoiler alert!) harnessing the benefits of edge computing pretty much comes down to one thing: data – where and how you process it, and how you flow it to and from the edge.
First, let’s define edge computing.
What Is Edge Computing Architecture?
Wikipedia describes edge computing as:
Edge computing is a distributed computing paradigm that brings computation and data storage closer to the sources of data. This is expected to improve response times and save bandwidth. The term refers to an architecture rather than a specific technology.
Edge computing all about storing and processing data closer to the users and applications that consume it. In the end, it reduces latency and insulates against internet outages. Edge computing architectures promise to power innovations like
- Connected homes
- Autonomous vehicles
- Robotic surgery
- Advanced real-time gaming
Edge computing is an alternative architecture to cloud computing for applications that require high-speed and high availability. This is because apps that rely solely on the cloud for storing and processing data become dependent on internet connectivity – and therefore subject to its inherent unreliability. When the internet slows or becomes unavailable, the entire application slows or fails in turn.
Edge computing gets around internet dependencies by locating data as close as possible to where it is produced and consumed, which speeds up applications and improves their availability.
A Real-World Example of Edge Computing
Let’s look at a concrete example.
Imagine an oil drilling platform in the middle of the North Sea. Operators collect data from sensors all over the platform as part of a daily routine, measuring things like pressure, temperature, wave height, and other factors that affect operating capacity. This kind of data comes fast, changes often and requires a real-time response.
Suppose that the oil platform data is stored and processed in a cloud data center. The platform operators would have to send their data over the internet – and in the North Sea that means via satellite which is slow and expensive – just to evaluate their measurements.
Now, imagine that a sensor on a critical component of the platform begins to detect signs of likely failure, a potential break down that could lead to a dangerous turn of events. It takes too much time to collect data points on the component, send them to the cloud for processing, and then wait for a recommended course of action. And if the connection slows – or falters for even a bit? Critical time is lost. By the time the platform operators receive a response from the cloud, it could be too late.
Where seconds count and when the difference between uptime and downtime determines safety or disaster – depending on an unreliable internet connection isn’t an option.
Enter edge computing. It’s a simple solution: eliminate the risks of a disaster by putting a data center on the oil drilling platform itself. When you move the processing of critical data to the place where it happens, you solve the problems of latency and downtime. Instead of sending data to the cloud, it’s processed in an edge data center – no more waiting on a slow connection for critical analysis.
With an edge data center, when measurements or readings need immediate attention, they are detected instantly, and operators can respond in real time. Operations are more efficient and safety risks are significantly reduced. And when connectivity permits, only aggregated data needs to be sent to the cloud for long-term storage, saving on bandwidth costs.
This is the power and promise of edge computing.
Visualizing an Edge Computing Architecture
Edge computing moves data processing and storage closer to applications and client devices by leveraging tiered, edge data centers – along with embedded data storage directly on devices where appropriate.
This tiered approach insulates applications from central and regional data center outages. Each tier leverages increasingly local connectivity – which is more reliable – and synchronizes data within and across tiers as connectivity permits. Edge computing is how you power always-fast, always-on applications.
I like to visualize edge architectures as a set of layers, which makes the concept easier to understand. Take a look at the diagram below:
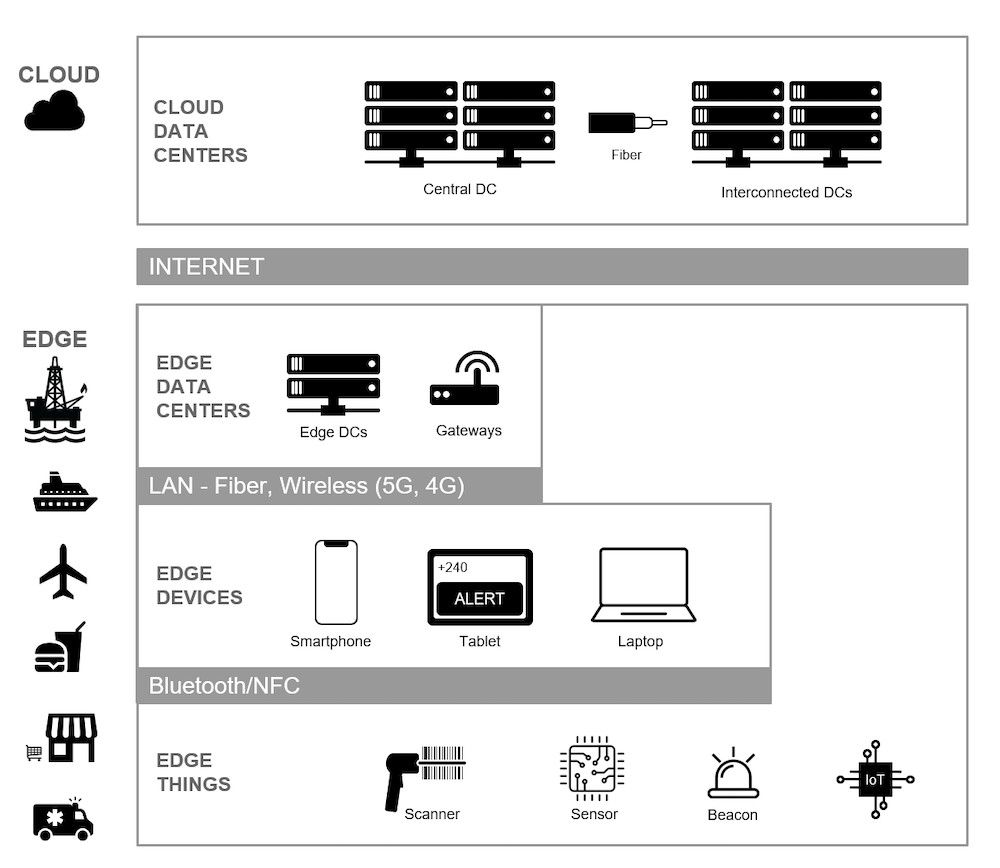
In the diagram above, the top layer represents cloud data centers, comprised of a central data center and interconnected regional data centers. The cloud data centers still serve a crucial role in an edge computing architecture because they’re the final repository of information. However, cloud data centers aren’t relied upon for local applications.
