La forma en que buscamos información e interactuamos con ella ha cambiado radicalmente en la última década. Los motores de búsqueda tradicionales basados en palabras clave nos servían antes para encontrar documentos o respuestas, pero los retos empresariales actuales exigen mucho más que coincidencias exactas de palabras clave. Los usuarios modernos -ya sean consumidores o empresas- esperan sistemas que comprender intento, interpretar contexto, y Entregar más relevantes al instante.
Aquí es donde búsqueda vectorial entra en juego. Al transformar los datos en representaciones matemáticas de alta dimensionalidad (embeddings), la búsqueda vectorial permite a los sistemas captar el significado semántico en lugar de la mera superposición léxica. Las implicaciones van mucho más allá de los motores de búsqueda. Aplicaciones antigénicas - que pueden percibir, razonar y actuar de forma autónoma, dependen en gran medida de la búsqueda vectorial como columna vertebral de su conocimiento. Sin ella, los agentes de IA corren el riesgo de ser respondedores superficiales en lugar de solucionadores de problemas conscientes del contexto.
En este blog, exploraremos por qué la búsqueda vectorial se ha vuelto esencial, los dominios de negocio que está remodelando, y cómo Couchbase está permitiendo esta transformación con Full Text Search (FTS) y Eventing. Nos sumergiremos en un caso de estudio real en la industria de las telecomunicaciones, y prepararemos el escenario para una guía práctica.
Por qué es importante la búsqueda vectorial
En el centro de la búsqueda vectorial se encuentran incrustaciones - representaciones numéricas de palabras, documentos o incluso archivos multimedia. A diferencia de las palabras clave, las incrustaciones codifican relaciones semánticas. Por ejemplo, "corte de red" y "llamadas caídas" pueden no compartir muchas palabras clave, pero semánticamente apuntan a problemas similares. Con las incrustaciones vectoriales, tanto las consultas como los datos se proyectan en el mismo espacio multidimensional, donde la similitud se determina mediante métricas de distancia (similitud coseno, producto punto, etc.).
Este cambio tiene profundas implicaciones:
-
- De lo literal a lo contextual: Los sistemas de búsqueda ya no se limitan a buscar palabras, sino que captan significados.
- De lo estático a lo dinámico: Los espacios vectoriales se adaptan a medida que crecen los datos y evolucionan los contextos.
- De la búsqueda al razonamiento: Las aplicaciones agenéticas se basan en incrustaciones no sólo para recuperar datos, sino también para interpretar intenciones y tomar decisiones.
En pocas palabras, la búsqueda vectorial no es una mejora de la búsqueda por palabras clave. cambio de paradigma la próxima generación de sistemas inteligentes y autónomos.
Casos de uso empresarial que impulsan la adopción de la búsqueda vectorial
Telecomunicaciones (análisis PCAP)
Las redes de telecomunicaciones generan enormes volúmenes de datos de captura de paquetes (PCAP). El análisis tradicional implica filtros de palabras clave, búsquedas regex y correlación manual entre gigabytes de registros, lo que a menudo resulta demasiado lento para la resolución de problemas en tiempo real. La búsqueda vectorial cambia las reglas del juego. Al incrustar trazas PCAP, las anomalías y los patrones se pueden agrupar y recuperar semánticamente, lo que permite a los ingenieros identificar problemas (como la degradación de la calidad de las llamadas o la pérdida de paquetes) al instante.
Copilotos de atención al cliente
Los centros de contacto están pasando de los robots de FAQ con guión a los copilotos inteligentes que asisten a los agentes humanos. La búsqueda vectorial garantiza que las consultas de los usuarios se correspondan con las respuestas correctas de la base de conocimientos, aunque estén redactadas de forma diferente. Por ejemplo, "Mi teléfono no para de perder llamadas" puede corresponderse con documentación sobre "problemas de congestión de la red", algo que la búsqueda por palabras clave probablemente pasaría por alto.
Detección del fraude en las finanzas
El fraude financiero es sutil: los patrones no siempre siguen palabras clave. Con las incrustaciones, el comportamiento transaccional puede representarse en vectores, lo que permite a los sistemas detectar valores atípicos que se desvían de los patrones "normales". Esto permite a las instituciones detectar anomalías inusuales pero invisibles por palabras clave.
Sanidad
La investigación médica y los historiales de los pacientes contienen terminologías diversas. La búsqueda vectorial puede conectar "dolor torácico" con "angina de pecho" o "molestias cardiacas", lo que aumenta la eficacia de los sistemas de apoyo a la toma de decisiones clínicas. Acelera la investigación, el diagnóstico y el descubrimiento de fármacos.
Venta al por menor y motores de recomendación
Los sistemas de recomendación prosperan gracias a la similitud semántica. La búsqueda vectorial permite que las recomendaciones del tipo "a la gente que compró esto también le gustó aquello" funcionen a un nivel más profundo: no solo coinciden las etiquetas de los productos, sino que alinean la intención, el estilo o los patrones de comportamiento de los usuarios.
Gestión del conocimiento empresarial
Las organizaciones sufren de silos de datos. Los empleados pierden horas buscando información relevante en múltiples sistemas. La búsqueda vectorial potencia los sistemas de conocimiento unificados que muestran la información más relevante en cada contexto, independientemente del formato o la redacción.
