Las bases de datos distribuidas aplican los principios de la informática distribuida al almacenamiento de datos. El ejemplo más sencillo es una base de datos que almacena datos en dos (o más) servidores conectados por una red. Se puede acceder a este "cluster" y gestionarlo como si fuera un único servidor de base de datos.
En comparación, el modelo tradicional de servidor único de una base de datos existe en un servidor.
Las principales ventajas de utilizar una arquitectura de base de datos distribuida para los servicios son:
- Agrupación para gestionar la carga (escalado horizontal)
- Alta disponibilidad (si un servidor se desconecta, los demás permanecen en línea y disponibles).
- Replicación (para alta disponibilidad, recuperación en caso de catástrofe y distribución geográfica)
Existen muchas prácticas recomendadas para las bases de datos distribuidas, incluidas diferentes opciones, topologías y métodos para distribuir la carga entre los servidores. Entonces, ¿cómo funcionan las bases de datos distribuidas?
Escala horizontal
Históricamente, un único servidor de bases de datos para un pequeño conjunto de aplicaciones y datos ha funcionado bien. Sin embargo, cuando se expone a una base de usuarios grande y pública, la única forma de aumentar la capacidad de estos servidores es actualizarlos a un servidor más caro.
Para mejorar la capacidad, traslade el software de la base de datos a otra máquina individual con más memoria, más espacio en disco y más procesadores. Esto es "escalado vertical". El inconveniente de este enfoque es que puede requerir tiempo de inactividad. También hay un límite en el rendimiento que se puede obtener de una sola máquina. (Véase el artículo de Herb Sutter Se acabó la comida gratis).
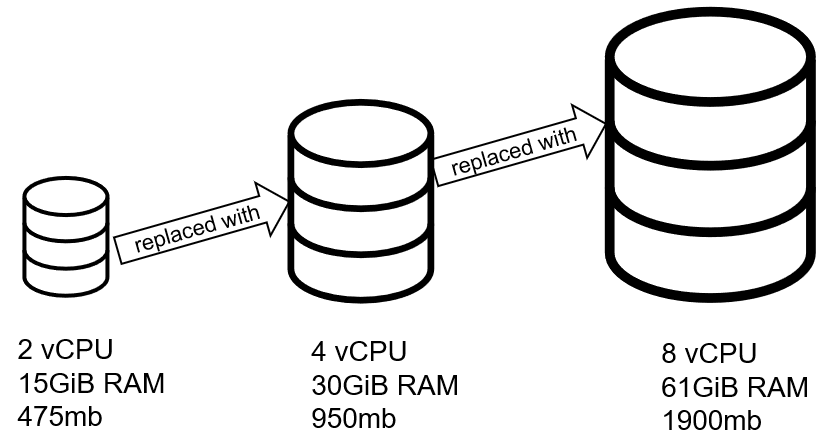
Por desgracia, muchas bases de datos, especialmente las relacionales (RDBMS), no están diseñadas para ser distribuidas y agrupadas.
Sin embargo, las bases de datos distribuidas se crean desde el principio para soportar una escalabilidad elástica. ¿Necesita añadir más recursos para gestionar más carga? Instale el software de la base de datos en 1 o más máquinas adicionales y añádalas al clúster.
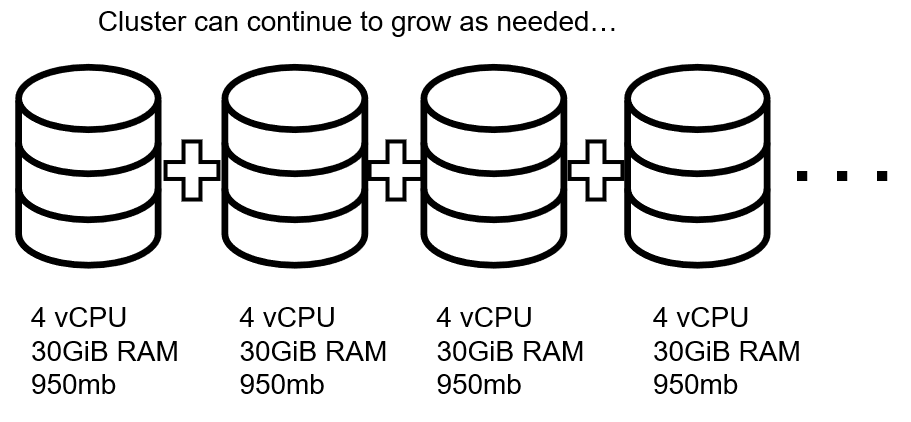
A continuación, añada máquinas de bajo coste al clúster cuando sea necesario. También puede eliminarlas y reducirlas si ya no las necesita.
