La migración de datos es lleno de retos.
Cuando se migra desde una base de datos relacional (RDBMS) como SQL Server u Oracle, el principal reto llega a la hora de desnormalizar los documentos migrados según los modelos de datos de destino. Con la introducción de ámbitos y colecciones en la versión 7.0 de Couchbase Server es fácil clasificar y organizar los documentos dentro de un cubo.
Hay muchas opciones disponibles para migrar datos de SQL Server u Oracle a Couchbase, incluyendo:
-
- Importar CSV/JSON a Couchbase utilizando
cbimport. - Escribir un código ETL personalizado para mover datos de RDBMS a Couchbase.
- Importar CSV/JSON a Couchbase utilizando
En la mayoría de los casos cbimport es suficiente para completar la migración de datos de una base de datos Oracle o SQL Server a Couchbase porque cbimport puede importar documentos a un ámbito y colección requeridos
En este artículo, voy a cubrir cómo se puede utilizar Consultas SQL (referido más adelante como N1QL) en Couchbase 7.0 para fusionar/desnormalizar documentos importados de múltiples colecciones dentro de un ámbito.
Información general
En primer lugar, vamos a revisar los paralelismos entre las entidades RDBMS y sus entidades equivalentes en Couchbase Server 7.0:
| Entidad RDBMS | Equivalente de Couchbase |
| Base de datos | Cubo |
| Esquema | Alcance |
| Cuadro | Colección |
| Fila | Documento |
| Columna | Atributo |
La migración de datos de un RDBMS a Couchbase puede tener dos variantes:
- Mapeo uno a uno: Cada tabla RDBMS se importa a una colección en Couchbase y cada fila de esa tabla se convierte en un documento JSON. Se trata de la migración más sencilla, ya que no requiere ninguna desnormalización y todo el proceso puede completarse utilizando
cbimportsólo. - Cartografía múltiple: Múltiples tablas de una base de datos RDBMS se combinan en un único documento Couchbase, o podemos decir que las tablas RDBMS normalizadas se desnormalizan en documentos Couchbase. Para lograr la desnormalización, tenemos múltiples opciones, tales como:
- Desnormalización en origen: Esto significa exportar datos desde Oracle/SQL Server en formato JSON y que la estructura de ese JSON coincida con el modelo de datos de Couchbase de destino. Luego importas ese documento JSON exportado a Couchbase usando
cbimport. Sin embargo, esto no siempre es posible, porque hay que trabajar con algunas consultas complejas para generar el modelo de datos de destino. Además, la exportación JSON no siempre es compatible con todas las bases de datos. - Desnormalización en la capa media: Esto es posible sólo si estás usando algún código personalizado (cualquier lenguaje de programación como C#, Java, etc.) para mover datos de RDBMS a Couchbase. De esta manera, tu código se conecta a la base de datos de origen, lee los datos de la fuente, modifica los datos según el modelo de datos de Couchbase de destino, y luego escribe los datos en Couchbase. Sin embargo, esto requiere mucho trabajo de desarrollo ya que debes escribir código para cada modelo de datos de destino.
- Desnormalización en destino: En esta opción, se mueven los datos de RDBMS a Couchbase utilizando
cbimporto por otros medios. A continuación se escriben algunas consultas N1QL personalizadas para realizar la desnormalización a nivel de Couchbase. Esta es una opción adecuada en caso de que el modelo de datos de destino tenga un máximo de tres o cuatro niveles de anidamiento de hijos. Puedes optar por esta opción incluso si tu anidamiento tiene más de tres o cuatro niveles, pero eso introduce más complejidad.