Estudio de caso: Análisis PCAP en Telecom con búsqueda vectorial
El reto
Los operadores de telecomunicaciones capturan miles de millones de paquetes al día. El análisis tradicional de paquetes implica el filtrado manual, la búsqueda de cadenas o la aplicación de reglas estáticas para detectar anomalías. Estos enfoques:
-
- No captan la similitud semántica (por ejemplo, diferentes manifestaciones del mismo problema de fondo).
- Lucha a gran escala debido al enorme volumen de datos
- Conducen a una lenta resolución de problemas y a clientes frustrados
La ventaja de la búsqueda vectorial
Mediante la incrustación de datos PCAP en vectores:
-
- Las anomalías se agrupan de forma natural en el espacio vectorial (por ejemplo, todas las trazas de llamadas perdidas están muy juntas).
- Consultas semánticas (busque "picos de latencia" y descubra registros con fluctuación de paquetes o retransmisiones).
- El análisis de causas acelera, ya que los problemas relacionados pueden aparecer automáticamente en lugar de tener que recopilarlos manualmente.
El resultado
Los ingenieros de telecomunicaciones pasan del análisis reactivo de registros a la detección proactiva de anomalías. Los problemas de los clientes se identifican en tiempo real, lo que mejora la satisfacción y reduce la pérdida de clientes. Lo que antes requería horas de análisis manual ahora se puede realizar en cuestión de minutos.
Cómo Couchbase permite la búsqueda vectorial para aplicaciones semánticas y agenticas
Resumen de la búsqueda de texto completo (FTS)
Couchbase FTS lleva mucho tiempo permitiendo a las empresas ir más allá de las consultas estructuradas, ya que admite el lenguaje natural y las capacidades de texto completo. Sin embargo, FTS por sí solo sigue basándose en la búsqueda léxica.
Añadir búsqueda vectorial
Couchbase amplía FTS con indexación vectorial y búsqueda por similitud. Esto significa que las empresas pueden integrar datos (registros, documentos, consultas, etc.) en vectores y almacenarlos en Couchbase para su recuperación semántica. En lugar de devolver coincidencias de palabras clave, FTS ahora puede mostrar resultados contextualmente relevantes.
Búsqueda híbrida
El verdadero poder viene de búsqueda híbrida — Combinación de similitud de palabras clave y vectores. Por ejemplo, un ingeniero de telecomunicaciones puede buscar “caídas de llamadas en Nueva York” y obtener resultados que combinen coincidencias de ubicación exactas (palabra clave) con anomalías PCAP semánticamente similares (vector).
Concurso completo en acción
Couchbase Eventing añade disparadores en tiempo real a este ecosistema. Imagina una función de eventos que:
-
- Vigila las anomalías en las incrustaciones de paquetes.
- Genera alertas automáticamente cuando se superan los umbrales de similitud.
- Inicia flujos de trabajo (por ejemplo, abrir un ticket de Jira o notificar al equipo de operaciones).
Esta combinación — FTS + Búsqueda vectorial + Eventos — transforma la búsqueda de una recuperación pasiva de información en entrega de inteligencia activa.
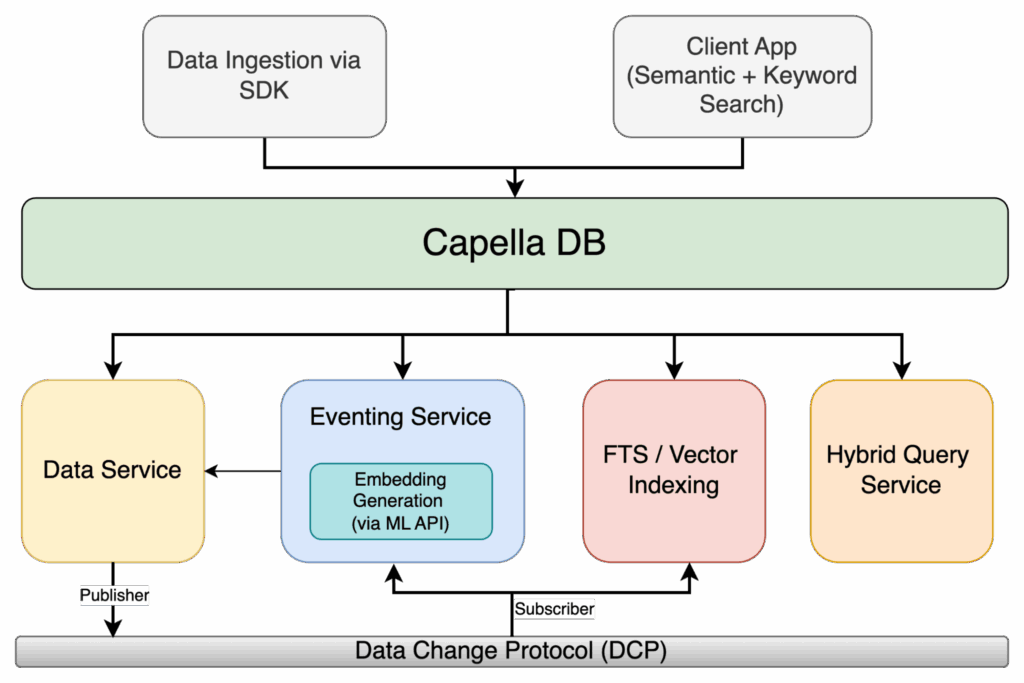
Figura 1: Arquitectura de búsqueda híbrida de Capella con eventos, incrustaciones de ML e indexación FTS/vectorial.
