Grandes datos
Apache Hadoop el plataforma de big data. Se diseñó para obtener valor del volumen. Puede almacenar y procesar mucho de datos en restobig data. Se diseñó para el análisis. No se diseñó para la velocidad.
Es un almacén. Es eficiente para añadir y quitar muchos artículos de un almacén. Es no eficiente para añadir y eliminar un solo artículo de un almacén.
Los conjuntos de datos se almacenan. La información se genera a partir de datos históricos y se puede recuperar. Volumen puro

Datos rápidos
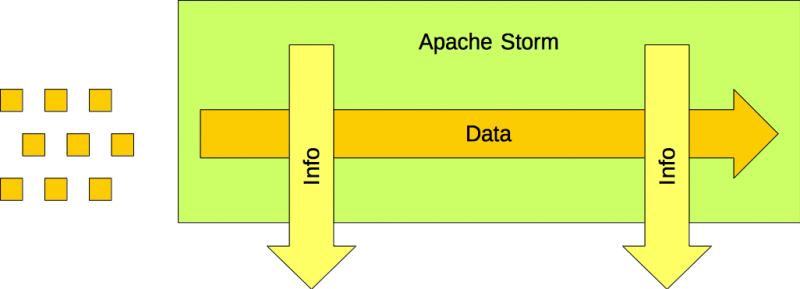
Apache Storm es el plataforma de procesamiento de flujos. Se diseñó para obtener valor de la velocidad. Puede procesar datos en movimientodatos rápidos. No fue diseñado para el volumen.
Es una cinta transportadora. Los artículos se colocan en la cinta transportadora, donde pueden procesarse hasta que se retiran de ella. Los artículos no permanecen en la cinta transportadora indefinidamente. Se colocan en ella. Se retiran de ella.
Los datos se canalizan. La información se genera a partir de los datos actuales, pero no puede recupérala. Velocidad pura
El GAP
Sin embargo, falta algo. Cómo acaban los artículos colocados en una cinta transportadora en un almacén?
Couchbase Server es el base de datos NoSQL empresarial. Está diseñada para obtener valor de una combinación de volumen y velocidad (y variedad).
Se trata de una caja. Al final de la cinta transportadora, los artículos se añaden a las cajas. Es eficaz añadir y retirar artículos de una caja. Es eficaz añadir y retirar cajas de un almacén.
Los datos se almacenan y se recuperan. Volumen + Velocidad + Variedad

La solución
Una arquitectura de big data en tiempo real incluye un procesador de flujos como Apache Storm, una base de datos NoSQL empresarial como Couchbase Server y una plataforma de big data como Apache Hadoop.
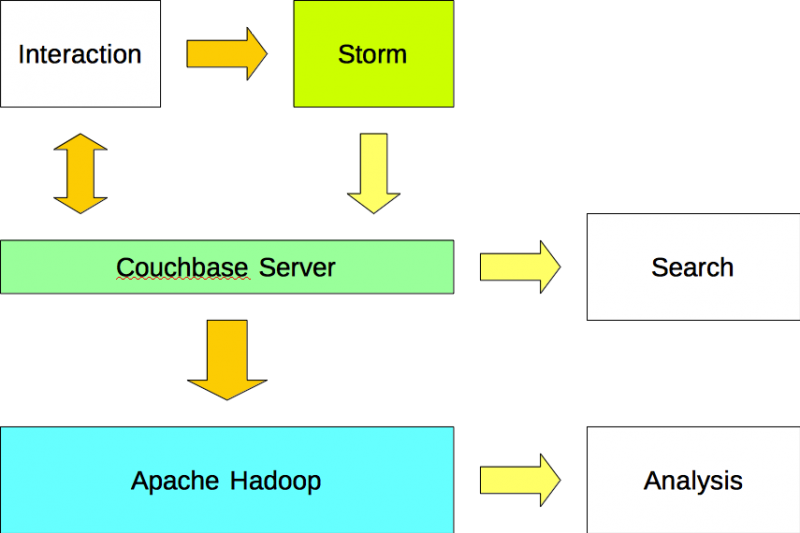
Opción #1
Las aplicaciones leen y escriben datos en Couchbase Server y escribir datos en Apache Storm. Apache Storm analiza flujos de datos y escribe los resultados en Couchbase Server utilizando un plugin (es decir, bolt). Los datos se importan a Apache Hadoop desde Couchbase Server utilizando un plugin Sqoop.