- Desnormalización en origen: Esto significa exportar datos desde Oracle/SQL Server en formato JSON y que la estructura de ese JSON coincida con el modelo de datos de Couchbase de destino. Luego importas ese documento JSON exportado a Couchbase usando
Ejemplo práctico: Migración de Datos de RDBMS a Couchbase con Desnormalización en Destino Usando N1QL
Para demostrar esta actividad de migración y desnormalización, he creado una base de datos de ejemplo en SQL Server que contiene cinco nombres de tablas: [Cliente], [Dirección], [Orden], [OrderDetails]y [ProductDetails]. A continuación se muestra el diagrama de la base de datos para mostrar las relaciones y los detalles de las columnas:
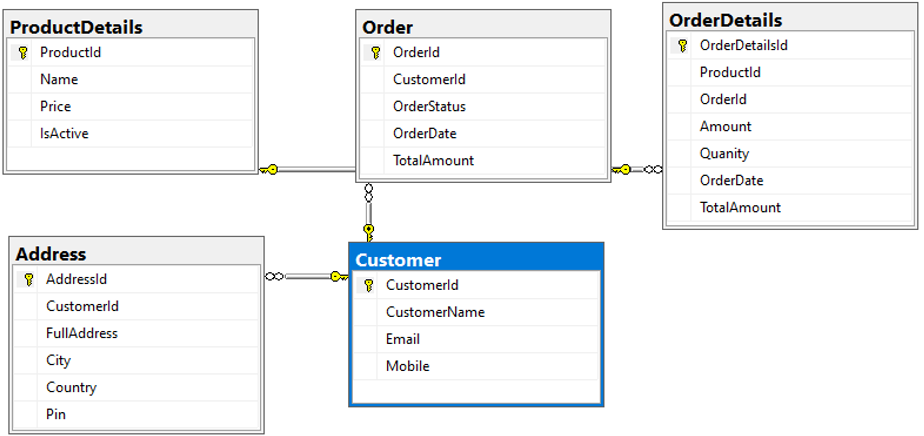
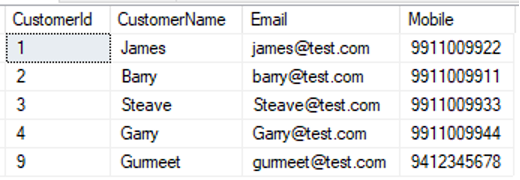
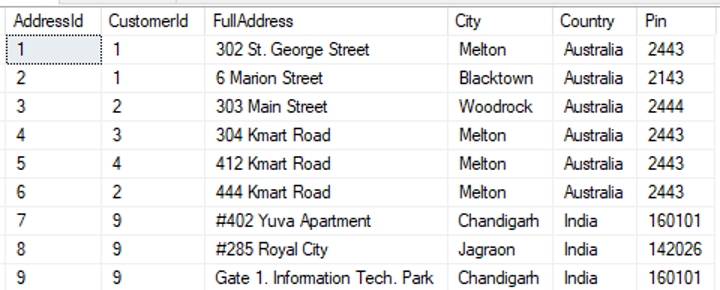
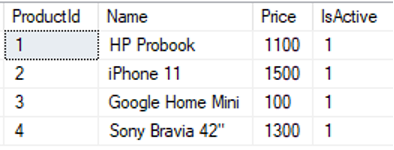
A continuación se muestran los datos de muestra cargados en cada tabla:
select * from [dbo].[Cliente] |
 |
select * from [dbo].[Dirección] |
 |
select * from [dbo].[ProductDetails] |
 |
select * from [dbo].[Pedido] |
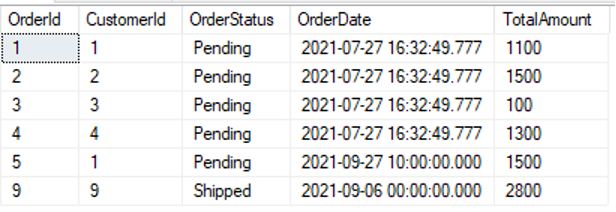 |
select * from [dbo].[DetallesDePedido] |
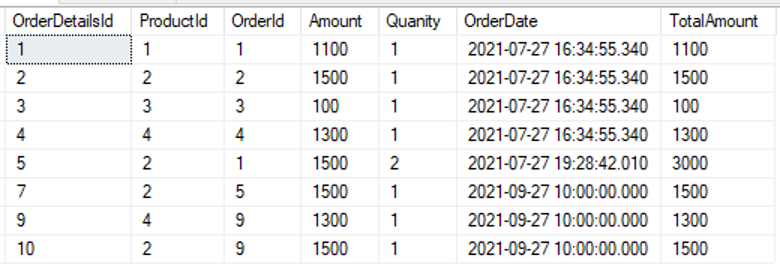 |
Configuración de Couchbase 7.0: He instalado Couchbase 7.0 en una máquina Windows y mi cluster de prueba está listo. He creado un bucket llamado testBucket. Además, he creado un ámbito llamado dbo correspondiente al esquema RDBMS y, a continuación, creamos cinco colecciones en el directorio dbo alcance. En este caso, los nombres de las colecciones son los mismos que los de las tablas del RDBMS. Sin embargo, esto no es obligatorio; el ámbito y los nombres de las colecciones pueden ser cualquier cosa de su elección.