Guía práctica: búsqueda vectorial con Couchbase
Hasta ahora, hemos hablado de por qué es importante la búsqueda vectorial y cómo Couchbase la potencia. Ahora vamos a ponerlo todo junto en un ejemplo práctico.
Nuestro escenario es Análisis PCAP (captura de paquetes) de telecomunicaciones. Imagina un flujo masivo de resúmenes de sesiones de paquetes que llegan a Couchbase. En lugar de almacenar estos datos de forma pasiva, queremos que Couchbase:
-
- Automáticamente incrustar cada resumen de sesión en un vector utilizando Incrustaciones de OpenAI.
- Almacene estas incrustaciones junto con los metadatos sin procesar.
- Índicarlos en Couchbase FTS para consultas rápidas de similitud vectorial.
- Permítanos detectar anomalías o “sesiones que parecen inusuales” en tiempo real.
¿Lo mejor de todo? No lo haremos manualmente. Eventos automatizará todo el proceso: en el momento en que llegue un nuevo documento de sesión PCAP, Couchbase lo enriquecerá con una incrustación y lo enviará directamente al índice vectorial.
Requisitos previos
Antes de sumergirnos en la compilación, asegurémonos de que nuestro entorno esté listo. No se trata solo de marcar casillas, sino de preparar el terreno para una experiencia de desarrollo fluida.
Couchbase Server o Capella
Necesitarás un entorno Couchbase en funcionamiento con el Eventos y FTS (Búsqueda de texto completo) servicios habilitados. Estos son los motores que impulsarán la automatización y la búsqueda.
Un cubo para almacenar datos de sesión PCAP.
Para este tutorial, llamaremos al bucket pcap. Dentro de él, organizaremos los datos en ámbitos y colecciones para mantener todo ordenado.
Servicio de eventos habilitado
Las funciones de Eventing son nuestro “pegamento reactivo”. Tan pronto como se ingesta un nuevo resumen de sesión PCAP, Eventing entra en acción, enriquece el documento con incrustaciones y, opcionalmente, activa alertas de anomalías.
Servicio FTS habilitado
Esto nos permitirá construir un índice vectorial más adelante, para poder realizar búsquedas por similitud en las incrustaciones de sesión. Sin ello, las incrustaciones no son más que números almacenados en JSON.
Punto final de la API de incrustaciones
Necesitarás tener acceso a un modelo de incrustaciones y una clave API. En este blog, daremos por hecho que se trata de text-embedding-3-small o text-embedding-3-large de OpenAI, pero puedes indicar cualquier API que devuelva un vector de dimensión fija. Eventing utilizará curl() para llamar a este punto final.
Ingestión de sesiones PCAP: modelo de datos
Cada captura PCAP genera una avalancha de paquetes. Para nuestra demostración, en lugar de almacenar paquetes sin procesar (demasiado grandes y ruidosos), trabajaremos con resúmenes de las sesiones. Estos resúmenes recogen los datos más importantes: direcciones IP de origen/destino, protocolo, fluctuación, pérdida de paquetes, retransmisiones y una breve descripción en lenguaje natural de cómo fue la sesión.
Un documento de sesión única podría tener el siguiente aspecto:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
{ "type": "pcap_session", "sessionId": "sess-2025-08-21-001", "ts": "2025-08-21T09:10:11Z", "srcIP": "10.1.2.3", "dstIP": "34.201.10.45", "srcPort": 5060, "dstPort": 5060, "proto": "SIP", "region": "us-east-1", "carrier": "cb-telecom", "durationMs": 17890, "packets": 3412, "lossPct": 0.7, "jitterMs": 35.2, "retransmits": 21, "summaryText": "SIP call with intermittent RTP loss and elevated jitter, user reported call drops", "embedding_vector": null, // <-- Eventing will fill this "qualityLabel": "unknown" // <-- Eventing/alerts will update this } |
Campos clave:
-
- texto resumen → una sinopsis en lenguaje natural que captarán las incrustaciones.
- Etiqueta de calidad → etiqueta de salud heurística (saludable, degradado) que Eventing puede asignar.
En esta etapa, el vector de incrustación está vacío. Ahí es donde entra en juego Eventing.
