Dada la arquitectura y el diseño de los sistemas NoSQL, especialmente la familia de bases de datos de documentos como Couchbase que no imponen el esquema en la escritura, el modelado de datos para NoSQL a menudo puede ser un reto al migrar de sistemas relacionales a NoSQL o al construir aplicaciones desde cero utilizando NoSQL. De hecho, el modelado de datos es a menudo un factor crítico de éxito para los despliegues de Couchbase, y la optimización progresiva de los modelos de datos puede ser un gran impulsor del rendimiento de la aplicación dada la naturaleza de rápida evolución de las aplicaciones de big data.
Tradicionalmente, el modelado de datos para sistemas relacionales era la ciencia de identificar los objetos de datos, sus relaciones entre sí y su representación precisa, que sentaba las bases para un buen diseño de la base de datos. El modelado para NoSQL, por otro lado, explora los patrones de acceso específicos de la aplicación, por ejemplo, "¿cuáles son los tipos de preguntas que a los usuarios les gustaría responder con estos datos?". Esto a su vez dicta el tipo de consultas que necesitan ser soportadas y se centra en la mejor manera de disponer los datos para la optimización del rendimiento. Estas consideraciones nos llevan a cambiar nuestro enfoque de modelado de datos, pasando de las restricciones tradicionales de los RDBMS (esquema en escritura) al modelado de datos para la aplicación específica (esquema en lectura).
Otra diferencia entre los sistemas RDBMS y NoSQL que afecta a los paradigmas de modelado es el concepto de normalización y desnormalización de los datos. Mientras que los sistemas RDBMS hacían hincapié en la normalización de los datos para comprender las relaciones estrictas y cumplir con las rígidas limitaciones de almacenamiento de antaño, los sistemas NoSQL flexibles se inclinan por la desnormalización de los datos, ya que los datos se distribuyen en clústeres y la redundancia puede facilitar el escalado de las lecturas de datos. A menudo, el modelo de datos ideal es una combinación de ambos enfoques, dependiendo del caso de uso.
Por lo tanto, el modelado preciso de los datos sigue siendo una disciplina fundamental para el éxito con las bases de datos NoSQL.
Ahora, vamos a sumergirnos en el modelado utilizando erwin DM NoSQL. erwin DM NoSQL ofrece tres funcionalidades principales:
Ingeniería avanzada
El proceso de convertir tus modelos relacionales a modelos JSON compatibles con Couchbase.
Transformación
Posibilidad de elegir la forma de transformación deseada (normalizada, desnormalizada, personalizada) para sus modelos.
Ingeniería inversa
Posibilidad de importar el esquema de datos de producción en Couchbase al entorno erwin.
La siguiente es la guía paso a paso para modelar datos para la Plataforma de Datos Couchbase usando erwin DM NoSQL:
Preparados:
Primer paso:
Solicitud de cuenta aquí e inicie sesión en erwin DM NoSQL utilizando sus credenciales.

Segundo paso:
Empujar un modelo Entidad-Relación generado desde erwin DM o cualquier otra herramienta de modelado relacional en formato "XML" utilizando la opción de importación a erwin DM NoSQL.
Paso 3:
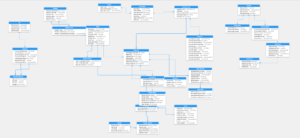
Visualice sus diagramas ER en entorno erwin.
Transformación
Primer paso:
Elija transformar los modelos utilizando una transformación normalizada, desnormalizada o personalizada.
Segundo paso:
a.Transformación normalizada:
La normalización suele ser el proceso de organización de los datos en la base de datos mediante la creación de tablas separadas y el establecimiento de relaciones para eliminar duplicaciones. Los objetos o entidades de este proceso suelen estar referenciados. Al crear modelos JSON, las tablas referenciadas suelen ser documentos independientes.
b.Transformación desnormalizada:
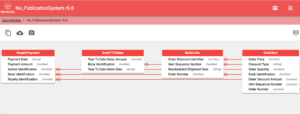
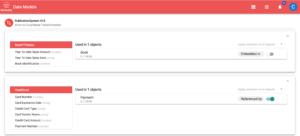
En este proceso, los objetos de datos suelen estar incrustados. Dado que objetos similares están incrustados en muchos documentos, esta organización presenta redundancia. La desnormalización suele mejorar significativamente el rendimiento, ya que no se necesitan uniones para obtener los datos necesarios. Esto se adopta a menudo en los sistemas NoSQL. En esta herramienta, el modelo transformado generado mediante la desnormalización es una combinación de objetos incrustados y referenciados.