A continuación, importo todas las tablas RDBMS a este ámbito (dbo) utilizando cbimport.
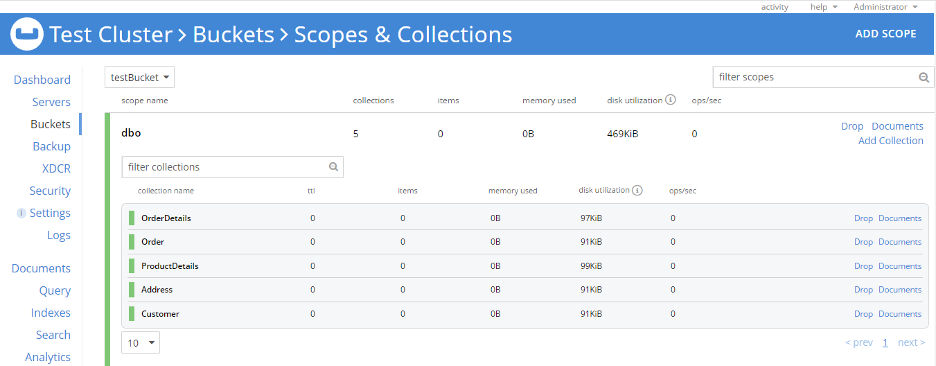
Preparemos la importación de datos a Couchbase:
Primer paso: Exporte datos de tablas a CSV mediante el asistente de exportación de SQL Server.
Segundo paso: Importación de documentos a Couchbase mediante cbimport:
Abra el símbolo del sistema de Windows y rediríjase a C:Archivos de programaCouchbase\Server\bin y ejecuta cbimport mando. Por favor, consulte esta documentación para obtener más información sobre cbimport sintaxis. A continuación se muestra el ejemplo para importar el Cliente.csv que se encuentra en la ruta D:/CSV en el dbo ámbito y Recogida de clientes. Aquí la clave del documento es Id de cliente recogido del CSV Nombre de columna CustomerId.

Del mismo modo, podemos importar Dirección, Detalles del producto, Pida y Detalle de pedido CSV en las colecciones correspondientes dentro del dbo alcance. En este momento, tenemos cinco colecciones en dbo y cada colección contiene documentos (resaltados a continuación).
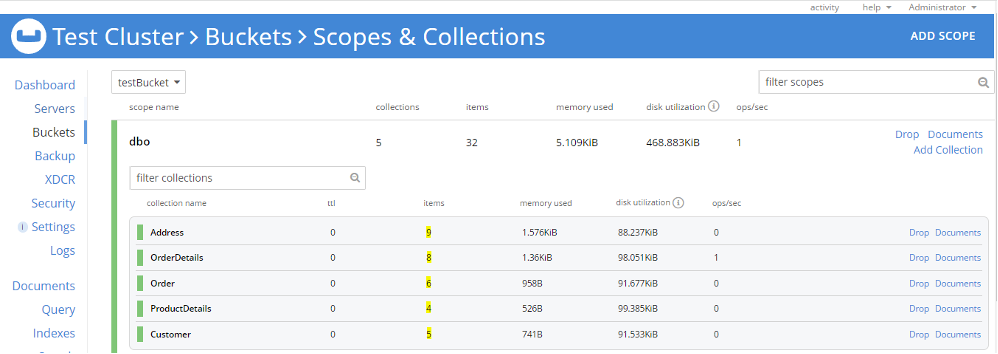
Paso 3: Verifiquemos los datos importados. Podemos hacer este paso mirando el documento a través de la interfaz de usuario o podemos verificar la estructura del documento utilizando N1QL. He creado cinco índices primarios de cada colección para ejecutar una consulta N1QL de verificación de documentos. La verificación puede realizarse cotejando el número de documentos importados, así como la estructura, los atributos y los datos del documento.