Crear cubeta/ámbito/colección
Organizaremos el proceso en contenedores lógicos:
-
- Cubo: pcap
- Alcance: telco
- Colecciones:
- sesiones (resúmenes de sesiones PCAP sin procesar)
- alertas (para alertas de anomalías emitidas por Eventing)
- metadatos (para escribir información de metadatos de eventos)
Ejemplo N1QL:
|
1 2 3 |
CREATE SCOPE `pcap`.`telco`; CREATE COLLECTION `pcap`.`telco`.`sessions`; CREATE COLLECTION `pcap`.`telco`.`alerts`; |
Generar algunos documentos de sesión PCAP de muestra
Insertemos un par de sesiones correctas y degradadas para probar el proceso:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
INSERT INTO `pcap`.`telco`.`sessions` (KEY, VALUE) VALUES ("sess::1", { "type":"pcap_session","sessionId":"sess::1","ts":"2025-08-21T09:00:00Z", "srcIP":"10.0.0.1","dstIP":"52.0.0.5","srcPort":16384,"dstPort":16384, "proto":"RTP","region":"us-east-1","carrier":"cb-telecom","durationMs":600000, "packets":100000,"lossPct":0.05,"jitterMs":2.5,"retransmits":0, "summaryText":"Stable RTP media stream, negligible packet loss and low jitter", "embedding_vector":null,"qualityLabel":"unknown" }), ("sess::2", { "type":"pcap_session","sessionId":"sess::2","ts":"2025-08-21T09:05:00Z", "srcIP":"10.0.0.2","dstIP":"52.0.0.5","srcPort":5060,"dstPort":5060, "proto":"SIP","region":"us-east-1","carrier":"cb-telecom","durationMs":120000, "packets":12000,"lossPct":0.7,"jitterMs":35.2,"retransmits":21, "summaryText":"SIP negotiation with intermittent media loss and elevated jitter, multiple retransmits", "embedding_vector":null,"qualityLabel":"unknown" }); |
Así es como se vería si visualizara los documentos de la colección. sesión:
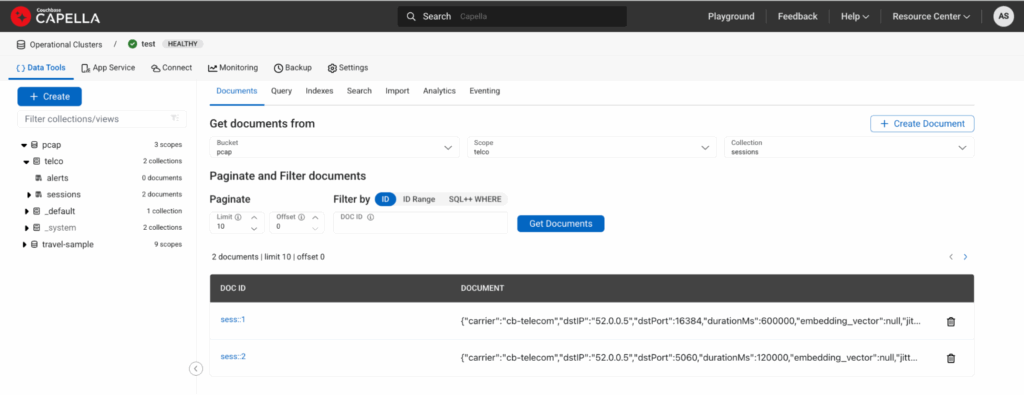
Figura 2: Interfaz de usuario de Capella mostrando dos documentos ingresados a través del DML anterior.
Eventing: incrustación automática al importar
Aquí es donde ocurre la magia. Cada vez que se escribe un documento en pcap.telco.sesiones, nuestra función Eventing hará lo siguiente:
-
- Llama a la API de incrustaciones de OpenAI con texto resumen + Características estructuradas como proto, pérdida, fluctuación, región, portadora.
- Almacena el vector devuelto en vector de incrustación.
- Etiqueta la sesión como saludable o degradado.
- Copiar el documento enriquecido de nuevo en sesiones.
- Emitir alertas de anomalías en alertas.
Definiremos los enlaces de la siguiente manera:
-
- Nombre: pcapEmbedding
- Fuente: pcap.telco.sesiones
- Metadatos: pcap.telco.metadatos
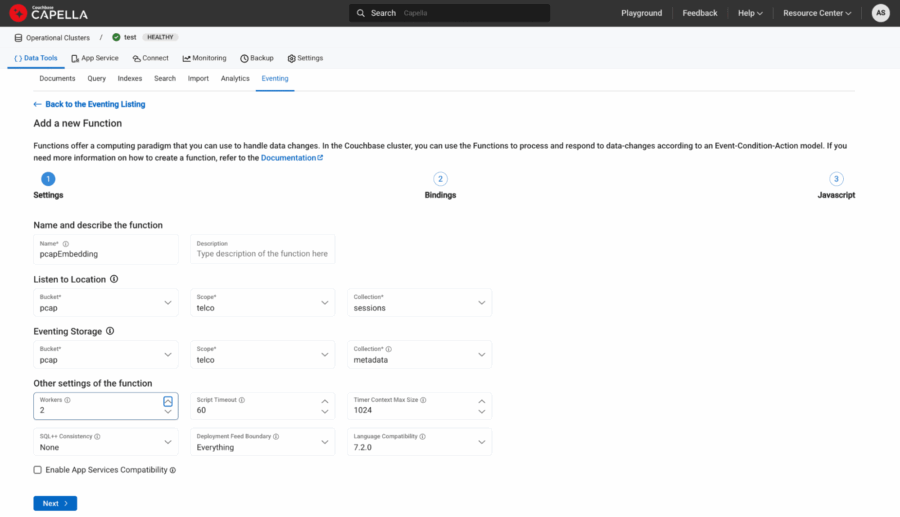
Figura 3: Vinculación de fuentes y metadatos.