The next layer down is the edge layer. The edge could be an oil platform, as in our earlier example, but it could just as easily be a cruise liner, airplane, restaurant, retail shop or mobile medical clinic. The edge layer contains edge data centers and Internet of Things (IoT) gateways. These run on a local area network, which could be fiber, wireless, 5G or older networks such as 4G and earlier.
Within the edge layer, you see individual devices, smart phones, tablets and laptops carried by users, as well as IoT devices that all communicate with the edge data center. There is also communication between devices via a private area network such as RF or Bluetooth.
While this depiction shows a single edge data center for simplicity, there could be n number of additional edge data centers to facilitate computing across a business ecosystem. For example, you might power POS systems for a chain of retail stores using edge data centers in each city where stores are concentrated.
Edge Computing and Databases
All edge computing architectures have an important requirement: using the right kind of database. If you’re building an edge architecture, you need to use a database that:
- Runs in all layers
- Distributes its data footprint across all layers
- Synchronizes data changes instantly across all layers
In essence, you need to create a synchronous fabric of data processing that spans the entire architecture: from the cloud through the edge to the device. Let’s take a closer look at our architecture diagram from earlier:
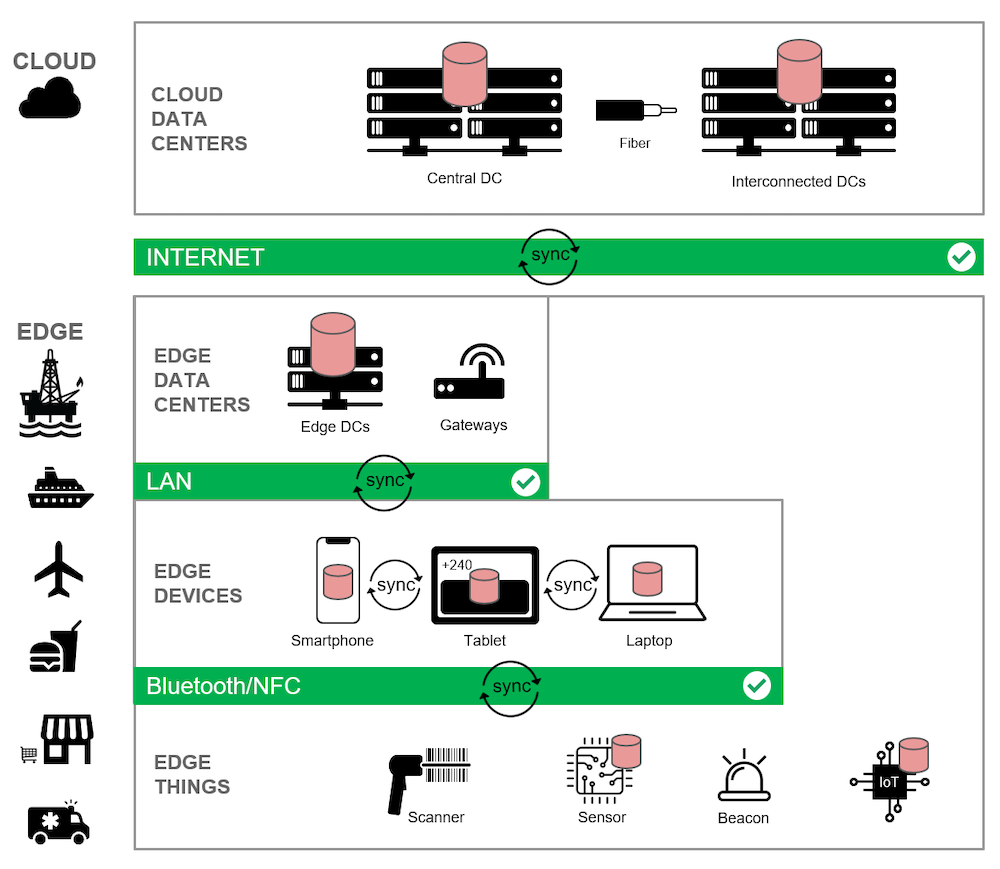
In this version of the edge computing architecture, I’ve added red database icons to emphasize where data is stored and processed.
