IA Generativa (GenAI) tiene el potencial de automatizar actividades laborales que actualmente ocupan entre el 60 y el 70 por ciento del tiempo de los empleados, lo que se traduce en un aumento sustancial de la productividad en diversos sectores. Sin embargo, el conocimiento de una LLM de propósito general (GP) se limita a sus datos de entrenamiento, lo que provoca que "alucine" proporcionando respuestas incompletas o inexactas. Esto socava la confianza y la credibilidad, impidiendo que muchas Pruebas de Concepto (POC) de GenAI lleguen a la producción. Introduciendo la técnica de Generación Aumentada por Recuperación (RAG) podemos aumentar el LLM con datos propios que fundamentan las respuestas del LLM en hechos actuales y fiables. El éxito de la implementación de RAG requiere una base de datos altamente escalable y fiable que sirva como base de conocimiento, base de datos vectorial y caché LLM, junto con una plataforma robusta para desarrollar y escalar aplicaciones GenAI utilizando los principales modelos de cimentación.
Couchbase y Amazon Bedrock ofrecen conjuntamente una plataforma integral para crear sin problemas aplicaciones RAG de alto rendimiento en sectores como el comercio minorista, la sanidad, la hostelería, el juego y muchos otros.
Couchbase CapellaDBaaS (base de datos como servicio) nativa en la nube y de alto rendimiento, le permite empezar rápidamente a almacenar, indexar y consultar datos operativos, vectoriales, de series temporales, textuales y geoespaciales para sus aplicaciones RAG, al tiempo que aprovecha la flexibilidad de JSON. Además, ofrece de forma exclusiva búsqueda híbridaque lleva la búsqueda semántica al siguiente nivel combinando la búsqueda tradicional y vectorial en una única consulta SQL++ para potenciar aplicaciones que requieren una búsqueda muy granular con una alta especificidad de selección. Esta capacidad abarca la nube, el perímetro y los dispositivos móviles. Capella se puede integrar fácilmente como base de conocimientos, base de datos vectorial o base de datos vectorial. Caché LLM con una plataforma GenAI líder como Amazon Bedrock mediante marcos de orquestación como LangChain o LlamaIndex para crear una canalización RAG de nivel de producción. Amazon Bedrock es un servicio totalmente administrado que ofrece una selección de modelos básicos (FM) de alto desempeño de empresas líderes en inteligencia artificial (IA) como AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI y Amazon mediante una única API, junto con un amplio conjunto de capacidades que necesita para crear aplicaciones de IA generativa con seguridad, privacidad e IA responsable.
En este blog, presentamos una aplicación de chatbot potenciada por RAG construida utilizando Búsqueda vectorial en Couchbase y Amazon Bedrock. Aprovecha Couchbase datos de la muestra de viajes almacenados en Couchbase Capella y el modelo Anthropic Claude de Amazon Bedrock.
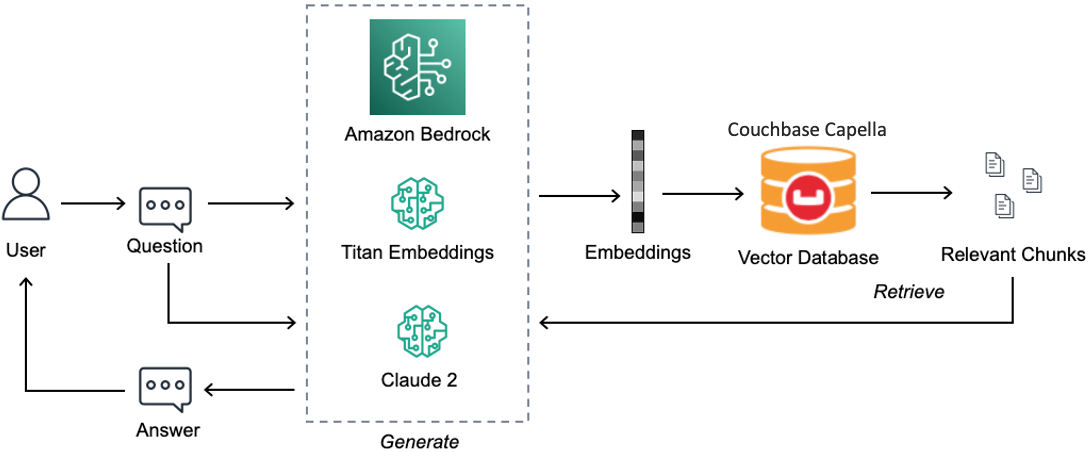
Figura 1: Aplicación Chatbot desarrollada con Capella y Amazon Bedrock
Puede seguir los pasos que se indican a continuación para desarrollar la aplicación RAG representada en la Figura 1.
Paso 1: Crear un índice vectorial
Paso 1.1: Crear un clúster Capella en pocos minutos
-
- Cree una cuenta gratuita en Nivel gratuito de Couchbase Capella que ofrece.
- Seleccione su región de AWS preferida y comience con el clúster Couchbase Capella.
- Configurar las credenciales de la base de datos.
- Puede permitir el acceso desde cualquier lugar para esta implementación RAG.
- Utilizaremos el viaje-muestra Cubo.
Paso 1.2: Crear el índice vectorial
-
- En el Bases de datos seleccione el grupo de pruebas en el que desea crear el índice vectorial.
- Ir a Herramientas de datos > Búsqueda.
- Haga clic en Crear índice de búsqueda.
- Por defecto, se iniciará en Modo rápido. Cambiar a Modo avanzado.
- Haga clic en Índice Definición.
- Haga clic en Importar desde archivo.
- Cargue el fichero índice.
- Haga clic en Crear índice
Paso 2: Seleccionar el modelo de incrustación y el LLM
-
- Ir a la Consola Amazon Bedrock y haga clic en "Model Access" en su cuenta AWS.
- Seleccione los siguientes modelos y haga clic en el botón "Solicitar acceso al modelo":
- Amazon: Titan Embeddings G1 - Texto
- Antrópico: Claude 2
Paso 3: Cree su aplicación RAG
-
- Cree una instancia de Amazon SageMaker Notebook en su cuenta de Amazon siguiendo las instrucciones aquí.
- Cargue el "RAG_con_Sillón_y_Amazon_Bedrock" Jupyter notebook file to the Amazon SageMaker Notebook.
- Configura el bloc de notas con los detalles de conexión de tu entorno Couchbase.
12345COUCHBASE_CONNECTION_STRING = ("<Enter Couchbase endpoint URL>")DB_USERNAME = "<Enter Couchbase Database Username>"DB_PASSWORD = "<Enter Couchbase Database Password>"
-
- Actualiza esta aplicación para adaptarla a tus necesidades y ejecútala cuando hayas terminado.
Ahora puedes hacer preguntas al chatbot. Aunque no se trata en este blog, considere la posibilidad de utilizar Barandillas de roca para garantizar que el contenido que la política de su empresa considere inapropiado no se devuelva como respuesta al usuario final.
Al combinar las capacidades de almacenamiento y recuperación de datos de alto rendimiento de Couchbase con la gama de cobertura de modelos, la seguridad y la facilidad de uso de Amazon Bedrock para el acceso a los LLM de su elección, puede crear aplicaciones RAG de alto rendimiento. Estas aplicaciones ahora se pueden diseñar para una alta relevancia y precisión contextual, lo que permite una amplia gama de casos de uso, como la creación de contenido, la respuesta a preguntas, la generación de resúmenes e informes, y muchos más.