-
- Alias de cubeta:
- dst → pcap.telco.sesiones con Leer y escribir Permiso
- alertas → alertas de pcap.telco con Leer y escribir Permiso
- Alias de URL:
- EMBEDDING_API → “https://api.openai.com/v1/embeddings“
- Alias constantes:
- MODELO DE INCORPORACIÓN → “text-embedding-3-small”
- Alias de cubeta:
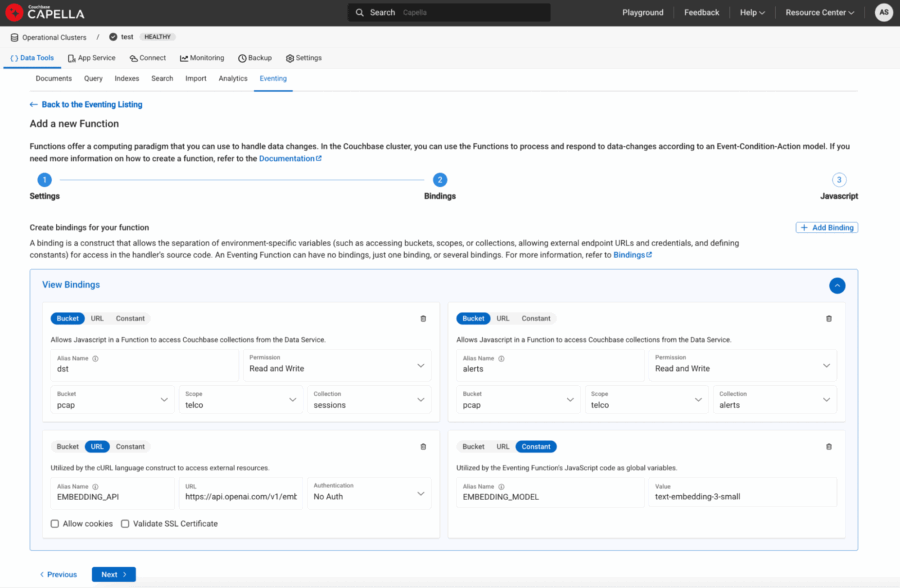
Figura 4: URL y constantes definidas como enlaces a la función de eventos.
Automatización del enriquecimiento con Eventing
Este es el momento mágico. En la mayoría de las bases de datos, enriquecer los datos con incrustaciones requiere canalizaciones ETL externas o trabajadores personalizados. Con Couchbase Eventing, la propia base de datos se vuelve inteligente.
La idea es sencilla:
-
- Tan pronto como un nuevo documento de sesión llega al sesiones colección, Eventing se activará.
- Llamará al API de incrustación de OpenAI (texto-incrustado-3-pequeño o texto-incrustado-3-grande son excelentes ejemplos de ello).
- El vector devuelto se volverá a añadir al mismo documento.
¿El resultado? Ahora tu cubeta tiene capacidad para Sesiones PCAP + su huella semántica, listo para ser indexado.
Aquí está el controlador Eventing actualizado:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 |
function OnUpdate(doc, meta) { log("Eventing function started for doc id:", meta.id); try { if (doc.type !== "pcap_session") { log("Skipping doc: type is", doc.type); return; } var OPENAI_KEY = "YZX"; // <-- your OpenAI key // 1) Build enriched input text for embedding // Combine free-text + structured context so embeddings capture richer semantics var text = doc.summaryText || ""; text += " Proto:" + (doc.proto || ""); text += " LossPct:" + (doc.lossPct || 0); text += " JitterMs:" + (doc.jitterMs || 0); text += " Retransmits:" + (doc.retransmits || 0); text += " Region:" + (doc.region || ""); text += " Carrier:" + (doc.carrier || ""); log("Emritched text before embedding is: " + text); // 2) Call OpenAI Embeddings API var request = { headers: { "Authorization": "Bearer " + OPENAI_KEY, "Content-Type": "application/json" }, body: JSON.stringify({ "input": text, "model": EMBEDDING_MODEL }) }; try { var response = curl("POST", EMBEDDING_API, request); var body = response.body; log("Response body parsed"); if (typeof body === "string") { var result = JSON.parse(body); } else if (typeof body === "object") { // If already parsed, just assign var result = body; } else { log("Unexpected response.body type:", typeof body); } // Extract the embedding vector from first data element if (result && result.data && result.data.length > 0 && result.data[0].embedding) { var embeddingVector = result.data[0].embedding; log("Embedding vector length:", embeddingVector.length); // 3) Write back embedding + quality heuristic doc.embedding_vector = embeddingVector; doc.embedding_model = EMBEDDING_MODEL; doc.qualityLabel = (doc.lossPct > 0.5 || doc.jitterMs > 30 || doc.retransmits > 10) ? "degraded" : "healthy"; // Update destination collection dst[meta.id] = doc; } else { log("Embedding not found in response:", JSON.stringify(result)); } } catch (e) { log("Curl threw exception:", e); } // 4) Raise anomaly alert if degraded if (doc.qualityLabel === "degraded") { var alertDoc = { type: "pcap_alert", sessionId: doc.sessionId, ts: new Date().toISOString(), reason: "Heuristic threshold exceeded", lossPct: doc.lossPct, jitterMs: doc.jitterMs, retransmits: doc.retransmits, region: doc.region, carrier: doc.carrier }; var alertKey = "alert::" + doc.sessionId; alerts[alertKey] = alertDoc; } log("Document enriched with embedding + quality label:", meta.id); } catch (e) { log(" Eventing exception", e); } } function OnDelete(meta, options) { // No-op for deletes } |
Ahora, cada resumen de sesión PCAP nuevo se enriquece a sí mismo en tiempo real.
