A migração de dados é cheio de desafios.
Ao migrar de um banco de dados relacional (RDBMS) como o SQL Server ou o Oracle, o principal desafio surge no momento de desnormalizar os documentos migrados de acordo com os modelos de dados de destino. Com a introdução de escopos e coleções no a versão 7.0 do Couchbase Server é fácil categorizar e organizar documentos em um compartimento.
Há muitas opções disponíveis para migrar dados do SQL Server ou Oracle para o Couchbase, incluindo:
-
- Importação de CSV/JSON para o Couchbase usando
cbimport. - Escrever um código ETL personalizado para mover dados do RDBMS para o Couchbase.
- Importação de CSV/JSON para o Couchbase usando
Na maioria dos casos cbimport por si só é suficiente para concluir a migração de dados de um banco de dados Oracle ou SQL Server para o Couchbase porque cbimport pode importar documentos para um escopo e uma coleção necessários
Neste artigo, abordarei como você pode usar o Consultas SQL++ (referido abaixo como N1QL) no Couchbase 7.0 para mesclar/desnormalizar documentos importados de várias coleções em um escopo.
Informações básicas
Primeiro, vamos analisar os paralelos entre as entidades RDBMS e suas entidades equivalentes no Couchbase Server 7.0:
| Entidade RDBMS | Equivalente ao Couchbase |
| Banco de dados | Balde |
| Esquema | Escopo |
| Tabela | Coleção |
| Linha | Documento |
| Coluna | Atributo |
A migração de dados de um RDBMS para o Couchbase pode ter duas variantes:
- Mapeamento um a um: Cada tabela do RDBMS é importada para uma coleção no Couchbase e cada linha dessa tabela se torna um documento JSON. Essa é a migração mais simples, pois não requer nenhuma desnormalização e todo o processo pode ser concluído usando
cbimportsomente. - Mapeamento de muitos para um: Várias tabelas de um banco de dados RDBMS são combinadas em um único documento do Couchbase, ou podemos dizer que as tabelas RDBMS normalizadas são desnormalizadas em documentos do Couchbase. Para obter a desnormalização, temos várias opções, como
- Desnormalização na fonte: Isso significa exportar dados do Oracle/SQL Server no formato JSON e a estrutura desse JSON corresponde ao modelo de dados de destino do Couchbase. Em seguida, você importa esse documento JSON exportado para o Couchbase usando
cbimport. No entanto, isso não é possível o tempo todo, porque você precisa trabalhar em algumas consultas complexas para gerar o modelo de dados de destino. Além disso, a exportação JSON nem sempre é suportada por todos os bancos de dados. - Desnormalização na camada intermediária: Isso só é possível se você estiver usando algum código personalizado (qualquer linguagem de programação como C#, Java etc.) para mover dados do RDBMS para o Couchbase. Dessa forma, seu código se conecta ao banco de dados de origem, lê os dados da origem, modifica os dados de acordo com o modelo de dados de destino do Couchbase e, em seguida, grava os dados no Couchbase. No entanto, isso exige muito trabalho de desenvolvimento, pois você precisa escrever código para cada modelo de dados de destino.
- Desnormalização no destino: Nessa opção, você move os dados do RDBMS para o Couchbase usando
cbimportou por outros meios. Em seguida, você escreve algumas consultas N1QL personalizadas para realizar a desnormalização no nível do Couchbase. Essa é uma opção adequada caso o modelo de dados de destino tenha no máximo três ou quatro níveis de aninhamento de filhos. Você pode optar por essa opção mesmo se o aninhamento tiver mais de três ou quatro níveis, mas isso introduz mais complexidade.
