Generative AI (GenAI) has the potential to automate work activities that currently occupy 60 to 70 percent of employees’ time, leading to substantial productivity gains across various industries. However, a General Purpose (GP) LLM’s knowledge is confined to its training data, causing it to “hallucinate” by providing incomplete or inaccurate responses. This undermines trust and credibility, preventing many GenAI Proofs of Concept (POCs) from reaching production. By introducing the Retrieval-Augmented Generation (RAG) technique we can augment the LLM with proprietary data which grounds LLM responses in current and reliable facts. Successful RAG implementation requires a highly scalable and dependable database to serve as a knowledge base, vector database, and LLM cache, along with a robust platform for developing and scaling GenAI applications using leading foundation models.
Couchbase and Amazon Bedrock together offer an end-to-end platform to seamlessly build performant RAG applications across industries such as retail, healthcare, hospitality, gaming, and many others.
Couchbase Capella, a cloud-native high-performance DBaaS (Database-as-service), allows you to get started quickly with storing, indexing, and querying operational, vector, time series, textual, and geospatial data for your RAG applications while leveraging the flexibility of JSON. Further, it uniquely offers hybrid search, which takes semantic search to the next level by blending traditional and vector search within a single SQL++ query to power applications that require highly granular search with high select specificity. This capability spans the cloud, edge, and mobile. You can easily integrate Capella as a knowledge base, vector DB, or an LLM cache with a leading GenAI platform like Amazon Bedrock using orchestration frameworks such as LangChain or LlamaIndex to build a production-grade RAG pipeline. Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading artificial intelligence (AI) companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon using a single API, along with a broad set of capabilities you need to build generative AI applications with security, privacy, and responsible AI.
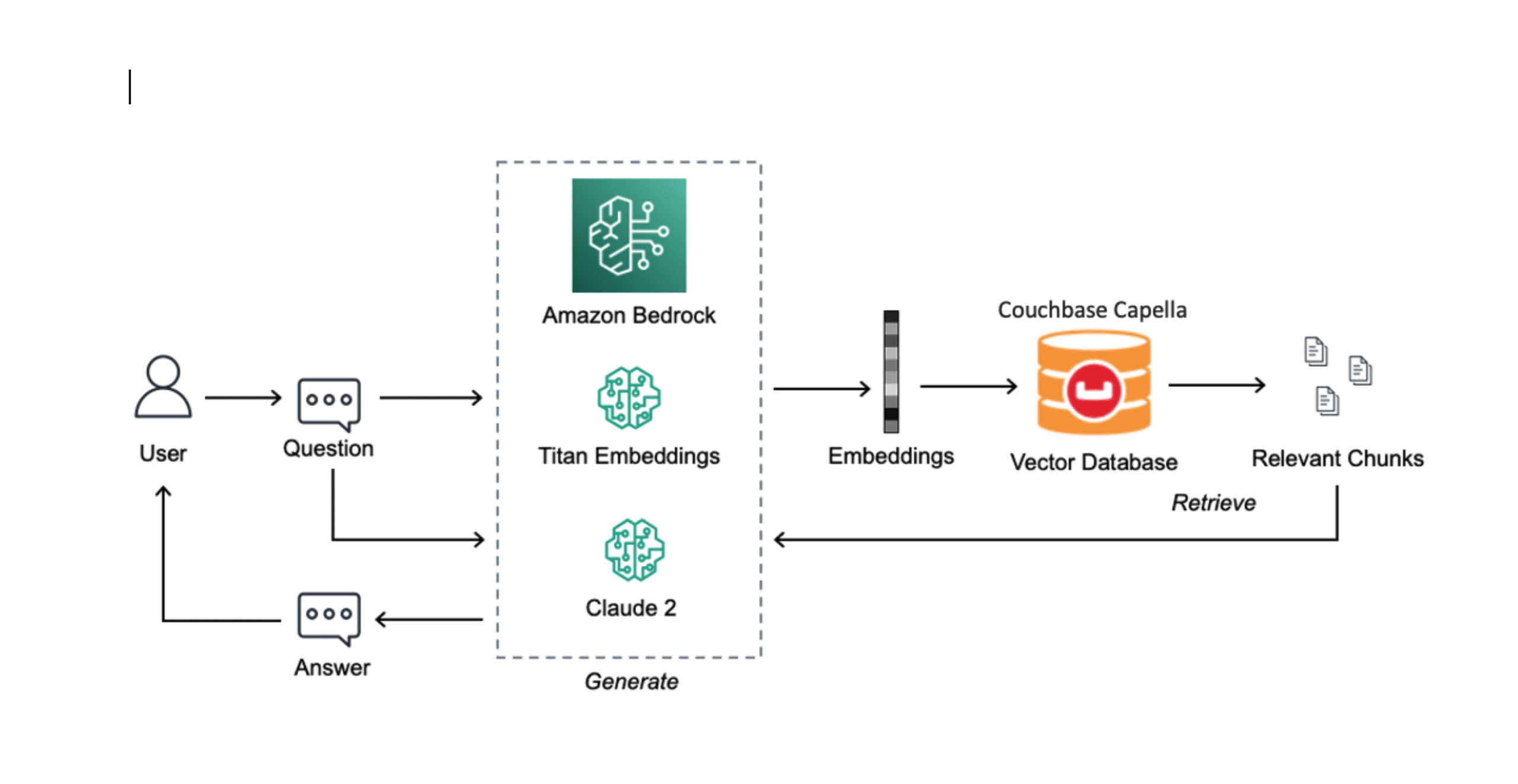
In this blog, we present a RAG-powered chatbot application built using Couchbase Vector Search and Amazon Bedrock. It leverages the Couchbase travel-sample data stored in Couchbase Capella and Anthropic Claude model from Amazon Bedrock.