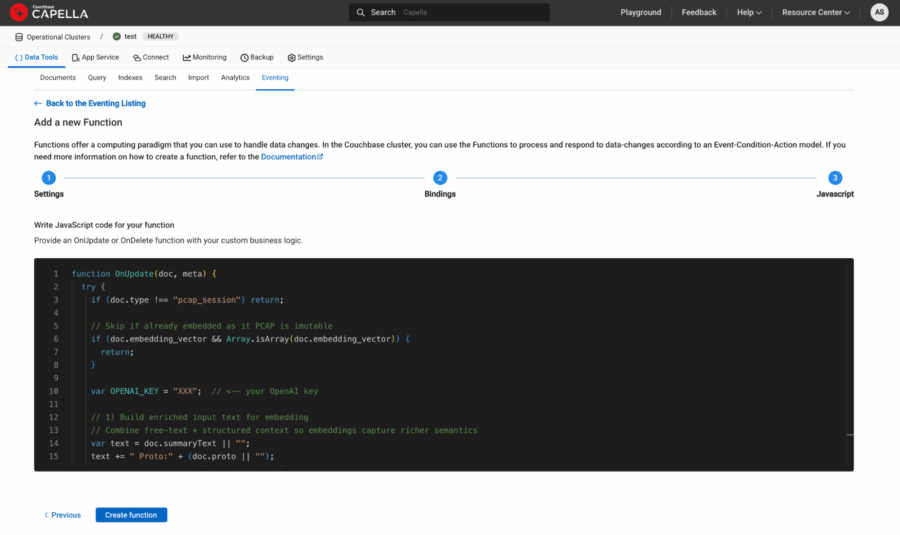
Figura 5: Función Eventing javascript copiada y pegada en el último paso de la definición de la función.
Por último, implemente la función y debería ponerse en verde una vez que esté lista.
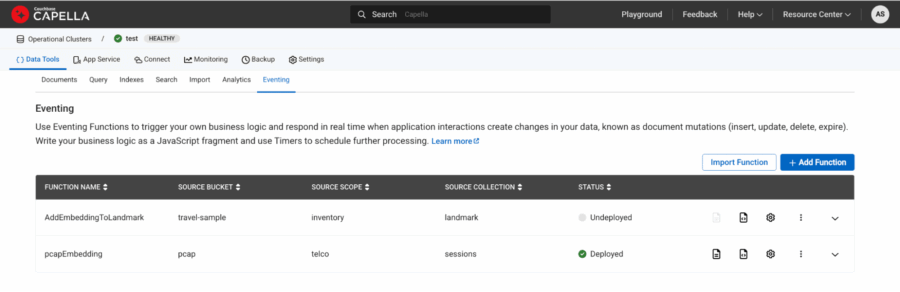
Figura 6: pcapEmbedding La función se ha implementado y aparece en verde en el estado.
Revisa el documento y ahora debería tener información adicional. vector de incrustación y modelo de incrustación campos con los otros campos de esta manera:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
{ "carrier": "cb-telecom", "dstIP": "52.0.0.5", "dstPort": 16384, "durationMs": 600000, "jitterMs": 2.5, "lossPct": 0.05, "packets": 100000, "proto": "RTP", "qualityLabel": "healthy", "region": "us-east-1", "retransmits": 0, "sessionId": "sess::1", "srcIP": "10.0.0.1", "srcPort": 16384, "summaryText": "Stable RTP media stream, negligible packet loss and low jitter", "ts": "2025-08-21T09:00:00Z", "type": "pcap_session", "embedding_model": "text-embedding-3-small", "embedding_vector": [-0.004560039, -0.0018385303, 0.033093546, 0.0023359614, ...] } |
Creación de un índice FTS sensible a vectores en Couchbase
Ahora que cada documento de sesión PCAP lleva tanto un vector de incrustación y metadatos enriquecidos (región, proto, operador, fluctuación, pérdida, retransmisiones), el siguiente paso es hacer que estos campos sean buscables. El motor de búsqueda de texto completo (FTS) de Couchbase ahora admite indexación vectorial, lo que significa que podemos almacenar esas incrustaciones de alta dimensión junto con los campos numéricos y de palabras clave tradicionales.
¿Por qué es importante?
Porque nos permite ejecutar consultas semánticas como “Buscar sesiones similares a esta llamada degradada en Asia realizada a través de LTE”.” — combinar similitud semántica (mediante búsqueda vectorial) con filtrado estructurado (región, proto, operador).