- Desnormalização na fonte: Isso significa exportar dados do Oracle/SQL Server no formato JSON e a estrutura desse JSON corresponde ao modelo de dados de destino do Couchbase. Em seguida, você importa esse documento JSON exportado para o Couchbase usando
Exemplo de passo a passo: Migração de dados do RDBMS para o Couchbase com desnormalização no destino usando N1QL
Para demonstrar essa atividade de migração e desnormalização, criei um banco de dados de amostra no SQL Server que contém cinco nomes de tabelas: [Cliente], [Endereço], [Pedido], [OrderDetails]e [Detalhes do produto]. Abaixo está o diagrama do banco de dados para mostrar os relacionamentos e os detalhes das colunas:
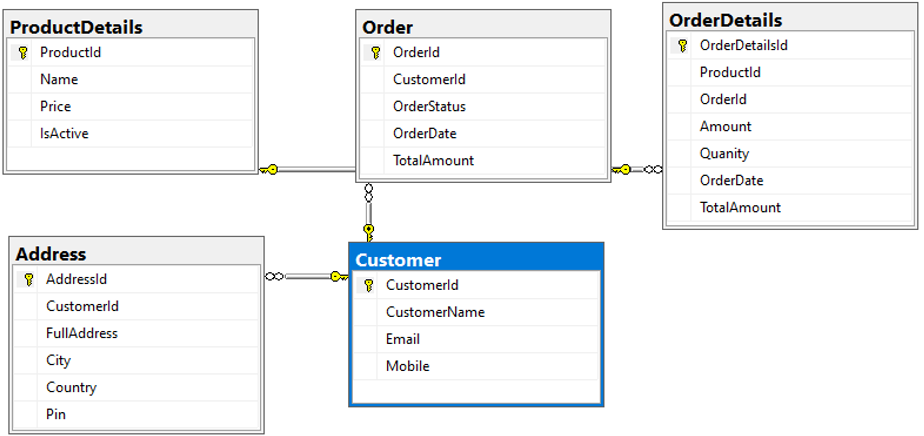
Abaixo estão os dados de amostra carregados em cada tabela:
select * from [dbo].[Customer] |
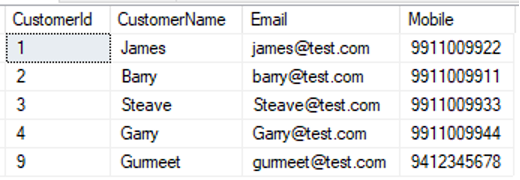 |
select * from [dbo].[Address] |
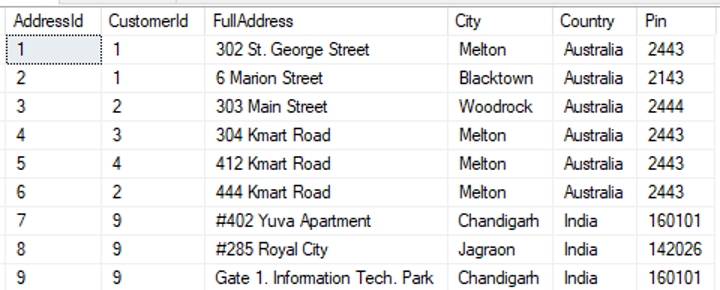 |
select * from [dbo].[ProductDetails] |
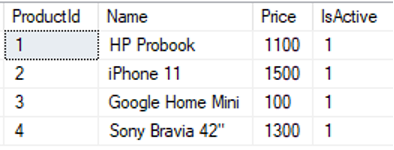 |
select * from [dbo].[Order] |
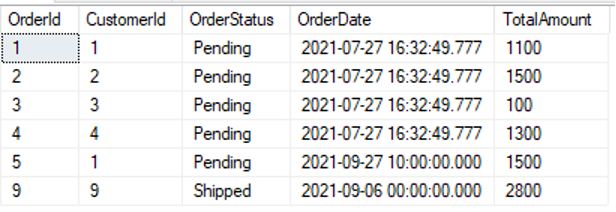 |
select * from [dbo].[OrderDetails] |
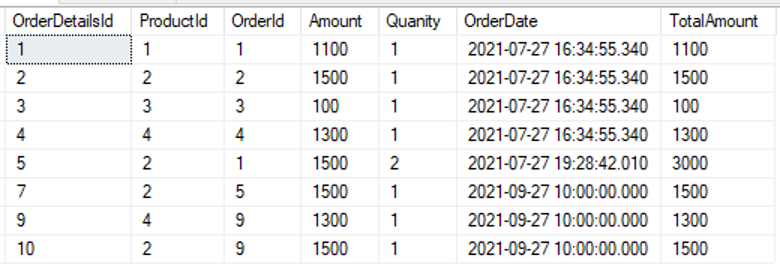 |
Configuração do Couchbase 7.0: Instalei o Couchbase 7.0 em uma máquina Windows e meu cluster de teste está pronto. Criei um bucket chamado testBucket. Além disso, criei um escopo chamado dbo correspondente ao esquema do RDBMS e, em seguida, criou cinco coleções no dbo escopo. Aqui, estou mantendo os nomes das coleções iguais aos nomes das tabelas do RDBMS. No entanto, isso não é obrigatório; os nomes de escopo e coleção podem ser qualquer coisa de sua escolha.
