Esta es la tercera parte de una serie que examina Estructuras de datos en bases de datos NoSQL. En este post, utilizamos Búsqueda de texto completo consultas en lenguaje natural contra estructuras de datos en Couchbase.
- Primera parte: Estructuras de datos para aplicaciones NoSQL utilizamos el acceso simplificado a datos JSON a través de colecciones nativas, mapas y mucho más.
- Segunda parte: Estructuras de datos y consultas demostramos la consulta de datos mediante consultas N1QL/SQL.
¿Qué es la indexación de búsquedas de texto completo?
La indexación de búsqueda de texto completo analiza las estructuras de datos basadas en texto de los documentos, registrando las palabras encontradas en cada documento. A continuación, las consultas pueden utilizar el índice para encontrar eficazmente documentos que contengan esos términos de búsqueda cuando se soliciten. Los motores de búsqueda de texto completo utilizan diversos algoritmos de búsqueda para resolver distintos tipos de problemas de búsqueda.
Couchbase utiliza indexación de datos NoSQL y servicios de consulta basados en SQL para recuperar información de estructuras de datos o documentos. Los índices de búsqueda de texto completo y las solicitudes de búsqueda encuentran coincidencias de documentos de una forma más flexible.
Una búsqueda de texto completo devuelve una lista de coincidencias documentos. En cambio, las consultas N1QL devuelven un conjunto de filas. Los índices de texto se conocen como índices invertidos, frente a la indexación tabular que se centra en encontrar filas/columnas con valores específicos.
La búsqueda de texto completo también puntúa y ordena los resultados de la búsqueda para que aparezcan primero los documentos más relevantes.
Una vez creado un índice de texto completo, se actualiza a medida que entran nuevos datos en la base de datos. Los administradores de bases de datos pueden optimizar la indexación para casos de uso específicos: por ejemplo, escrituras de gran volumen frente a consultas de gran volumen, etc.
Estructuras de datos básicas
Hay un puñado de estructuras de datos simples que Couchbase expone: mapas, listas, conjuntos y colas. Cada una está representada por un tipo de datos JSON y almacenada como documentos NoSQL. Ver los otros posts para el acceso básico basado en claves a estos datos.

Ejemplos de estructuras de datos NoSQL primarias
Se pueden indexar campos específicos de las estructuras en función de las necesidades de los usuarios/aplicaciones. Cuando se solicita una búsqueda, la cadena se compara con los índices y se devuelve una lista de documentos coincidentes.
Sólo las estructuras basadas en mapas tienen nombres de campo, las estructuras de contadores y listas no. Por lo tanto, sólo los mapas pueden ser indexados. Es posible que una lista también tenga un mapa en su interior, lo que también funcionaría.
Creación de datos de muestra
Usando el SDK de Python creamos algunas estructuras específicas para los propósitos de este post. Ver entrada anterior para obtener instrucciones detalladas, aquí se muestra un código sencillo por brevedad. La idea aquí es que usted está construyendo un perfil de usuario, añadiendo más información a medida que esté disponible.
|
1 2 3 4 5 |
<span estilo="font-weight: 400">Mapa #</span> <span estilo="font-weight: 400">>>> db.map_add("tylerM","nombre","Tyler", crear=Verdadero)</span> >>> db.map_add("tylerM","dirección",{"ciudad": "kelowna", "país":"Canada"}) >>> db.map_add("tylerM","top3",["galaga","tetris","mazmorras"]) |
Búsqueda de texto completo Estructuras de datos
La búsqueda de texto en Couchbase es similar al uso de estructuras de datos con N1QL en que también requiere un índice. Los índices de búsqueda varían significativamente en complejidad dependiendo de los documentos de la base de datos y del caso de uso. La interfaz web integrada Buscar en facilita la creación de nuevos índices de búsqueda.
Véase Buenas prácticas de indexación en la búsqueda de texto completo para obtener información más detallada.
Indexación de estructuras de datos
Aquí creamos un índice para los campos concretos que sabemos que existen en los datos. Incluyendo el por defecto permite indexar los nuevos campos a medida que entran en línea. Es posible que desee desactivar esta función al optimizar para la producción. Además, he elegido la opción tienda para cada campo, que mostrará el texto coincidente y no sólo la lista de documentos al realizar la búsqueda.