Arquitectura de bases de datos distribuidas
Para las bases de datos, existen dos enfoques populares para la distribución de datos: primario/secundario (históricamente llamado maestro/esclavo) y nada compartido (a veces llamado sin amo).
Arquitectura primaria/secundaria
En una arquitectura primaria/secundaria, hay un servidor "primario" designado. Este servidor almacena todos los datos y gestiona todas las solicitudes de datos. Hay uno o varios servidores "secundarios". Estos servidores recibirán actualizaciones de datos del primario para mantenerse sincronizados y almacenar una réplica completa de los datos.
Si el servidor primario se desconecta (falla), los servidores restantes (y/o los servidores de coordinación) designan a uno de los servidores secundarios para que sea el nuevo primario.
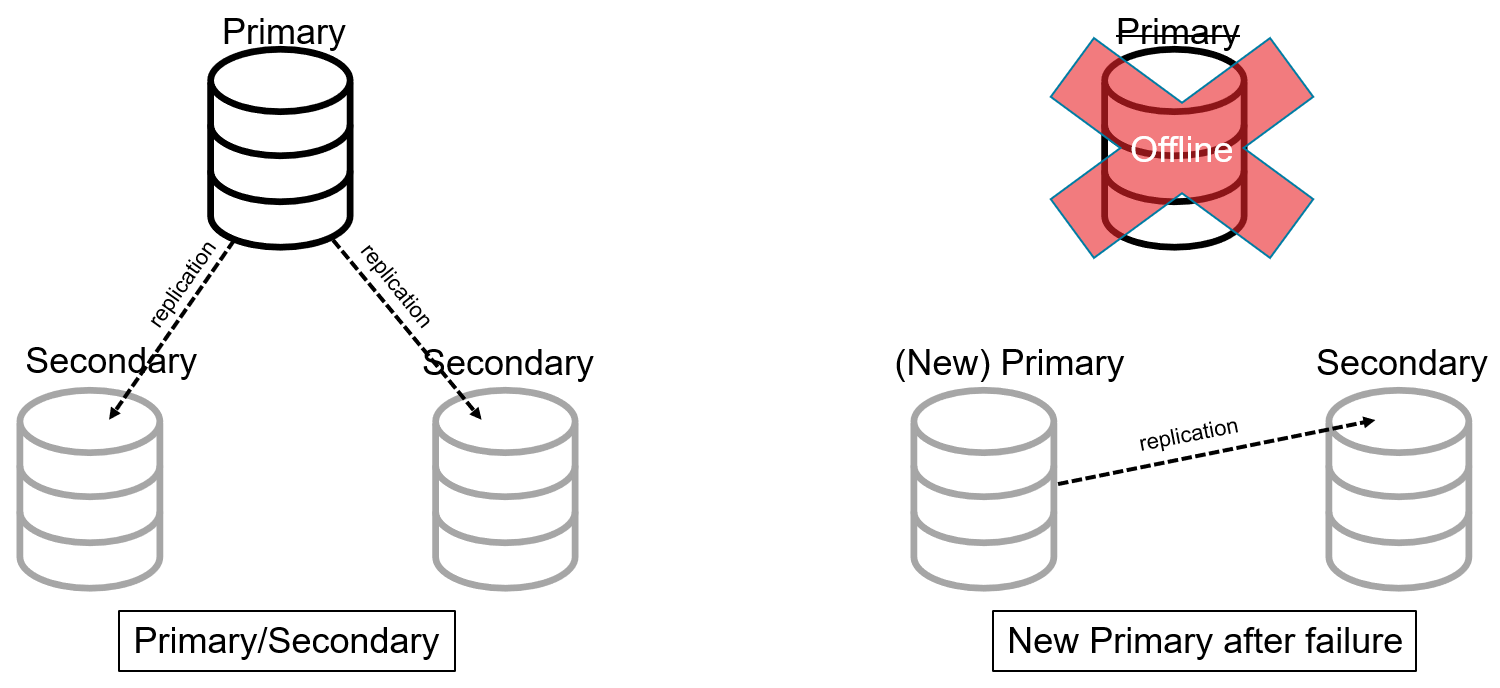
Los arquitectos utilizan este modelo para alta disponibilidad a las bases de datos tradicionales no distribuidas. Sin embargo, esta arquitectura de bases de datos distribuidas no hace mucho por resolver el problema del aumento de la carga. Para lograrlo, fragmentación debe utilizarse.