Em seguida, importo todas as tabelas do RDBMS para esse escopo (dbo) usando cbimport.
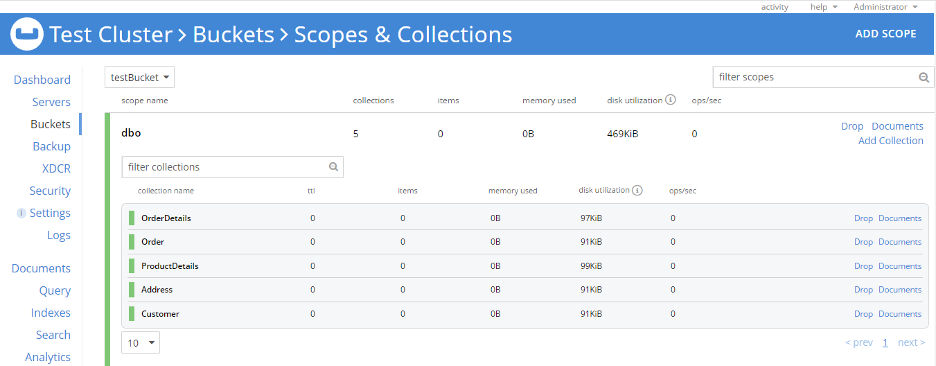
Vamos nos preparar para a importação de dados para o Couchbase:
Etapa 1: Exportar dados de tabela para CSVs usando o assistente de exportação do SQL Server.
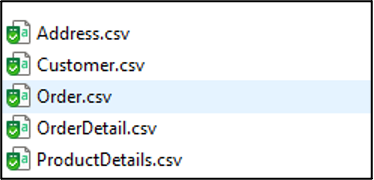
Etapa 2: Importar documentos para o Couchbase usando cbimport:
Abra o prompt de comando do Windows e redirecione para C:\Arquivos de programas\Couchbase\Server\bin e executar cbimport comando. Favor Consulte esta documentação para obter mais informações sobre cbimport sintaxe. Abaixo está o exemplo para importar o Cliente.csv que é colocado no caminho D:/CSVs no dbo escopo e coleta de clientes. Aqui a chave do documento é Identificação do cliente selecionado no CSV Nome da coluna CustomerId.

Da mesma forma, podemos importar Endereço, ProductDetail, Pedido e Detalhes do pedido CSVs em coleções correspondentes dentro do dbo escopo. No momento, temos cinco coleções em dbo e cada coleção tem documentos nela (destacados abaixo).
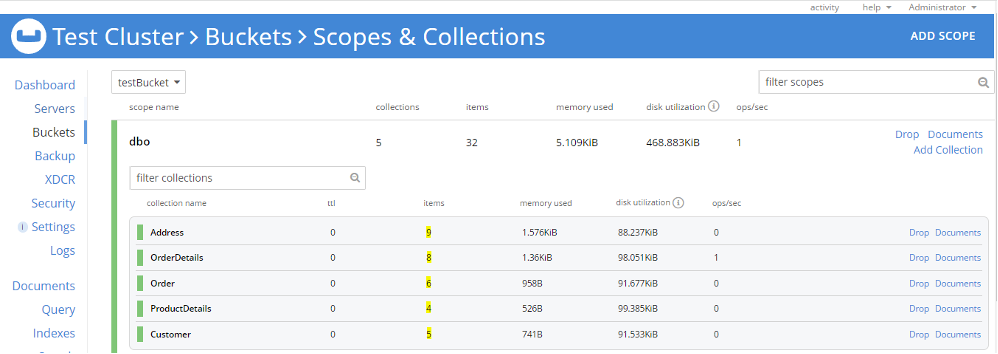
Etapa 3: Vamos verificar os dados importados. Podemos fazer essa etapa examinando o documento por meio da interface do usuário ou verificando a estrutura do documento usando o N1QL. Eu criei cinco índices primários para cada coleção para executar uma consulta N1QL para verificação de documentos. A verificação pode ser feita por meio da correspondência do número de documentos importados, bem como da estrutura, dos atributos e dos dados do documento.