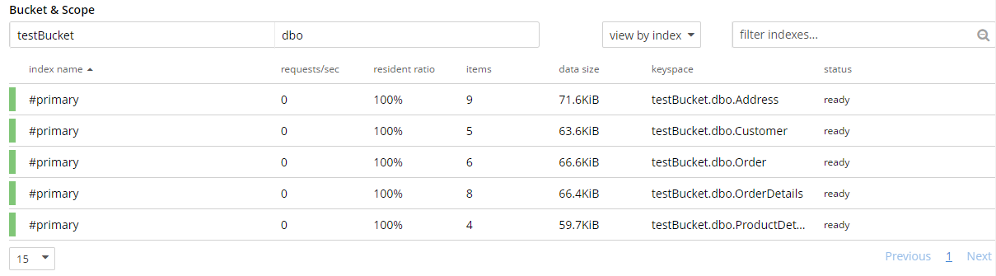
Nota: Para ejecutar una consulta N1QL, debe haber algún índice presente (primario o secundario) para esa colección.
A continuación se muestra el resultado de la consulta N1QL para cada colección (he cambiado la vista del resultado de la consulta a "tabla"):
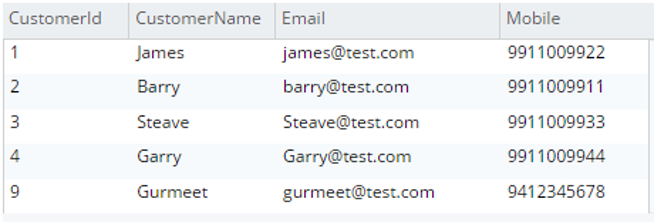
Seleccione c.* de testBucket.dbo.Cliente c |
 |
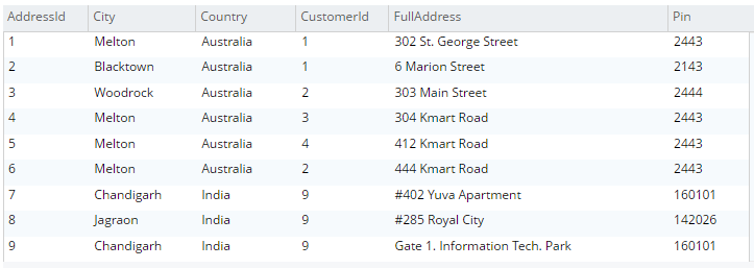
Seleccione a.* de testBucket.dbo.Dirección a |
 |
Seleccione p.* de testBucket.dbo.Detalles del producto |
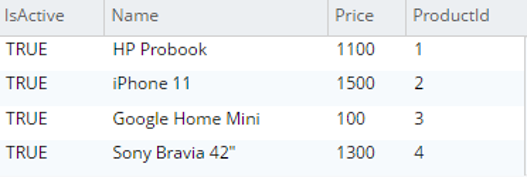 |
Seleccione o.* de testBucket.dbo.Pida o |
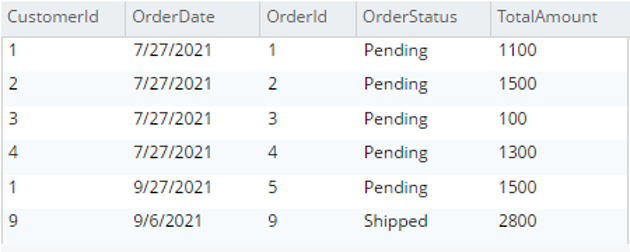 |
Seleccione od.* de testBucket.dbo.Detalles del pedido |
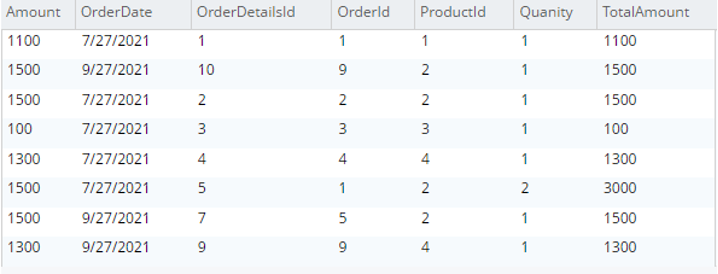 |
Los documentos se importan correctamente, pero se trata de una correspondencia uno a uno, es decir, cada tabla se importa como una colección. Para las tablas en las que sólo necesitamos una correspondencia de uno a uno (por ejemplo, Detalles del producto); la migración de datos se completa en este paso.