Bases de datos distribuidas no compartidas
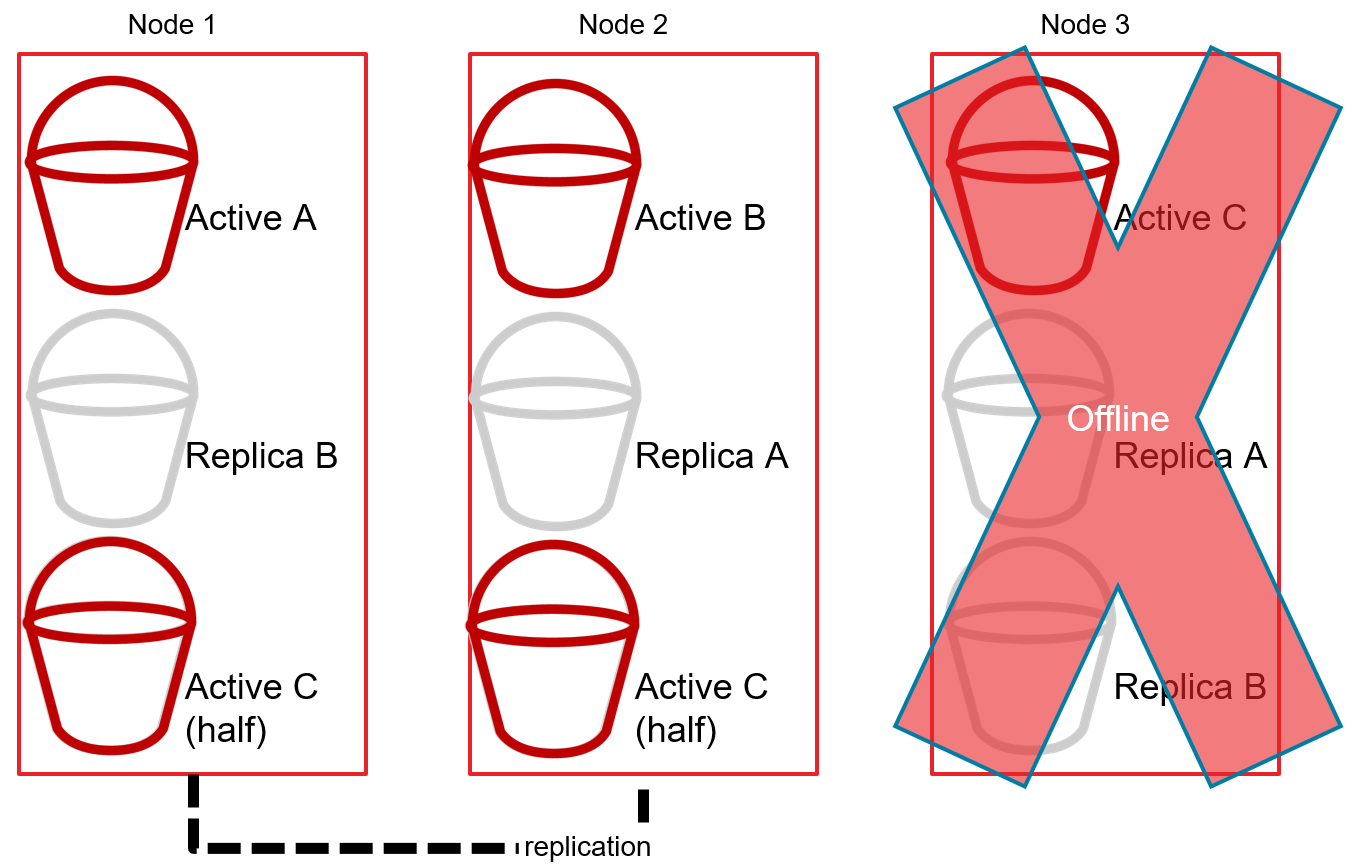
La arquitectura "nada compartido" consiste en dividir los datos en particiones denominadas "fragmentos". Cada fragmento vive en un servidor individual (nodo) del clúster. Por ejemplo, si hay 300 registros y 3 nodos, cada nodo almacenaría (idealmente) 100 registros. Cada nodo adicional podría dividir aún más los datos y seguir repartiendo la carga según sea necesario.