En la figura anterior, la orden de compra y el artículo de la orden son objetos incrustados, mientras que Publisher, Store name y BookReturn son objetos referenciados.
c.Transformación personalizada:
El erwin DM NoSQL típicamente analiza la organización de datos usando tu diagrama E-R y transforma tus modelos a modelos JSON compatibles con Couchbase basados en ciertas reglas. Sin embargo, dado que tú, como desarrollador o propietario de una aplicación, eres quien mejor conoce tu aplicación, te ofrecemos la posibilidad de personalizar tus modelos. Tienes la opción de hacer referencia a ciertos objetos incrustados y te proporcionamos algunas directrices dentro de la herramienta para ayudarte a tomar la decisión correcta.
Nota: Puede clonar cualquiera de estos modelos y modificarlos añadiendo o eliminando atributos, propiedades, etc,
Ingeniería de avance:
Primer paso:
Descargue el modelo creado en su sistema local.

Segundo paso:
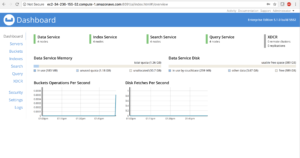
Configurar clústeres de Couchbase en AWS y acceder a la consola web mediante el puerto 8091
Paso 3:
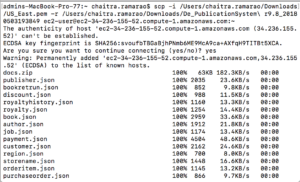
Utiliza la copia segura y copia el archivo descargado desde tu máquina local a tu instancia EC2 de Couchbase.
Sintaxis (OSX): scp -i ruta a la clave -r ruta al directorio ec2-user@hostname:~
Ejemplo: scp -i /Usuarios/chaitra.ramarao/Descargas/US_East.pem -r /Usuarios/chaitra.ramarao/Descargas/Cl_De_EMOVIES\ r9.64_20180329185059 ec2-user@ec2-54-152-108-80.compute-1.amazonaws.com:~
Paso 4:
Inicie sesión en su instancia de AWS mediante ssh
Sintaxis(OSX):ssh -i ruta a key.pair ec2-user@remote ip
Ej: ssh -i /Usuarios/chaitra.ramarao/Descargas/US_East.pem ec2-user@ec2-34-203-230-73.compute-1.amazonaws.com
Paso 5:
Comprueba si los archivos se han copiado listándolos con "ls".
Paso 6:
Vaya al archivo bulkInsert.sh
Ej:Cd /De_peliculas../scripts/5.x para localizar bulkInsert.sh
Paso 7:
Convierte el archivo bulkInsert en un ejecutable y establece la ruta
Chmod +x bulkInsert.sh
PATH=/opt/couchbase/bin:$PATH
Paso 8:
Ejecute el script bulkInsert con la siguiente sintaxis
./bulkInsert.sh
Ej : ./bulkInsert.sh localhost 8091 Ejemplo de contraseña de administrador
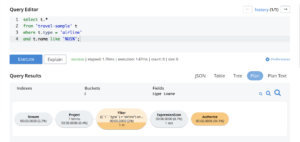
Puede ver los datos de muestra modelados cargados en Couchbase con el nombre de bucket especificado por usted.
El script típicamente crea modelos sobre datos basura, puede ser modificado por los desarrolladores de aplicaciones para crear modelos para muestras de datos reales y usarlos para desplegar a Couchbase usando los scripts de despliegue proporcionados.
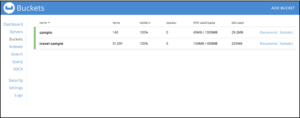
También puedes consultar los datos una vez cargados en Couchbase usando N1QL (SQL para JSON) y probar la precisión y eficiencia de tus modelos usando Query workbench y query planner.
Ingeniería inversa:
Primer paso:
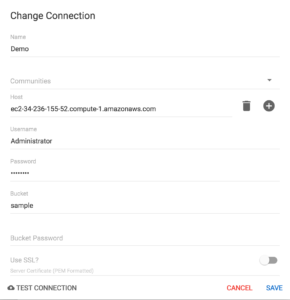
Configure la conexión a Couchbase utilizando el gestor de conexiones como se muestra a continuación:
Segundo paso:
Elija Couchbase mediante ingeniería inversa
Paso 3:
Importación de esquemas de datos de producción de Couchbase
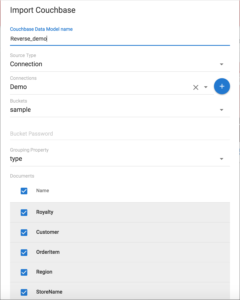
Paso 4:
Visualizar los modelos Couchbase de ingeniería inversa en entorno erwin
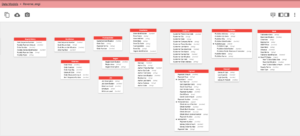
Siga ajustando sus modelos periódicamente para asegurarse de que están optimizados para ofrecer el mejor rendimiento.
El modelado de datos mediante erwin le ayudará a acelerar su tiempo de comercialización, le proporcionará la interfaz para visualizar su proceso de modelado y mejorará enormemente la precisión de sus modelos. Mejores modelos de datos garantizan un mejor rendimiento y un éxito más sólido con Couchbase.
Comparta aquí sus comentarios o póngase en contacto con nosotros en forums.couchbase.com.