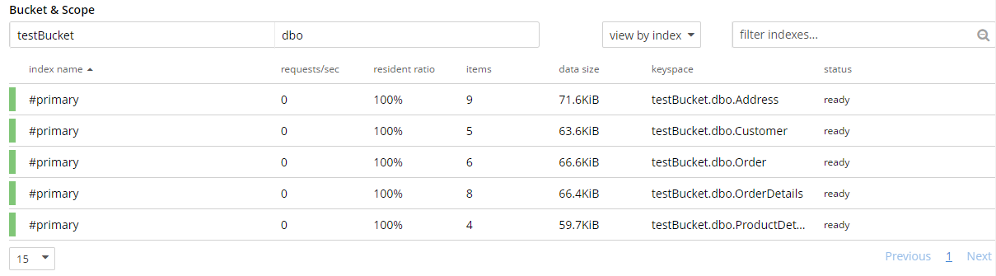
Observação: Para executar uma consulta N1QL, deve haver algum índice presente (primário ou secundário) para essa coleção.
Abaixo está o resultado da consulta N1QL para cada coleção (alterei a visualização do resultado da consulta para "tabela"):
Selecione c.* de testBucket.dbo.Cliente c |
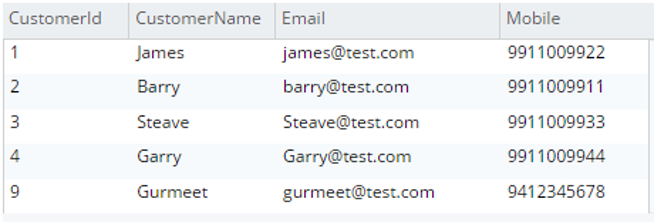 |
Selecione a.* de testBucket.dbo.Endereço a |
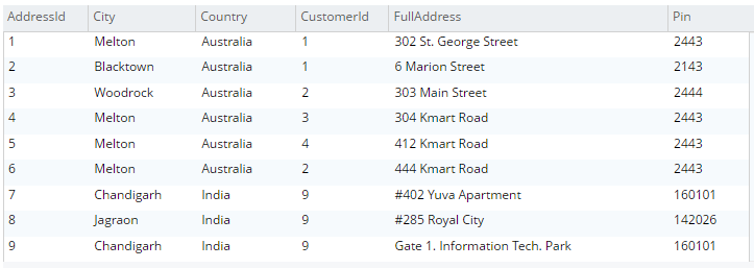 |
Selecione p.* de testBucket.dbo.ProductDetails |
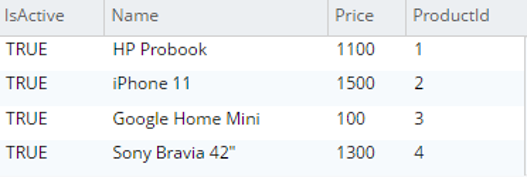 |
Selecione o.* de testBucket.dbo.Pedido o |
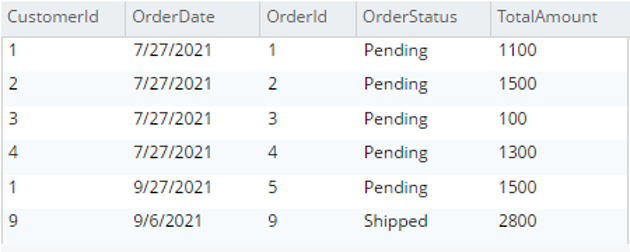 |
Selecione od.* de testBucket.dbo.OrderDetails |
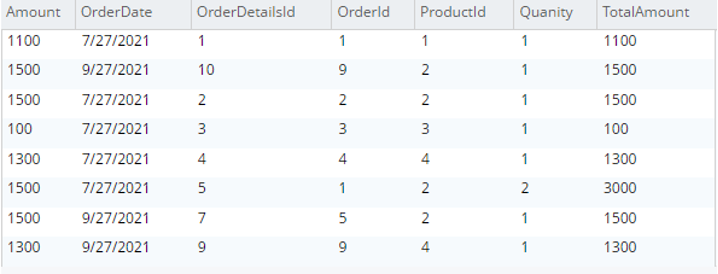 |
Os documentos são importados com sucesso, mas esse é um mapeamento de um para um, ou seja, cada tabela é importada como uma coleção. Para tabelas em que precisamos apenas de mapeamento um-para-um (por exemplo, ProductDetails); a migração de dados é concluída nessa etapa.