Aquí hay una definición JSON sencilla de dicho índice (desde la consola FTS, crearía un nuevo índice y pegaría esto):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 |
{ "type": "fulltext-index", "name": "pcap.telco.pcapEmbeddingIndex", "uuid": "2fd519311de37177", "sourceType": "gocbcore", "sourceName": "pcap", "sourceUUID": "a576b1ee361c33974e47371d03098b72", "planParams": { "maxPartitionsPerPIndex": 1024, "indexPartitions": 1 }, "params": { "doc_config": { "docid_prefix_delim": "", "docid_regexp": "", "mode": "scope.collection.type_field", "type_field": "type" }, "mapping": { "analysis": {}, "default_analyzer": "standard", "default_datetime_parser": "dateTimeOptional", "default_field": "_all", "default_mapping": { "dynamic": false, "enabled": false }, "default_type": "_default", "docvalues_dynamic": false, "index_dynamic": true, "store_dynamic": true, "type_field": "_type", "types": { "telco.sessions": { "dynamic": false, "enabled": true, "properties": { "carrier": { "dynamic": false, "enabled": true, "fields": [ { "analyzer": "en", "index": true, "name": "carrier", "store": true, "type": "text" } ] }, "embedding_vector": { "dynamic": false, "enabled": true, "fields": [ { "dims": 1536, "index": true, "name": "embedding_vector", "similarity": "dot_product", "type": "vector", "vector_index_optimized_for": "recall" } ] }, "jitterMs": { "dynamic": false, "enabled": true, "fields": [ { "index": true, "name": "jitterMs", "store": true, "type": "number" } ] }, "lossPct": { "dynamic": false, "enabled": true, "fields": [ { "index": true, "name": "lossPct", "store": true, "type": "number" } ] }, "proto": { "dynamic": false, "enabled": true, "fields": [ { "analyzer": "en", "index": true, "name": "proto", "store": true, "type": "text" } ] }, "qualityLabel": { "dynamic": false, "enabled": true, "fields": [ { "analyzer": "en", "index": true, "name": "qualityLabel", "store": true, "type": "text" } ] }, "region": { "dynamic": false, "enabled": true, "fields": [ { "analyzer": "en", "index": true, "name": "region", "store": true, "type": "text" } ] }, "retransmits": { "dynamic": false, "enabled": true, "fields": [ { "index": true, "name": "retransmits", "store": true, "type": "number" } ] } } } } }, "store": { "indexType": "scorch", "segmentVersion": 16 } }, "sourceParams": {} } |
Vamos a explicarlo en lenguaje sencillo:
-
- vector de incrustación → Esta es la columna vertebral semántica, un campo vectorial donde se producen las consultas de similitud. Hemos elegido producto escalar como métrica de similitud, ya que funciona bien con las incrustaciones de OpenAI.
- región, proto, transportista → Indexados como campos de texto para que podamos filtrar por región de telecomunicaciones, protocolo de paquetes o operador.
- porcentaje de pérdidas, jitterMs, retransmite → Campos numéricos que permiten consultas de rango (por ejemplo, “sesiones con fluctuación > 50 ms”).
- Etiqueta de calidad → Nuestra función Eventing ya etiquetaba las llamadas como “sanas” o “degradadas”, lo que ahora se convierte en un campo de búsqueda.
Esta estructura dual — vector + metadatos — es lo que hace que la solución sea tan potente. No estás obligado a elegir entre similitud semántica y filtrado estructurado; puedes combinar ambos en una sola consulta.
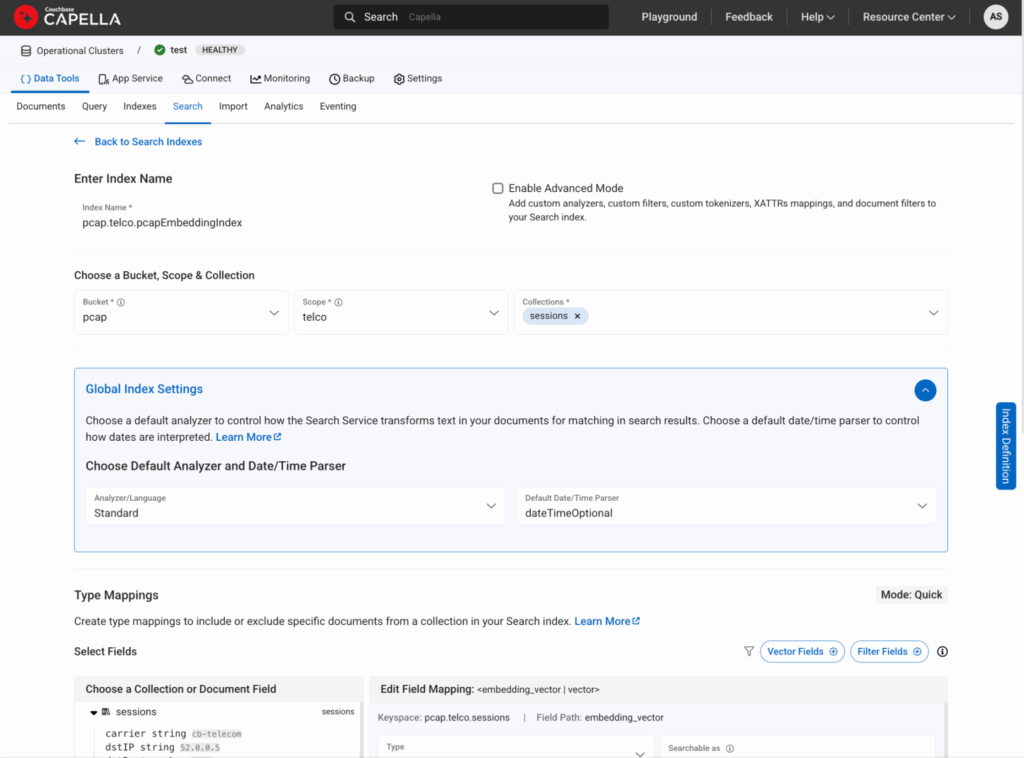
Figura 7: Así es como se crearía un índice vectorial desde la pestaña Buscar.