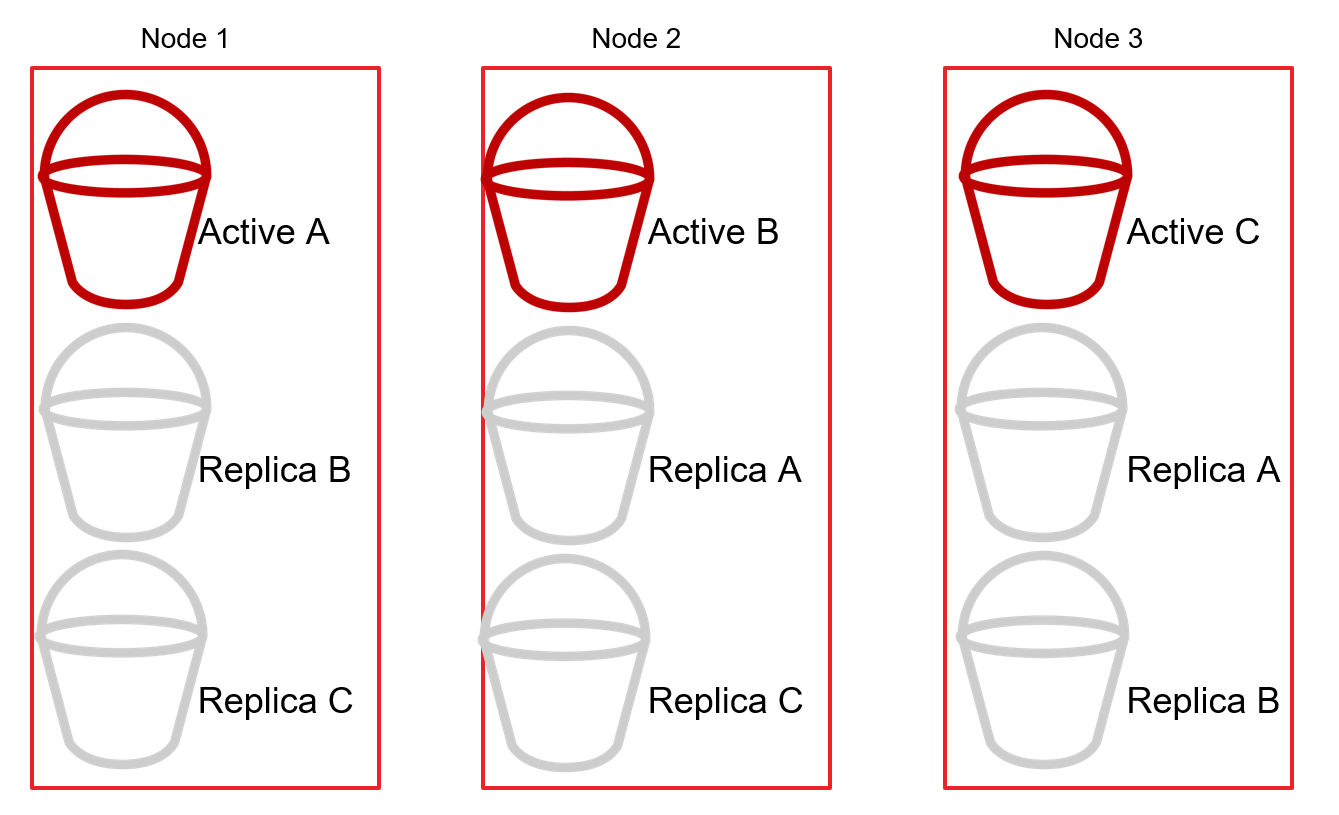
El cluster también replicará shards entre los nodos para mantener una alta disponibilidad. Por ejemplo, si el Nodo 1 contiene el fragmento activo A, el Nodo 2 contendrá un fragmento de réplica A, y así sucesivamente.