In the cloud layer, you see a database server installed in the central data center, as well as the interconnected data centers across cloud regions.
Then in the edge layer, a database server is installed in the edge data center.
Finally, a database is embedded directly to select edge mobile and IoT devices, allowing them to keep processing, even in the event of total network failure.
But edge computing is much more than simply installing a database at every level. The databases must be able to work together in tandem as a cohesive whole, replicating and synchronizing data captured at the edge across the rest of the environment to guarantee that data is always available and never lost or corrupted.
As such, in the diagram you also see data being synchronized:
- Between cloud and edge database servers
- Between embedded databases on devices and database servers at the edge or in the cloud
- Between the embedded databases on devices and things, using private area networks
By spreading data processing across every layer of your architecture, you achieve greater speed, resilience, security and bandwidth efficiency.
If the internet connection to the cloud data center slows or stops, applications process data in the edge data centers instead, completely unaffected and highly responsive. And if the cloud data center and edge data center become unavailable, apps with embedded databases continue to run as intended – and in real time – by processing and syncing data directly on and between devices. And if the catastrophic happens and all network layers become unavailable, edge devices with embedded data processing serve as their own micro data centers, running in isolation with 100% availability and real-time responsiveness until connectivity is restored.
Another big benefit of the edge computing model is robust support for data privacy and security. These considerations are critical for applications that handle sensitive data, such as in healthcare or finance. A key value point for edge computing is that sensitive data never has to leave the edge.
With an edge computing architecture, users and devices always have speedy access to data, even in the event of internet latency or outage. And your database plays a pivotal role in making it all happen.
How to Build Your Own Edge Computing Architecture
So how do build your own edge computing architecture?
You need to consider two things: infrastructure and data processing. Both of these are in-depth topics, but I’ll briefly touch on each.
Edge Computing Infrastructure
In the early days of edge computing, architects had to build it all from scratch.
They had to create their own extended infrastructure beyond the cloud, and they had to consider where that infrastructure would live: on premises? in a private cloud? co-located? containerized? They had to consider the implications of a custom-built infrastructure’s co-existence with public clouds.
If they built an edge data center in one location, how could they connect it to the cloud for centralized storage, and extend it to other locations as needed? And how could they ensure standardization and consistency of architectural components between locations, as well as redundancy and high availability? These sorts of questions made establishing an edge computing infrastructure a complex undertaking in its infancy.
Thankfully, that complexity is fading.
Many major cloud service providers now offer edge computing services. For example, AWS has rolled out a comprehensive set of services that facilitate edge computing for a variety of use cases. They essentially extend their cloud infrastructure to the edge and allow data centers to be set up locally in specific cities, on premises and/or within 5G networks.
Services like these, from AWS and other cloud service providers, bring more options, flexibility and simplicity for edge computing initiatives. In turn, these services allow your organization to start quickly by leveraging on-demand infrastructure and to evolve efficiently by maintaining a standardized, repeatable environment.
Data Processing at the Edge
As I stated earlier, you can’t expect to install any old database for edge computing and achieve success. It’s important to choose a database with the right capabilities and features.
In a distributed architecture that spans from the cloud to the edge, you must facilitate data processing throughout every layer of your ecosystem. All layers need to share a real-time understanding of the data, and any layer should be able to run in isolation in the event of loss of connectivity.
This means you need a database that natively distributes its storage and workload across the various tiers of an edge architecture. Your database must also have the ability to instantly replicate and synchronize data across database instances, whether they’re in the cloud or in an edge data center.
In addition, your database needs to be embeddable. Data storage should be integrated directly to the edge device in order to facilitate data processing when completely offline. As such, the embedded database must be able to operate without any central cloud control point, and it must automatically synchronize with the rest of your data ecosystem when connectivity returns.
Furthermore, synchronization must be bi-directional and controllable in order to provide a secure and optimal flow of data throughout your edge architecture. For example, in a smart factory scenario, high velocity data captured from an assembly line can be processed and analyzed at the edge, but – for network bandwidth efficiency – only aggregated data is synchronized to the cloud for ultimate storage.
When planning out your own edge computing initiatives, you should only consider a database that meets all of the above data processing requirements.
Build Boldly on the Edge
An edge computing architecture guarantees low latency and resilience to internet issues. By processing data closer to where it happens, edge computing makes applications faster and more reliable as a result.
This straightforward approach will power a new class of modern applications and future innovations. The key to achieving success with edge computing architectures is in leveraging an edge-ready database.
Learn more about edge computing and edge services in this IDC report: “Performance Accountability & Edge Decision Making with Couchbase.” The report covers the emerging edge services landscape and highlights Couchbase latency benchmark test results on edge service zones from AWS and Verizon, don’t miss it!
Ready to explore the edge?<br/ >Get the report here
Author
1 Comment
-
[…] An Introduction to Edge Computing Architectures (Mark Gamble) […]
Leave a comment
You must be logged in to post a comment.