La versión 6.5 de Couchbase incluye una amplia lista de funciones de consulta de bases de datos de nivel empresarial que permiten a los clientes ampliar la adopción de bases de datos NoSQL en aplicaciones de bases de datos tradicionales. La versión ha añadido capacidad transaccional, funciones de Ventana Analítica, funciones JS definidas por el usuario, así como Index Advisor para mejorar el rendimiento de las consultas. Dado que el rendimiento es uno de los aspectos más importantes de la plataforma Couchbase, la nueva versión también incluye un conjunto de nuevas mejoras para fortalecer aún más el Servicio de Índices de Couchbase y mejorar la eficiencia operativa. Estas características se agrupan bajo el título general de Fiabilidad, Manejabilidad y Servicio - Index Service RMS.
1. ALTER INDEX para cambiar el número de réplicas del índice
En 6.5.0, hemos añadido el tan solicitado soporte para cambiar el número de réplicas de un índice utilizando el comando ALTER INDEX. El número de réplicas puede modificarse mediante el comando ALTER como en el siguiente ejemplo -
|
1 |
ALTER INDEX `travel-sample`.airlines_idx WITH {"action":"replica_count","num_replica": 3}' |
acción para ALTER INDEX es recuento_de_réplicas y el parámetro num_replica especifica el nuevo número de réplicas para el índice. Si el valor de num_replica en la sentencia ALTER es mayor que el recuento actual de réplicas, se crean réplicas adicionales; si es menor que el recuento actual de réplicas, se eliminan réplicas.
2. ALTER INDEX para eliminar una réplica de índice
El comando ALTER INDEX se ha mejorado aún más para eliminar una réplica de índice individual utilizando la siguiente sintaxis:
|
1 |
ALTER INDEX `travel-sample`.airlines_idx WITH {"action":"drop_replica","replicaId": 2}' |
acción es drop_index y replicaId es el ID de la réplica, que es un número que identifica una réplica. El replicaId de una réplica y el host en el que reside se pueden obtener de REST API getIndexStatus.
¿Cuáles son las ventajas? Mejor gestión de las réplicas de índices: forma más sencilla de aumentar/reducir el número de réplicas o eliminar una réplica de índice específica. Más información en:
https://docs.couchbase.com/server/6.5/n1ql/n1ql-language-reference/alterindex.html
3. Mejorar la gestión de la reversión de DCP
La reversión de DCP se produce en el servicio de índices cuando uno de los nodos de datos falla y una réplica de datos pasa a estar activa. No todas las conmutaciones por error provocan una reversión. Esta situación sólo ocurre cuando el servicio de índice tiene más datos/vbuuid recientes que la réplica de datos antes de la conmutación por error. Si la réplica de datos se convierte en activa después de un failover, el servicio de índice recibirá un rollback. Consulte la Documentación DCP para más detalles. En el peor de los casos, DCP podría pedir al servicio de índices que retroceda a 0.
Con esta mejora, se ha reforzado la gestión de la reversión de DCP para el servicio de índices.
Cuando el servicio de índices recibe un retroceso de DCP a 0, intentará volver a sus instantáneas de índices más actuales, en lugar de reconstruir el índice completo.
Cuáles son los beneficios:
- El servicio de índices ya no necesitará reconstruir sus índices desde cero cuando el nodo de datos sea auto failover.
- El servicio de índices seguirá prestando servicio a los clientes de consulta sin interrupción utilizando su instantánea más reciente.
- Dado que las instantáneas de disco del índice se toman una vez cada 10 minutos, podría estar sirviendo datos obsoletos durante el periodo en el que el índice se está poniendo al día con el servicio de datos. Si scan_consistency se establece en request_plus, los escaneos esperarán hasta que se cree una instantánea consistente y no se devolverán resultados obsoletos.