Entonces, si el Nodo 3 se desconecta, el cluster promueve las réplicas del Shard C a Activo para mantener el cluster de BD distribuido online (como un todo).
La naturaleza de las bases de datos relacionales es almacenar filas individuales de datos juntas en una tabla estrechamente acoplada. Esto dificulta las bases de datos SQL distribuidas. Por eso las organizaciones suelen elegir NoSQL cuando la agrupación en clústeres, la alta disponibilidad y la replicación son fundamentales. NoSQL ofrece datos estrictamente acoplados que no pueden existir fuera de una tabla a cambio de datos independientes que pueden existir en cualquier fragmento de un clúster.
Ejemplos de bases de datos distribuidas
Dependiendo de la BD distribuida que utilice, la fragmentación puede ser completamente automática o requerir un esfuerzo considerable de planificación y mantenimiento.
Veamos dos ejemplos de bases de datos distribuidas que utilizan la popular NoSQL y en qué se diferencian:
Servidor Couchbase
Couchbase Server es una base de datos NoSQL distribuida que almacena datos como piezas individuales de datos JSON llamados documentos. Cada documento tiene una clave única.
Cada documento existe dentro de un fragmento (llamado vBuckets en Couchbase), y cada fragmento se asigna a un nodo. Un clúster Couchbase tiene una cantidad fija de 1024 vBuckets totales.
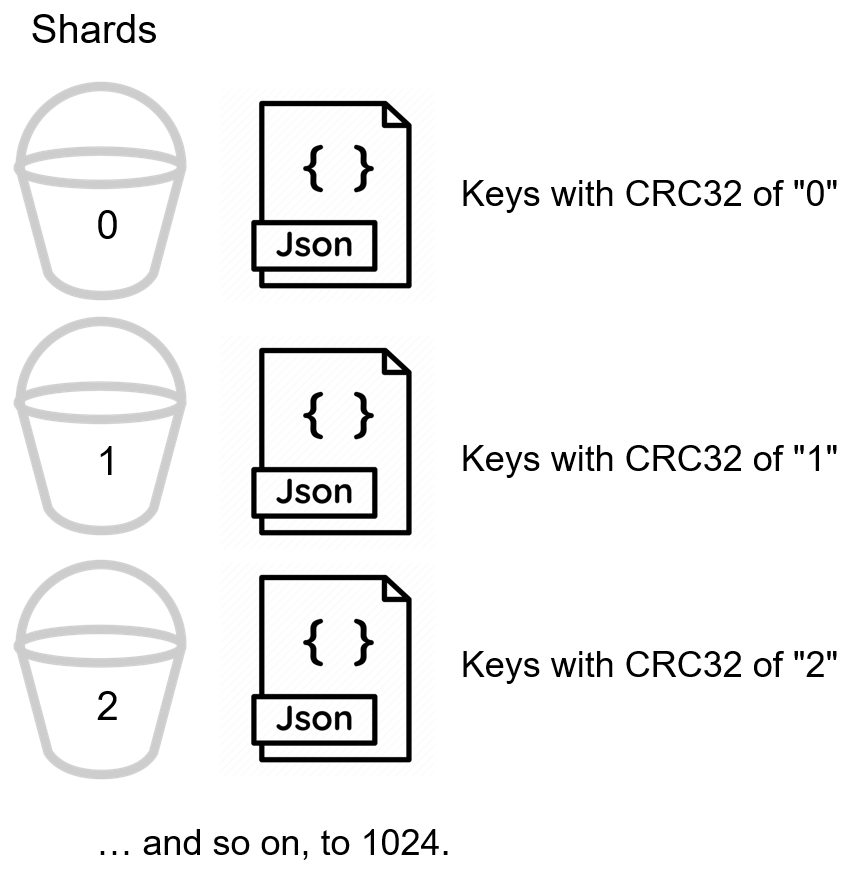
Couchbase automáticamente asigna un documento a vBucket en función de su clave (mediante un algoritmo hash CRC32). No es necesario que los desarrolladores, DBA o DevOps creen y gestionen la fragmentación. Cada nodo tiene un gestor de clústeres que garantiza que todos los fragmentos se mantengan en equilibrio y que los datos se distribuyan uniformemente. No habrá "puntos calientes": un nodo almacenando cantidades de datos mucho mayores que otros nodos. No hay necesidad de otros servidores para procesar el enrutamiento de consultas o proporcionar una fachada de equilibrio de carga aparte del clúster de Couchbase Server.