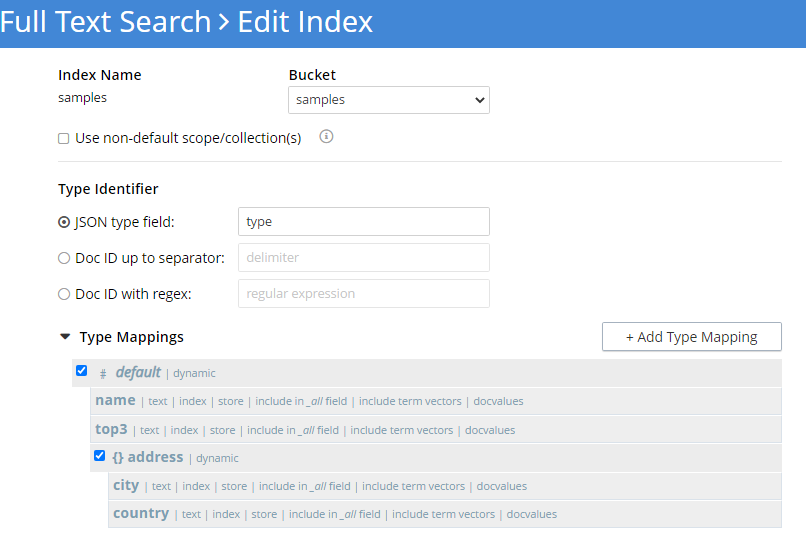
Búsqueda de texto completo en Couchbase creación de índices para las entradas del mapa de datos.
Tras crear el índice de búsqueda, aparece una barra de búsqueda en la que introducir texto básico. Las consultas más avanzadas (emparejamiento difuso(prefix match, geospatial) se puede hacer usando la API REST o el SDK de Couchbase.
Búsqueda de estructuras de datos
Utilizando la herramienta de búsqueda incorporada, podemos encontrar los objetos de estructura de datos que coincidan con el texto introducido. Si actualizamos las estructuras de datos del mapa, los valores cambiarán automáticamente sin necesidad de indexarlos.
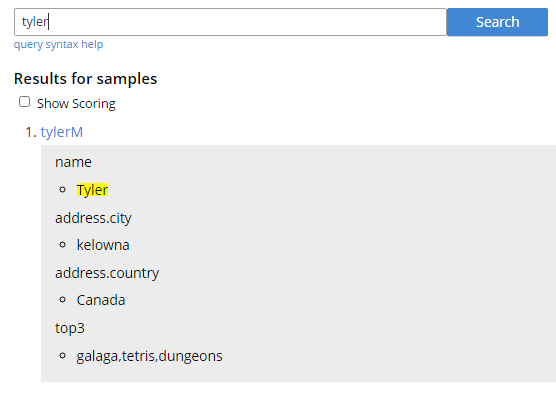
Búsqueda en una estructura de datos de Couchbase a través de la interfaz web
En este ejemplo, buscamos una sola palabra/término y encontramos una coincidencia en la carpeta nombre campo. Si sólo hubiera documentos con ese término -en cualquier campo- también los devolvería.
También se puede especificar un campo en el cuadro de búsqueda con un prefijo, incluido un punto para especificar elementos hijos dentro de otro. Por ejemplo: dirección.país:Canadá. Aquí también se pueden utilizar rangos numéricos, por ejemplo, he añadido otro usuario a mi base de datos y he añadido un nuevo campo al mapa. Dado que el tylerM mapa no lo incluía, sólo el nuevo jugador1 se devuelve el artículo.
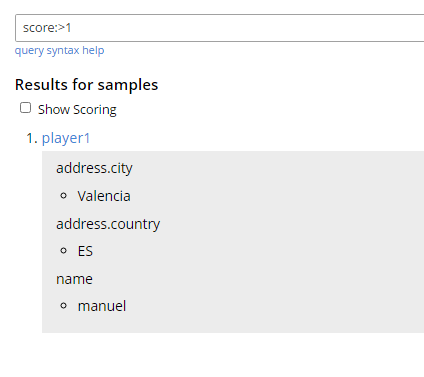
Alcance de campo con búsqueda de rango numérico.