4. Optimizar las instantáneas en memoria
El servidor Couchbase está diseñado para ser eventualmente consistente. Sin embargo, la aplicación puede alterar este comportamiento solicitando al servicio de índices que incluya todos los documentos actualizados en sus índices antes de procesar la consulta, a través de la configuración request_plus query consistency. Se espera que el tiempo de respuesta de la consulta tenga cierto retraso, ya que el servicio necesita asegurarse de que los índices están actualizados antes de procesar la consulta. La frecuencia de generación de instantáneas en memoria para los índices se ha aumentado a cada 10 ms para acelerar las consultas request_plus.
Cuáles son los beneficios:
- En Couchbase 6.5, hemos optimizado este proceso acelerando el índice en memoria. Las consultas de aplicaciones, utilizando esta configuración (request_plus) , pueden ver ahora el tiempo de respuesta reducido en más de 45%.
5. Mejoras en el uso de la memoria del proyector
Projector es un proceso que reside en el nodo de datos y que procesa las mutaciones entrantes en nombre del servicio de índices. El proyector garantiza que sólo se envíen al servicio de índices las mutaciones que afecten a los campos del documento que formen parte de algún índice. El uso de la memoria del proyector puede verse afectado negativamente con tasas de mutación elevadas, documentos de gran tamaño y un flujo descendente más lento. Esta mejora implica la reconfiguración de varios parámetros internos del proyector para garantizar que el uso de la memoria del proceso se mantiene en un nivel óptimo.
Cuáles son los beneficios:
- Los casos de prueba de rendimiento muestran que el RSS (uso de memoria) del proyector máximo ha disminuido de 1,5 GB a 176 MB (para una carga de trabajo específica) sin afectar al tiempo de creación del índice.
6. Mejorar el tiempo de respuesta del proyector al indexador
Bajo una carga pesada, el proceso del proyector puede volverse lento a la hora de responder al servicio de indexación, lo que se debía a la lentitud de los mensajes de control de la comunicación en el canal del proyector. Se ha introducido una optimización para separar los canales de control y datos en el proyector y también para dar prioridad a los mensajes de control sobre los de datos.
Cuáles son los beneficios:
- Bajo la presión de la memoria, el proyector sigue respondiendo a los mensajes de control del indexador y podemos observar una reducción de los fallos de reequilibrio.
7. Construir todos los índices no construidos a la vez
El comando N1QL para CONSTRUIR índice actualmente toma un único nombre o una lista de nombres de índices. Este comando ha sido mejorado para tomar el resultado de una consulta, permitiendo así a los administradores enviar un único comando para construir todos los índices no construidos. Esto es particularmente útil después de una restauración de la base de datos, y el Administrador necesita reconstruir todos los índices que están en estado diferido.
|
1 2 3 4 5 6 |
BUILD INDEX ON `travel-sample` ((SELECT RAW name FROM system:indexes WHERE keyspace_id = 'travel-sample' AND state = 'deferred' )); |
Cuáles son los beneficios:
- El administrador de la base de datos puede emitir un único comando BUILD para reconstruir todos los índices no construidos (diferidos).
8. Permitir escaneos durante el calentamiento del indexador
Cuando el indexador se reinicia, los índices se recuperan de persistió almacenamiento. Si el número de índices por nodo es alto, esto puede llevar mucho tiempo (hasta unos minutos). Antes de esta mejora, los escaneos se desactivaban durante el calentamiento del indexador. Hemos mejorado este comportamiento para permitir escaneos para aquellos índices que se calientan y tienen una instantánea consistente disponible. Si no se dispone de una instantánea consistente durante el calentamiento (esto ocurre cuando el servicio de datos se ha adelantado), se devuelve un error para que se pueda volver a intentar una réplica del índice en otro nodo del indizador.
Cuáles son los beneficios:
- Esta mejora permite mejorar la continuidad de la aplicación y la disponibilidad del servicio en caso de reinicio del proceso de indexación.
9. Aplicar cambios de configuración dinámicamente sin reiniciar el indizador
Antes de esta mejora, cambiar los ajustes que permiten/prohiben claves grandes, controlar el tamaño de las claves indexadas y los correspondientes búferes en tiempo de ejecución necesarios para procesar las claves indexadas requería reiniciar el proceso del indexador, lo que provocaba el reinicio de los indexadores de todo el clúster y la indisponibilidad del servicio. Hemos mejorado el comportamiento para garantizar que estos tamaños se apliquen dinámicamente y que todos los búferes cambien de tamaño dinámicamente sin afectar al procesamiento de las mutaciones.