Sin embargo, para las tablas en las que necesitamos realizar una desnormalización hay algunos pasos más antes de obtener nuestro modelo de datos final. Por ejemplo, las tablas RDBMS Cliente, Dirección, Pida y Detalles del pedido deben fusionarse en un único documento. Su modelo de datos de destino debe ser algo como:
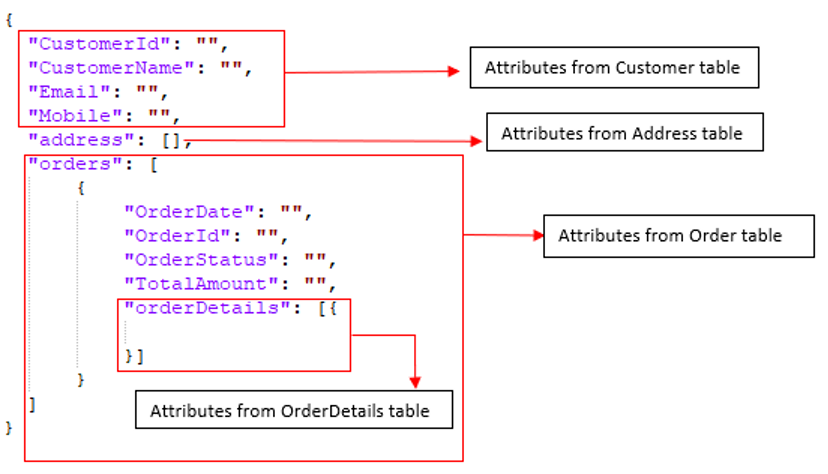
Paso 4: Para la desnormalización en el destino de destino (p. ej, Servidor Couchbase), seguiremos un enfoque ascendente. Primero fusionaremos Detalles del pedido en Pidaentonces fusionaremos Pida y Dirección en Cliente.
Preparemos una consulta N1QL para fusionar Detalles del pedido en un Pida documento. Para ello, utilizaremos grupo por y ARRAY_AGG y la consulta devolverá una matriz de detalles del pedido agrupados por Id de pedido.
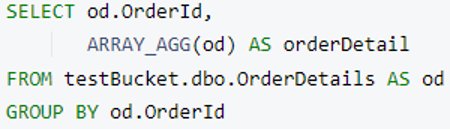
Nota: Puede utilizar palabra clave límite después de grupo por para restringir el tamaño de los resultados y acelerar la ejecución en datos de gran tamaño.
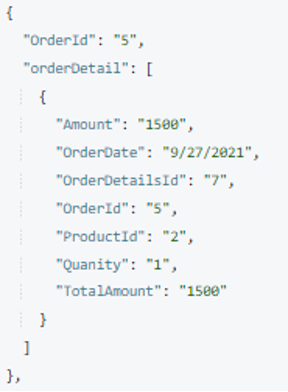
Ahora tenemos el detallesdelpedido lista. Es hora de fusionarlo en un Pida documento. Utilizaremos el Couchbase FUSIONAR declaración para realizar esta operación. Aquí estamos añadiendo un nuevo atributo llamado detalle de pedido en cada Pida documento cuando Order.OrderId y OrderDetails.OrderId coinciden.
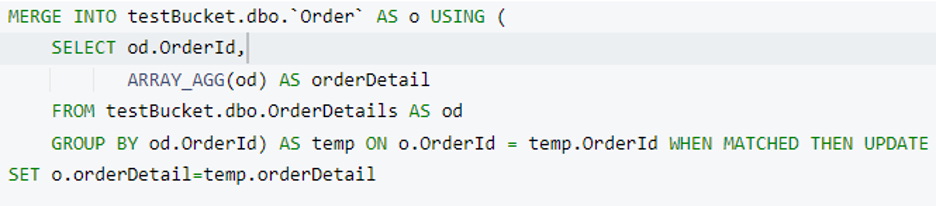
Antes de ejecutar esta consulta, echemos un vistazo a los índices que necesitamos para ella. Nuestras consultas anteriores deberían funcionar con el índice primario, pero para la parte de fusión, debemos crear un índice secundario. No te preocupes, el asesor de índices de Couchbase nos ayudará.
Copie la consulta anterior en el Query Workbench y haga clic en el botón "Index Advisor". Se mostrará automáticamente el creación de índices que se necesita para ejecutar esta consulta.