Me devolvía el documento coincidente y los campos que había indexado específicamente. El sitio puntuación no se ha almacenado explícitamente en el índice, aunque sí se ha indexado para poder encontrar documentos coincidentes.
SDK de búsqueda de texto completo (Python)
Los desarrolladores utilizarán el SDK de Couchbase Search para realizar llamadas directas a la base de datos desde sus aplicaciones. El SDK devuelve una lista de documentos que coinciden con el texto junto con sus valores de puntuación de relevancia.
Para más información sobre el SDK de su idioma, consulte Búsqueda de texto completo en los documentos.
Todos los lenguajes soportados por el SDK de Couchbase pueden hacer búsquedas con métodos personalizados para cada tipo de consulta. Este código Python incluye el proceso básico de conexión y búsqueda que replica los ejemplos anteriores.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
de couchbase.grupo importar Grupo, ClusterOptions, Opciones de consulta, PasswordAuthenticator importar couchbase.busque en como FT CONNSTR = "couchbase://localhost"; CUBO = "muestras"; ÍNDICE = "muestras"; BUSCAR = "Tyler" autentificador = PasswordAuthenticator("Administrador", "Administrador") grupo = Grupo(CONNSTR, ClusterOptions(autentificador)) cubo_estático = grupo.cubo(CUBO) db = cubo_estático.colección_por_defecto() qp = FT.QueryStringQuery(BUSCAR) q = grupo.consulta_buscada(ÍNDICE, qp, límite=100) resultados=[] para r en q.filas(): imprimir(BUSCAR, "Encontrado en doc:", r.id, "PUNTUACIÓN:", r.puntuación) |
Produce los detalles del único documento que coincidió:
|
1 |
tyler Encontrado en doc: tylerM PUNTUACIÓN: 0.11597946228887497 |
Ámbitos y colecciones en la búsqueda
Con el lanzamiento de Couchbase 7.0, los subconjuntos de documentos en ámbitos y colecciones son ahora posibles. Cuando se crea un índice usando la consola web, hay una opción "usar ámbitos no predeterminados" para marcar. Seleccionas un ámbito del desplegable y luego creas un nuevo mapeo de tipos para especificar una colección concreta.
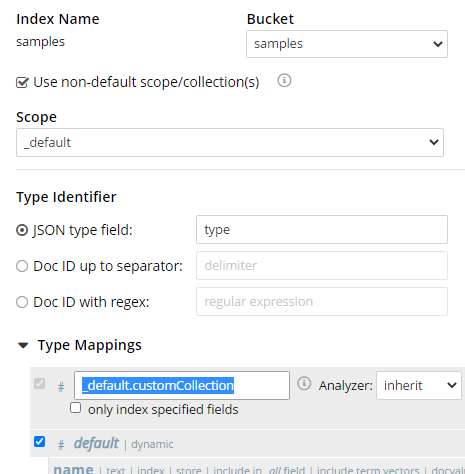
Selección de un ámbito y una colección para el índice de búsqueda.
No vamos a entrar en ello aquí, pero la búsqueda a nivel de ámbito y de colección con un SDK utiliza propiedades a nivel de conexión.
|
1 |
dbscoped = grupo.cubo(muestra-viaje).alcance(por defecto).colección(Colección personalizada) |
Unirlo todo
La creación de documentos, mapas y otras estructuras de datos es muy sencilla con algunos usos básicos del SDK. Asimismo, mediante el uso estratégico de métodos de indexación de búsqueda de texto, existen aún más formas de acceder a los datos que gestionan tus aplicaciones.
En la práctica, las matrices JSON básicas, las cadenas, etc. se pueden mapear e indexar para su uso en otros métodos de acceso.
Como Couchbase es una plataforma que lo incluye todo, la arquitectura de tu sistema puede simplificarse enormemente. Los desarrolladores pueden empezar de inmediato sin mucho trabajo pesado.
- Parte 1 Estructuras de datos y algoritmos para aplicaciones NoSQL
- Parte 2 Estructuras de datos y consultas con Couchbase N1QL (SQL para JSON)
- Mejores prácticas de indexación de búsquedas de texto completo NoSQL
- API de estructuras de datos de Couchbase (SDK de Python)
- Mejores prácticas de indexación de sistemas de bases de datos NoSQL