Cuáles son las ventajas: Ahora se pueden cambiar dinámicamente los siguientes ajustes sin reiniciar el proceso del indexador: max_seckey_size, max_array_seckey_size y allow_large_keys.
No es necesario ningún cambio de configuración para habilitar esta mejora. Esto permite la continuidad de la aplicación y la disponibilidad del servicio cuando se modifican los ajustes anteriores.
10. Encontrar índices no utilizados
En las grandes aplicaciones que utilizan bases de datos, puede haber muchos índices creados, pero es posible que no todos estén en uso en el pasado reciente o que no se utilicen en absoluto. Para facilitar la identificación de los índices que no se utilizan y poder eliminarlos, ahora proporcionamos una estadística para cada índice que contiene la marca de tiempo de la última consulta conocida de ese índice como marca de tiempo Unix (en nanosegundos). Esta estadística no se restablece al reiniciar el indexador, ya que se guarda localmente en el nodo indexador. Esta estadística es una heurística para obtener una estimación del tiempo de la última consulta y no puede ser exacta ya que el intervalo de persistencia de la estadística es de 15 minutos. Puede obtenerse utilizando la API REST de estadísticas del indizador, y también está disponible en la interfaz de usuario de definición del índice.
|
1 |
curl -u <username>:<password> <hostname>:9102/api/v1/stats | json_pp | grep last_known_scan_time "travel-sample:airlines_idx:last_known_scan_time" : 1579179249769780000, |
También puede utilizar N1QL para consultar los índices no utilizados
|
1 2 3 4 5 |
SELECT ARRAY { "index_name":a.name, "last_scan_time":millis_to_str(a.val.last_known_scan_time/1000000) } FOR a IN OBJECT_PAIRS(results) END FROM curl("https://<hostname>:9102/api/v1/stats", {"user":"<username>:<password>"}) results |
11. Mejoras en las estadísticas
Se han añadido nuevas estadísticas al registro de estadísticas periódicas en el indexador y en el proyector. Estas estadísticas son:
| Estadísticas | Descripción | Disponible en el punto final REST compatible |
| num_scan_timeouts | Número de solicitudes de escaneado que han expirado esperando una instantánea o durante el escaneado en curso. | Sí |
| num_scan_errors | Número de solicitudes de escaneo que fallaron debido a cualquier error distinto del tiempo de espera. | Sí |
| avg_scan_latency | Media de las latencias de escaneado observadas para un índice determinado | No |
| hora_última_exploración_conocida | Una marca de tiempo Unix int64 que representa la última hora conocida de un índice. | Sí |
| distribución_tamaño_clave | Una distribución de tamaños de clave en varios cubos de tamaño | No |
| arrkey_size_distribution | key_size_distribution - Distribución de los tamaños de las claves en distintos intervalos de tamaño | No |
| número_elementos_cargados | Número de claves de índice escritas en el almacenamiento de índices. | Sí |
| progreso_de_construcción_inicial | Progreso de la construcción inicial de un índice en porcentaje | Sí |
| tasa_de_drenaje_avg | Promedio del número de elementos vaciados en el almacenamiento de índices | Sí |
| número_solicitudes_pendientes | Número de solicitudes de escaneado pendientes o en curso. | Sí |
| memoria_almacenamiento_total | memoria_almacenamiento_total - Tamaño del uso total de jemalloc por el almacenamiento de índices. | Sí |
| latencia_proyector | Esta estadística mide la latencia media del procesamiento de mutaciones en el proyector, es decir, desde el momento en que la mutación llega desde el nodo de datos hasta el momento en que el proyector la envía al nodo indexador. Se mantiene por nodo de datos en el indexador. Esto ayuda a identificar qué proyector (en un nodo de datos) está tardando más en procesar las mutaciones. | No |
12. Mejoras en la interfaz de usuario del índice
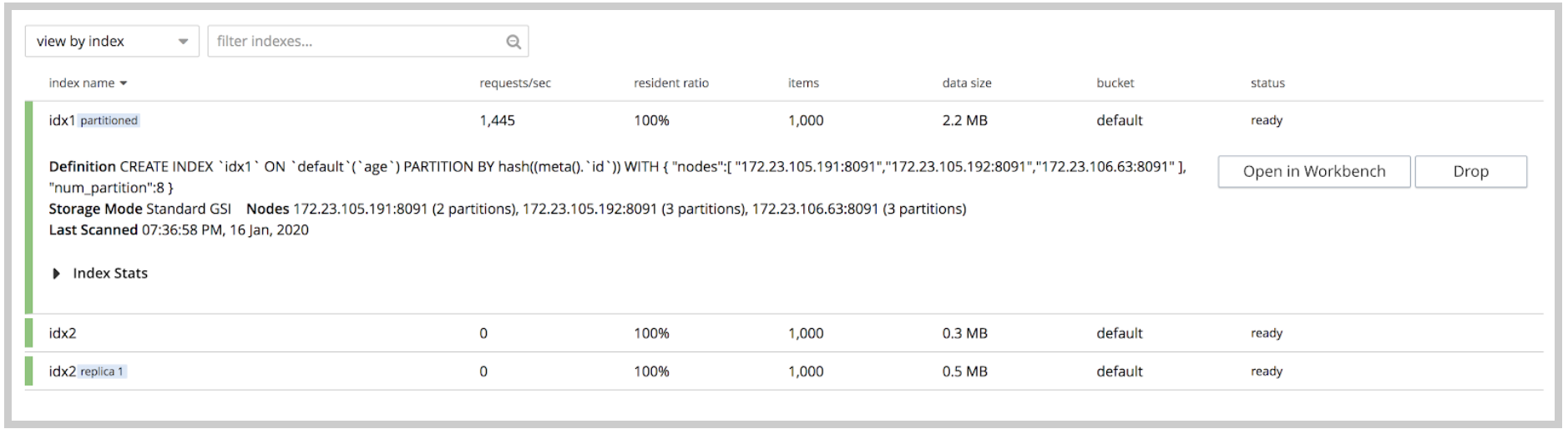