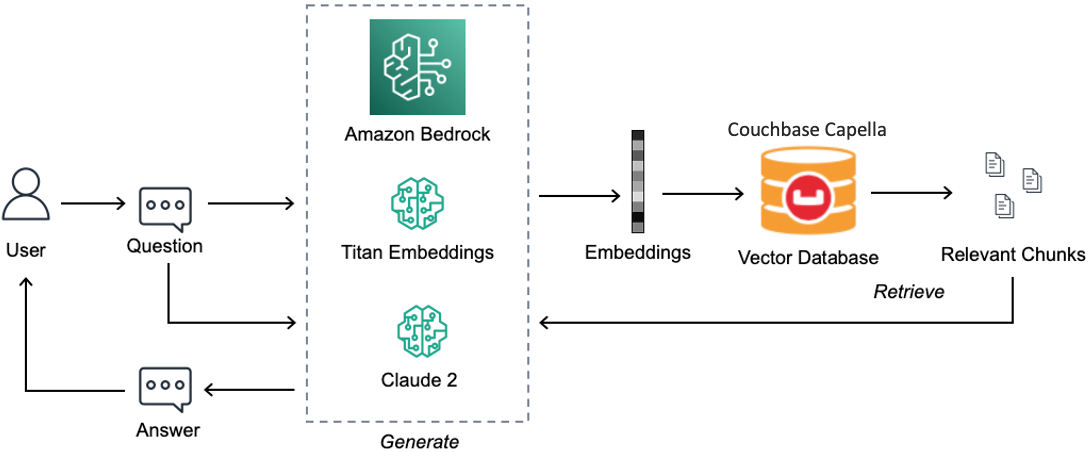
You can follow the steps below to develop your RAG application depicted in Figure 1.
Step 1: Create a vector index
Step 1.1: Create a Capella cluster in a few minutes
- Create an account for free with Couchbase Capella’s free tier offering.
- Select your preferred AWS region and get started with the Couchbase Capella cluster.
- Configure Database Credentials.
- You can allow access from anywhere for this RAG implementation.
- We will use the travel-sample Bucket.
Step 1.2: Create the vector index
- On the Databases page, select the trial cluster where you want to create the vector index.
- Go to Data Tools > Search.
- Click Create Search Index.
- By default, you will start in Quick Mode. Switch to Advanced Mode.
- Click Index Definition.
- Click Import from File.
- Upload the index file.
- Click Create Index
Step 2: Select the embedding model and LLM
- Go to the Amazon Bedrock console and click on “Model Access” in your AWS account.
- Select the following models and click on the “Request model access” button:
- Amazon: Titan Embeddings G1 – Text
- Anthropic: Claude 2
Step 3: Build your RAG application
- Create an Amazon SageMaker Notebook Instance in your Amazon account by following the instructions here.
- Upload the “RAG_with_Couchbase_and_Amazon_Bedrock” Jupyter notebook file to the Amazon SageMaker Notebook.
- Configure the notebook with your Couchbase environment connection details.
- Update this application to suit your needs and run it when done.
You can now ask questions to the chatbot. Although not covered in this blog, consider using Bedrock guardrails to ensure content that your company policy deems inappropriate is not returned as responses to your end user.
By combining the high-performance data storage and retrieval capabilities of Couchbase with the range of model coverage, security, and usability of Amazon Bedrock for access to LLMs of choice, you can build performant RAG applications. These applications can now be designed for high relevance and contextual accuracy, enabling a wide range of use cases such as content creation, question answering, summarization and report generation, and many more.
Deixe um comentário
Você precisa fazer o login para publicar um comentário.