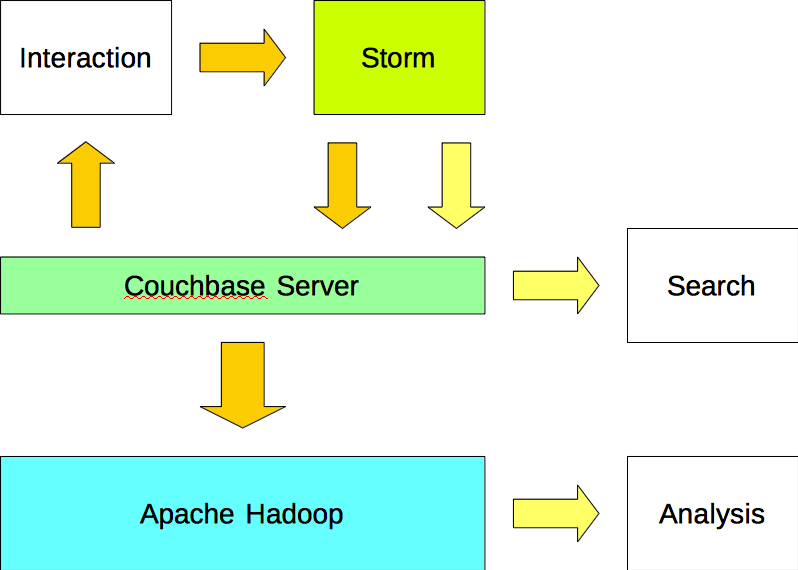
Opción #2
Las aplicaciones escriben datos en Apache Storm y leen datos de Couchbase Server. Apache Storm escribe tanto los datos (entrada) como la información (salida) en Couchbase Server. Los datos se importan a Apache Hadoop desde Couchbase Server mediante un plugin de Sqoop.
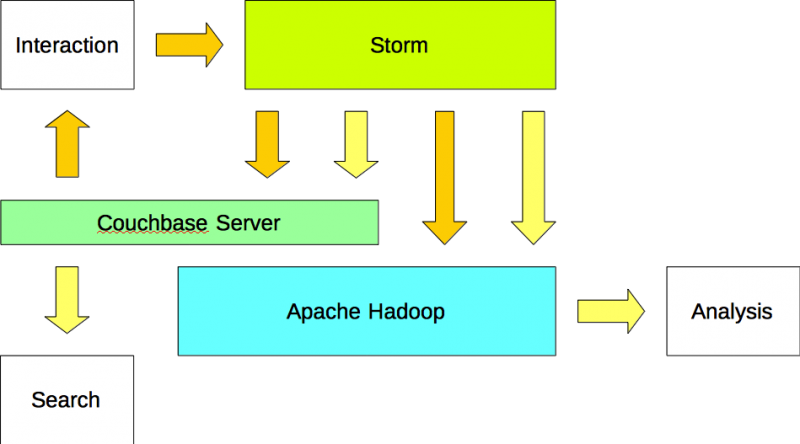
Opción #3
Las aplicaciones escriben datos en Apache Storm y leen datos de Couchbase Server. Apache Storm escribe los datos (entrada) tanto en Apache Couchbase como en Apache Hadoop. Además, Apache Storm escribe la información (salida) tanto en Couchbase Server como en Apache Hadoop.
Resumen
Este artículo describe tres arquitecturas de big data en tiempo real. Sin embargo, lo mejor de diseñar una arquitectura de big data en tiempo real es que es como jugar con Legos. Los componentes vienen en muchas formas y tamaños, y depende del arquitecto o arquitectos seleccionar y conectar las piezas necesarias para construir la solución más eficiente y eficaz posible. Es un reto apasionante.
Únete a la conversación en reddit (enlace).
Únete a la conversación en Hacker News (enlace).
Ejemplos
Vea cómo estos clientes empresariales están aprovechando Apache Hadoop, Apache Storm y más con Couchbase Server.
LivePerson - Apache Hadoop + Apache Storm + Servidor Couchbase
QuestPoint - Apache Hadoop + Servidor Couchbase
McGraw-Hill Education - Servidor Elasticsearch + Couchbase
AOL - Apache Hadoop + Servidor Couchbase
AdAction - Apache Hadoop + Servidor Couchbase
Referencia
Conectores de servidor Couchbase (enlace)
Gracias, muy buena lectura. Me parece que la 2ª opción es la más limpia, pero todas son plausibles.
Gracias. Otro enfoque sería configurar Apache Storm para escribir los datos analizados (salida) en tiempo real a Couchbase Server mientras se escriben los datos en bruto (entrada) a Apache Hadoop a través de escrituras por lotes.
[...] La brecha entre Big Data y Fast Data [...]