No entanto, para tabelas em que precisamos realizar a desnormalização, há mais algumas etapas antes de obtermos nosso modelo de dados final. Por exemplo, as tabelas RDBMS Cliente, Endereço, Pedido e OrderDetails devem ser mesclados em um único documento. Seu modelo de dados de destino deve ser semelhante a:
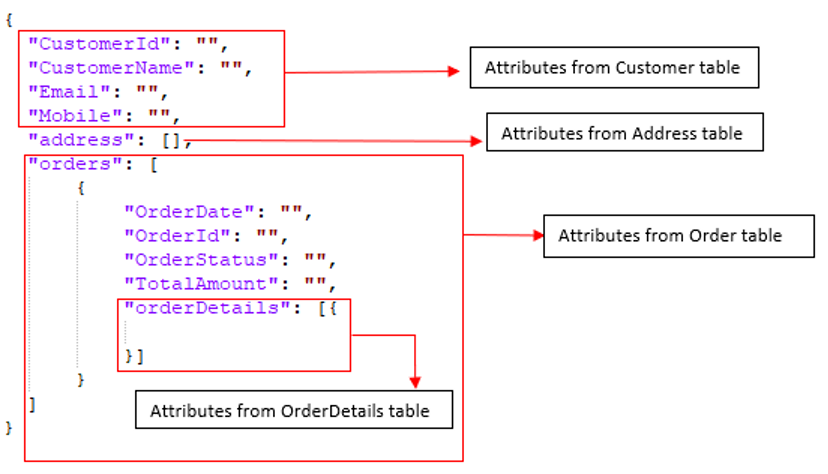
Etapa 4: Para desnormalização no destino de destino (por exemplo, Servidor Couchbase), seguiremos uma abordagem de baixo para cima. Primeiro, mesclaremos OrderDetails em Pedidoe, em seguida, mesclaremos Pedido e Endereço em Cliente.
Vamos preparar uma consulta N1QL para mesclar OrderDetails em um Pedido documento. Para isso, usaremos grupo por e ARRAY_AGG e a consulta retornará uma matriz de detalhes do pedido agrupados por Id do pedido.
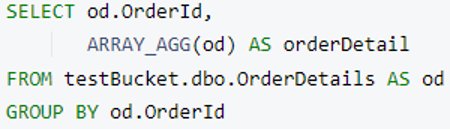
Observação: Você pode usar palavra-chave limit após grupo por para restringir o tamanho do resultado para uma execução mais rápida em dados enormes.
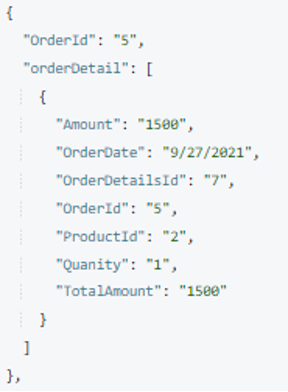
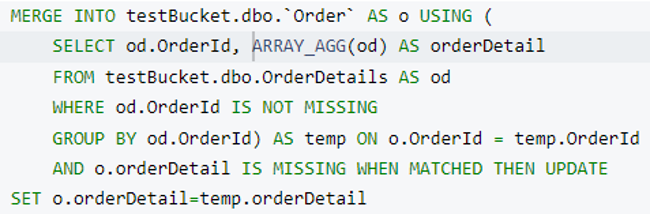
Agora temos o OrderDetails array pronto. É hora de mesclá-lo em um Pedido documento. Usaremos o o Couchbase MERGE declaração para realizar essa operação. Aqui estamos adicionando um novo atributo chamado detalhes do pedido em cada Pedido documento quando Order.OrderId e OrderDetails.OrderId são combinados.
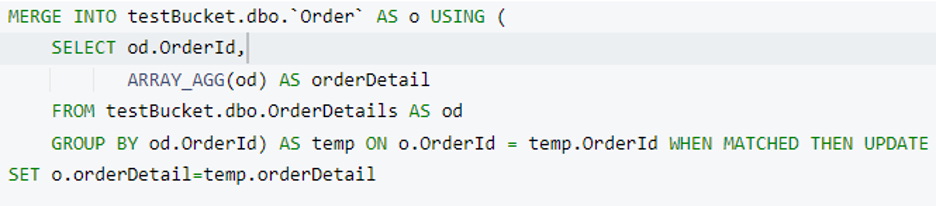
Antes de executar essa consulta, vamos dar uma olhada nos índices necessários para ela. Nossas consultas anteriores devem funcionar com o índice primário, mas para a parte de mesclagem, precisamos criar um índice secundário. Não se preocupe, o consultor de índices do Couchbase nos ajudará.