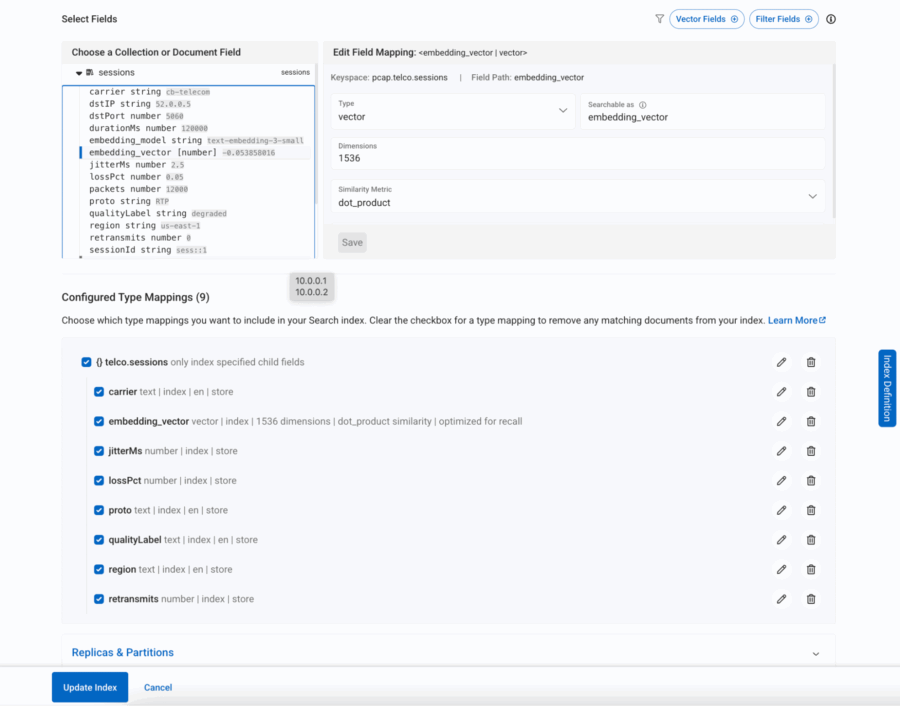
Figura 8: Todos los campos obligatorios dentro del sesión El documento se incluye en la búsqueda.
Destacando la detección de anomalías con la búsqueda híbrida
Por último, veamos la verdadera recompensa: la detección de anomalías impulsada por búsqueda híbrida de vectores.
Imagina que has recibido una avalancha de quejas sobre cortes en las llamadas en Nueva York. Podrías ejecutar una consulta como:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
SELECT META(s).id, s.sessionId, s.summaryText, s.qualityLabel, s.region, s.proto, s.carrier FROM `pcap`.`telco`.`sessions` AS s WHERE SEARCH(s, { "fields": ["*"], "knn": [ { "k": 10, "field": "embedding_vector", "vector": [/* ... fill with your actual embedding ... */], "filter": { "conjuncts": [ { "match": "degraded", "field": "qualityLabel" }, { "match": "us-east-1", "field": "region" }, { "match": "SIP", "field": "proto" }, { "match": "cb-telecom", "field": "carrier" } ] } } ] }); |
Esta consulta dice:
-
- Encuéntrame las 10 sesiones más similares a una degradado Llamada SIP (similitud semántica)
- Pero solo si ocurrieron en us-este-1, eran llamadas SIP.
Lo que obtienes a cambio no es solo una lista de “decisiones erróneas”, sino un conjunto de anomalías relacionadas semánticamente que le ayuda a identificar la causa raíz. Si todos se producen en un mismo operador, acaba de aislar un problema del proveedor. Si se producen picos a determinadas horas, tal vez se trate de un cuello de botella en el enrutamiento.
Aquí es donde la búsqueda vectorial deja de ser “matemáticas geniales” y comienza a ofrecer resultados. visión operativa real.
La búsqueda vectorial como columna vertebral de las aplicaciones agenticas
Las aplicaciones agenticas están diseñadas no solo para recuperar información, sino también para interpretarla y actuar en consecuencia. Ya se trate de un copiloto de atención al cliente, un motor de detección de fraudes o un detector de anomalías en telecomunicaciones, estos sistemas necesitan:
-
- Recuerdo contextual: Recuperar el derecha información, no solo coincidencias literales.
- Capacidades de razonamiento: Comprender las relaciones y las intenciones.
- Autonomía: Activa flujos de trabajo y decisiones sin intervención humana.
Los tres pilares se apoyan en búsqueda vectorial. Sin incrustaciones, los agentes carecen de memoria. Sin búsqueda por similitud, carecen de razonamiento. Sin contexto semántico, no pueden actuar de manera eficaz.
Por eso la búsqueda vectorial es más que un nuevo método de búsqueda: es la base de conocimientos de la era de la agencia.
Conclusión y próximos pasos
La búsqueda vectorial está transformando las industrias al cambiar la búsqueda de palabras clave al contexto. Impulsa todo, desde la detección de anomalías en las telecomunicaciones hasta los copilotos de atención al cliente y la detección de fraudes. En esencia, sienta las bases para aplicaciones agénticas — Sistemas inteligentes capaces de recordar, razonar y actuar.
Couchbase lo hace realidad con su combinación de Búsqueda de texto completo, indexación vectorial y eventos, lo que permite a las empresas poner en práctica la búsqueda semántica en tiempo real.
En la próxima entrega, daremos un paso más allá: exploraremos cómo LLM + búsqueda vectorial Converger para crear aplicaciones agenticas verdaderamente autónomas que no solo comprendan el contexto, sino que también generen conocimientos y tomen medidas proactivas.