MongoDB
MongoDB también es una base de datos NoSQL distribuida. También almacena datos como piezas individuales en un formato similar a JSON llamado BSON. Cada documento tiene una clave única.
MongoDB adopta un enfoque diferente para la fragmentación. Para fragmentar datos, debe seleccionar una clave de fragmentación (consistente en una o más piezas de datos BSON). Por ejemplo, podría considerar la fragmentación de datos por "apellido" y "código postal".
Una vez definida una clave de fragmento, Mongo enruta las peticiones de los clientes a través de otro servidor que ejecuta un "enrutador de consultas". Este enrutador de consultas se referirá a otro servidor llamado "servidor de configuración". Este puede determinar en qué servidor de datos se encuentra el fragmento deseado.
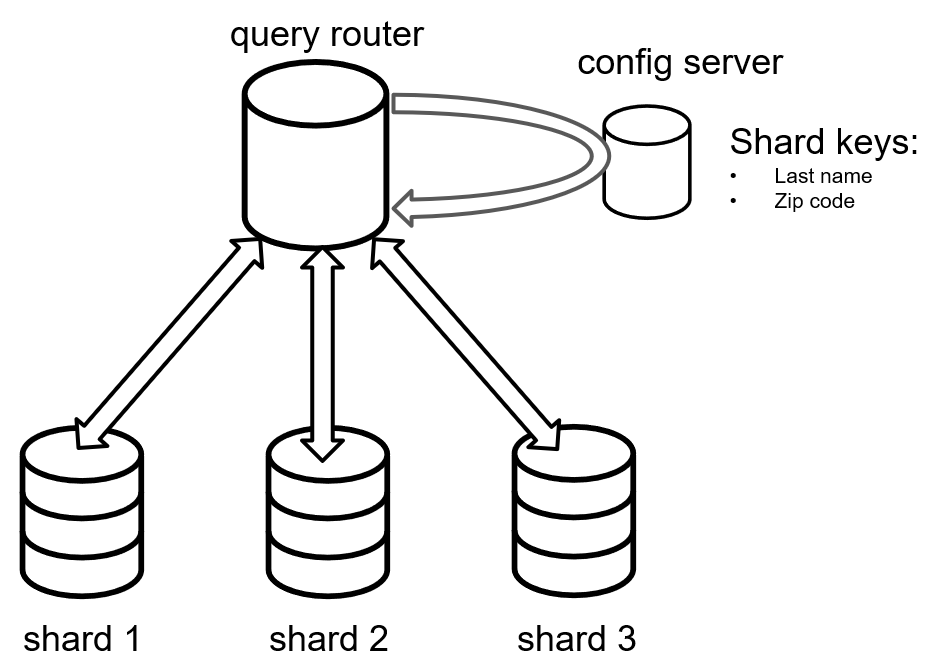
El proceso de fragmentación no es automático. El equipo de desarrollo debe elegir las claves de fragmentación con cuidado y revisarlas periódicamente para evitar cuellos de botella y puntos calientes.
Resumen
Estos son sólo dos ejemplos notables de bases de datos distribuidas. Hay muchos más ejemplos que adoptan distintos enfoques de arquitectura.
Todos tienen en común que almacenan los datos en servidores conectados a la red.
¿Te interesa el enfoque de fragmentación automática que está adoptando Couchbase Server? Eso es sólo arañar la superficie de lo que Couchbase puede hacer. Con una arquitectura integrada que prioriza la memoria, búsqueda de texto completo, capacidades de consulta SQL distribuida y mucho más, Couchbase es una plataforma de datos completa. Descargar Couchbase Server hoy mismo y pruébalo.
[...] para almacenar tus datos y evitar que vigilen tus archivos y documentos importantes. Visite sitios como https://www.couchbase.com/distributed-databases-overview/ para saber más sobre [...]