Copie a consulta acima no Query Workbench e clique no botão "Index Advisor". Ele mostrará automaticamente o criação de índices que é necessária para executar essa consulta.
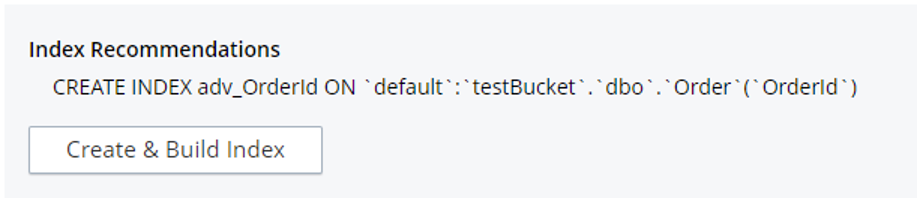
Estou pegando uma referência do consultor de índice e anexando um ONDE para criar um índice parcial no Pedido coleção.

Este índice parcial abrange apenas os Pedido documentos em que o detalhes do pedido está faltando. No caso de termos milhões de Pedido documentos, o número de documentos nesse índice começará a ser reduzido quando executarmos mesclar em blocos (usando o LIMITE palavra-chave). Por exemplo, neste momento, temos seis documentos cobertos por esse índice.
Criação de um índice secundário no Detalhes do pedido é semelhante, como mostrado abaixo.

Agora temos dois índices em um estado pronto.

Em seguida, vamos executar um mesclar com uma declaração limite cláusula. Eu atualizei a onde na subconsulta (onde od.OrderId não estiver faltando) para selecionar o índice apropriado durante a execução.
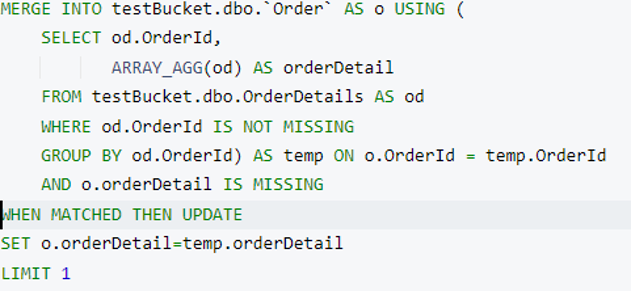
Essa declaração atualizará um Pedido e anexar o documento OrderDetails como um documento filho. No meu caso, ele escolheu o Pedido documento com orderId=2 e o atualizou. Ordem Id 2 tem apenas um OrderDetails portanto, ele o adicionou como uma matriz.
Vamos dar uma olhada no índice. A contagem de documentos diminuiu de seis para cinco. Isso ocorre porque um documento não está satisfazendo a condição do índice parcial. Esse índice será atualizado como ordem documentos são atualizados.

Agora, remova o Limite e executar uma cláusula mesclar para atualizar todos os ordem documentos.
Essa declaração traz o adv_OrderId contagem de documentos de índice para zero, pois todos os Pedido agora têm um atributo detalhes do pedido.

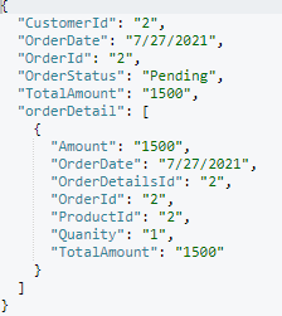
Escolhi uma aleatoriamente ordem documento (orderId=9) e incluiu o resultado abaixo.