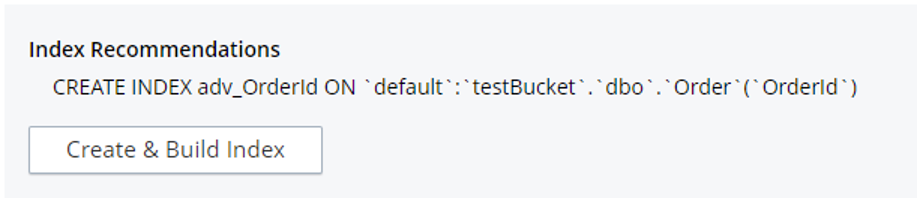
Estoy tomando una referencia del asesor de índice y anexando un DONDE para crear un índice parcial en Pida colección.

Este índice parcial sólo abarca los Pida documentos en los que el detalle de pedido no aparece. En caso de que tengamos millones de Pida documentos, el número de documentos de este índice empezará a reducirse cuando ejecutemos fusionar en trozos (utilizando la función LÍMITE palabra clave). Por ejemplo, en este momento tenemos seis documentos cubiertos por este índice.
Creación de un índice secundario en el Detalle de pedido es similar, como se muestra a continuación.

Ahora tenemos dos índices en estado listo.

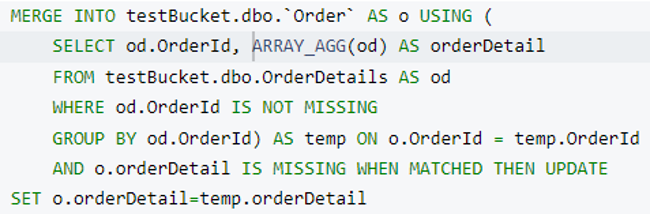
A continuación, vamos a ejecutar un fusionar con una límite cláusula. He actualizado la donde en la subconsulta (donde od.OrderId no falta) para seleccionar el índice apropiado durante la ejecución.
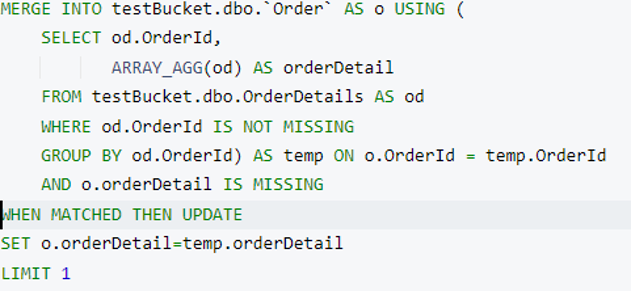
Esta declaración actualizará una Pida y añadir el documento asociado detallesdelpedido como documento hijo. En mi caso, eligió el Pida documento con orderId=2 y lo actualicé. Nº pedido 2 sólo tiene un detallesdelpedido por lo que lo añadió como una matriz.
Echemos un vistazo al índice. El número de documentos ha disminuido de seis a cinco. Esto se debe a que un documento no cumple la condición del índice parcial. Este índice se actualizará como pedir se actualizan los documentos.

Ahora quite el Límite y ejecute una cláusula fusionar consulta para actualizar todos pedir documentos.
Esta afirmación aporta la adv_OrderId índice de documentos a cero, ya que todos los Pida tienen ahora un atributo detalle de pedido.

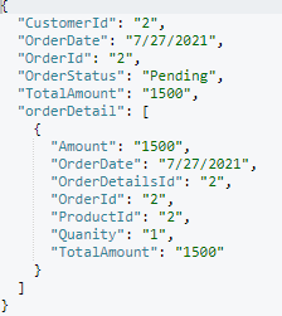
Elegí uno al azar pedir documento (orderId=9) y he incluido el resultado a continuación.