Se ha mejorado la interfaz de usuario del índice en la versión 6.5 para incluir información resumida importante sobre el índice, como peticiones/seg, proporción de residentes, elementos, tamaño de los datos y estado. Al desplegar un índice individual, se muestra la definición del índice y, en el caso de un índice particionado, la información sobre sus nodos y particiones.
Índice Resumen
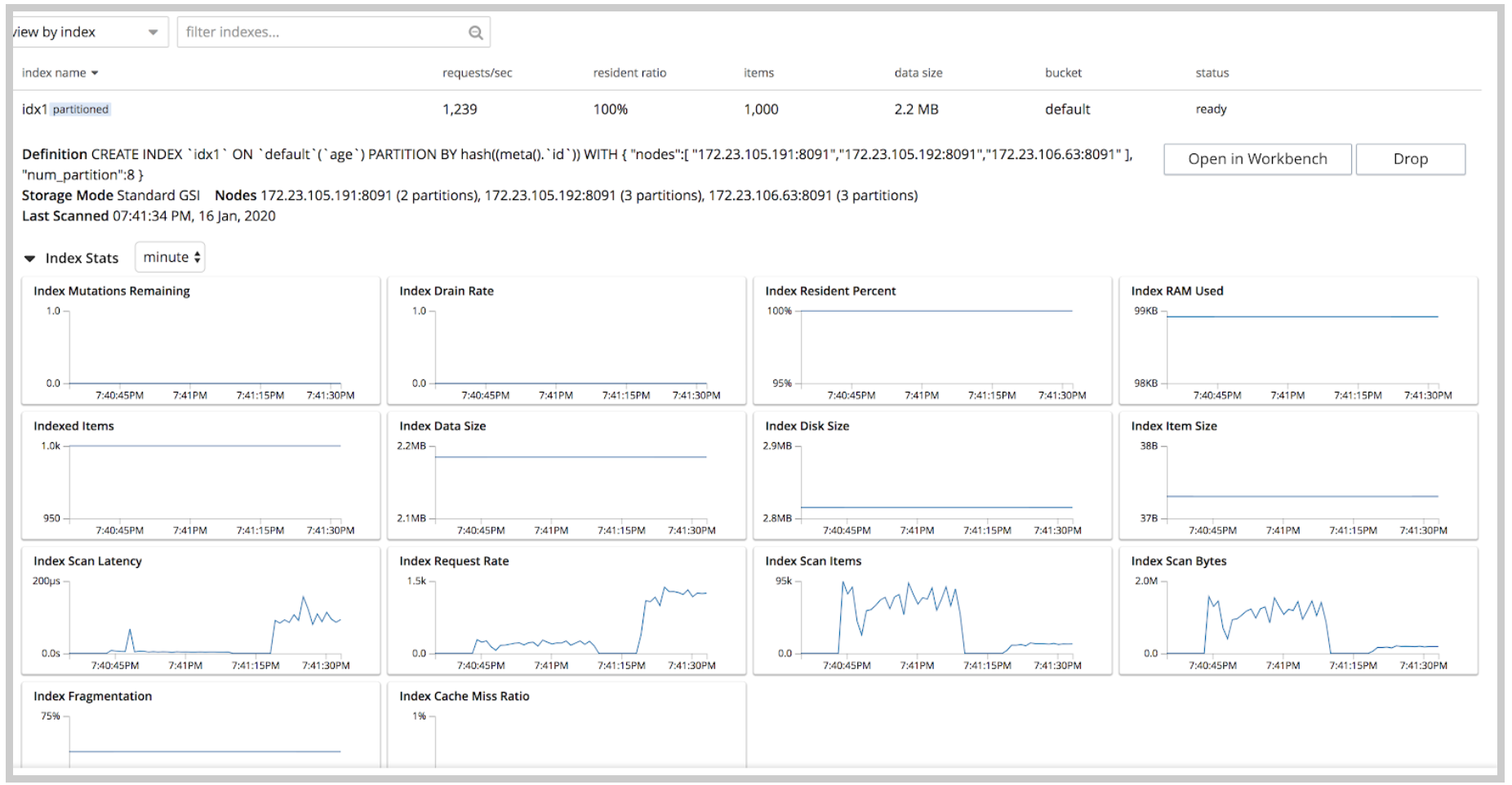
Índice Estadísticas
Una nueva adición significativa a la interfaz de usuario del índice son las estadísticas del índice para cada índice, que muestra una vista gráfica de las estadísticas clave, como el porcentaje de residentes, el tamaño de los datos, el tamaño del disco, la fragmentación del índice y la tasa de drenaje, entre otras. En la parte inferior de la página se muestra un resumen completo de las estadísticas de todo el servicio de índices (de todos los índices), que incluye información como la cuota de RAM del servicio de índices, la RAM utilizada/reservada, el porcentaje de RAM del servicio de índices, la tasa de exploración total y la fragmentación de los índices. Estas mejoras en la interfaz de usuario de índices facilitan la supervisión de los índices con las estadísticas más importantes disponibles.
Índice resumen del servicio en la parte inferior de la página

Resumen
Estamos muy entusiasmados con las nuevas mejoras del servicio de Índice (GSI) RMS para Couchbase v6.5, ya que estas características abordarán muchas peticiones que nuestros clientes han solicitado. Como siempre, esperamos recibir comentarios sobre estas mejoras,
Recursos
- Descargar: Descargar Couchbase Server 6.5
- Documentación: Novedades de Couchbase Server 6.5
- Todos los blogs de 6.5
Nos encantaría que nos dijera qué le han parecido las funciones de la versión 6.5 y en qué beneficiarán a su empresa en el futuro. Por favor, comparta su opinión a través de los comentarios o en el foro.
Coautora: Prathibha Bisarahalli | Ingeniero Superior de Software