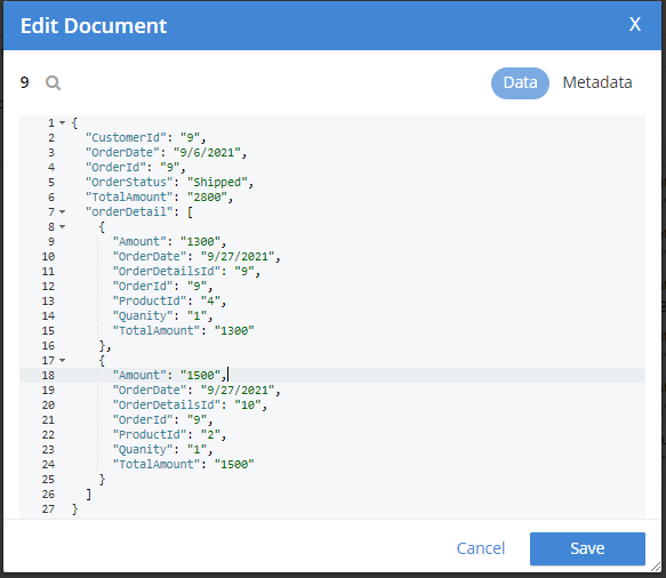
Agora temos um Pedido documento pronto com seu filho para ser mesclado em Cliente. Vamos modificar nosso mesclar consulta de acordo e criar índices apropriados para a execução da consulta:
O índice da consulta/subconsulta interna:

O índice parcial para Cliente coleção:
![]()
O mesclar consulta para mesclar Pedidos em Cliente:
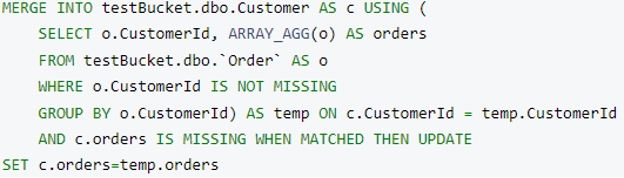
Após a execução, essa é a última cliente estrutura do documento (escolhida aleatoriamente):
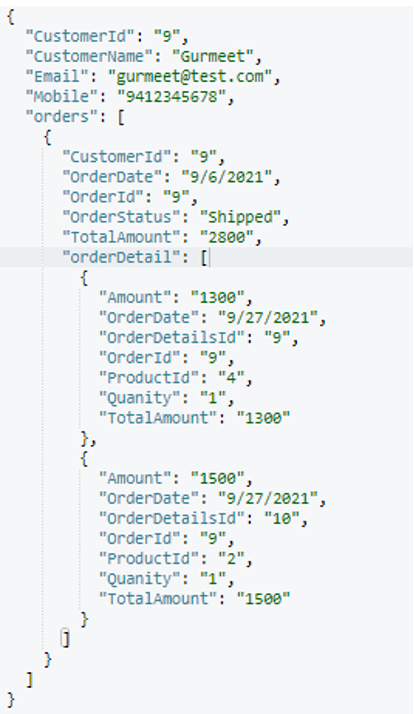
Até este ponto, obtivemos a desnormalização do ordem, detalhes do pedido e Cliente tabelas. Agora vamos mesclar endereço como uma matriz em Cliente como fizemos com os outros.
Criar o índice para o Cliente coleção:
![]()
Criar o índice para o endereço coleção:

O mesclar consulta para mesclar endereço em Cliente:
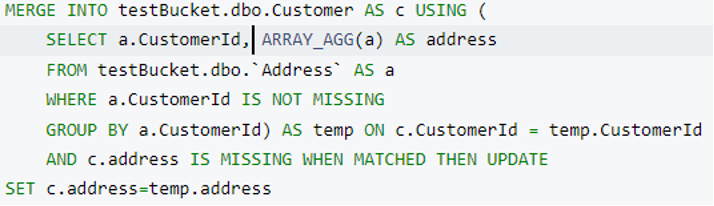
Depois de executar essa consulta, obteremos nosso modelo de dados final, que é composto de quatro tabelas RDBMS.
-
Clienteserá o documento pai.Endereçoserá uma matriz de objetos incorporados emcliente.Pedidoserá uma matriz de objetos incorporados emcliente.OrderDetailsserá uma matriz de objetos incorporada em cadaordemobjeto.
Estrutura final do cliente documento:

Por fim, obtivemos a desnormalização de acordo com nosso modelo de dados de destino usando consultas N1QL.
Podemos modificar a subconsulta para selecionar um número de atributos/colunas em vez de *. Além disso, podemos usar Funções de objeto do Couchbase para adicionar/remover qualquer atributo no resultado da subconsulta/parente.
Etapa 5 (opcional): Agora é hora de fazer a limpeza. Como temos nosso modelo de dados de destino conosco no Cliente podemos excluir as outras três coleções (endereço, ordem e OrderDetails).
Conclusão
Em resumo, a desnormalização no destino pode ser obtida usando a linguagem de consulta N1QL junto com os índices apropriados. Ela pode ser usada para qualquer nível de aninhamento, de acordo com suas necessidades, começando com os dados filhos mais baixos em seu modelo de dados.