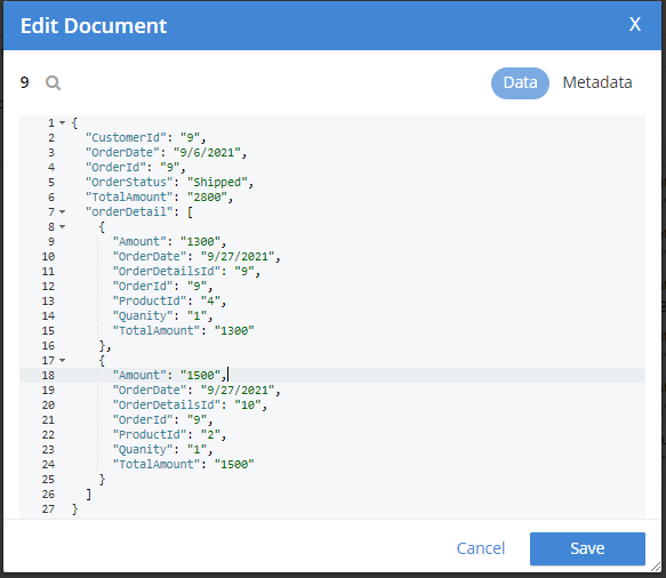
Ahora tenemos un Pida documento listo con su hijo para fusionarse en Cliente. Modifiquemos nuestro fusionar y crear los índices adecuados para la ejecución de la consulta:
El índice para la consulta/subconsulta interna:

El índice parcial de Cliente colección:
![]()
En fusionar consulta para fusionar Pedidos en Cliente:
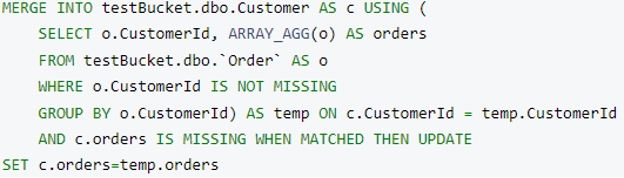
Después de la ejecución, este es el cliente estructura del documento (elegida al azar):
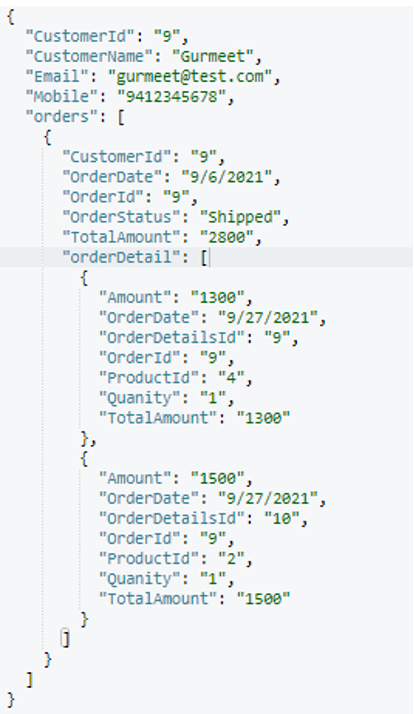
Hasta aquí, hemos conseguido la desnormalización del pedir, detalle de pedido y Cliente tablas. Ahora vamos a fusionar dirección como una matriz en Cliente como a los demás.
Creación del índice para el Cliente colección:
![]()
Creación del índice para el dirección colección:

En fusionar consulta para fusionar dirección en Cliente:
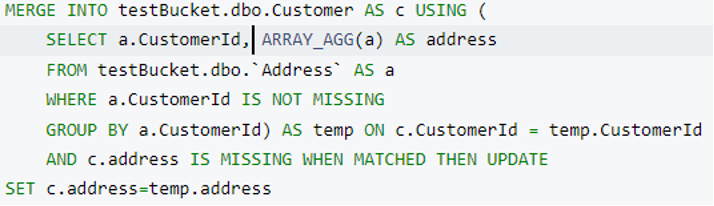
Tras ejecutar esta consulta, obtendremos nuestro modelo de datos final que está compuesto por cuatro tablas RDBMS.
-
Clienteserá el documento principal.Direcciónserá una matriz de objetos incrustados encliente.Pidaserá una matriz de objetos incrustados encliente.Detalles del pedidoserá una matriz de objetos incrustados en cadapedirobjeto.
Estructura final del cliente documento:

Por último, hemos logrado la desnormalización según nuestro modelo de datos objetivo utilizando consultas N1QL.
Podemos modificar la subconsulta para seleccionar una serie de atributos/columnas en lugar de *. Además, podemos utilizar Funciones de objetos Couchbase para añadir/eliminar cualquier atributo en la subconsulta/resultado padre.
Paso 5 (opcional): Ahora es el momento de limpiar. Ya que tenemos nuestro modelo de datos de destino con nosotros en el Cliente podemos eliminar las otras tres colecciones (dirección, pedir y detallesdelpedido).
Conclusión
En resumen, la desnormalización en destino puede lograrse utilizando el lenguaje de consulta N1QL junto con los índices apropiados. Se puede utilizar para cualquier nivel de anidamiento según sus necesidades, empezando por los datos secundarios más bajos de su modelo de datos.
