TLDR: Couchbase anuncia nuevos servicios de IA en la plataforma de datos para desarrolladores Capella para crear y operar de forma eficiente y eficaz Agentes impulsados por GenAI. Estos servicios incluyen Modelo de servicio para el alojamiento privado y seguro de LLM de código abierto, el Servicio de datos no estructurados para procesar PDF e imágenes para su ingestión, el Servicio de vectorización para la transmisión en tiempo real, el almacenamiento y la indexación de incrustaciones vectoriales, un Catálogo de agentes proporcionar un marco extensible para ayudar a los desarrolladores a añadir nuevas capacidades a la pila de agentes, y Funciones de IA para enriquecer los datos utilizando la potencia de los LLM, recopilar artefactos de datos clave generados por los agentes y establecer barandillas para la evolución de las operaciones a medida que se desarrollan los LLM y los agentes.
Presentación de Capella AI Services
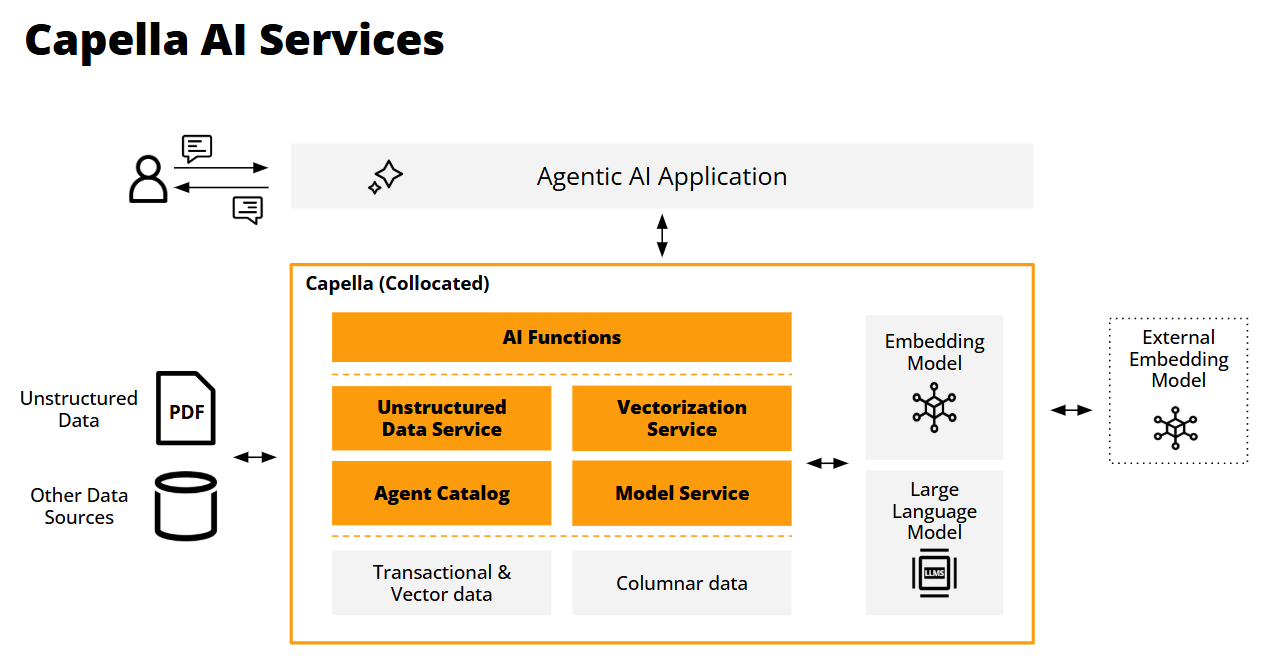
Couchbase se complace en anunciar una serie de nuevos servicios de IA que mejorarán la Plataforma Capella para ayudar a los desarrolladores a crear e implantar impulsado por GenAI agentes y aplicaciones agénticas. Los agentes son programas autónomos diseñados para utilizar interacciones de lenguaje natural para realizar tareas o resolver problemas tomando decisiones basadas en datos, intercambios conversacionales con grandes modelos lingüísticos y contexto ambiental, todo ello sin intervención humana.
Los agentes no sólo procesarán entradas textuales, sino que también incorporarán información visual y sonora en la ejecución de sus tareas. Los servicios de IA de Capella ayudarán a los desarrolladores con muchos de los pasos de procesamiento de datos necesarios al utilizar técnicas de generación aumentada por recuperación (RAG), y aprovecharán las innumerables herramientas y marcos del ecosistema RAG para interactuar eficazmente con grandes modelos lingüísticos. Además, estos servicios ayudarán a los arquitectos y a los equipos de DevOps a gestionar el funcionamiento de los agentes a lo largo del tiempo.

Nuevos servicios de IA de Capella
-
- Modelo de servicio: Alojamiento de modelos de lenguaje externo, local e integrado para minimizar las latencias de procesamiento acercando los modelos a los datos y su consumo. Este enfoque ayuda a abordar los riesgos de privacidad, coherencia e intercambio de datos, garantizando que los datos nunca salgan de la VPC del cliente. Capella alojará modelos de Mistral y Llama3.
- Servicio de vectorización: Para crear, transmitir, almacenar y buscar incrustaciones vectoriales con el fin de mejorar la calidad y precisión de las conversaciones y facilitar contextos de interacción continuos, ya que los LLM evolucionan y pueden perder contexto.
- Servicio de datos no estructurados: Transforma datos no estructurados, como documentos de texto, PDF y tipos de medios como imágenes y grabaciones, en "trozos" de información semántica legible (por ejemplo, frases y párrafos) para generar vectores utilizables. Este paso de preprocesamiento amplía la gama de casos de uso que pueden soportar los agentes.
- Catálogo de agentes: Acelera el desarrollo de aplicaciones agénticas con un repositorio centralizado de herramientas, metadatos, avisos e información de auditoría para gestionar el flujo, la trazabilidad y la gobernanza de LLM. También automatiza el descubrimiento de las herramientas de agentes pertinentes para responder a las preguntas de los usuarios y refuerza las líneas de seguridad para que los intercambios de agentes sean coherentes a lo largo del tiempo.
- Funciones de IA: Aumente la productividad de los desarrolladores integrando el análisis de datos basado en IA directamente en los flujos de trabajo de las aplicaciones mediante la conocida sintaxis SQL++. Esto acelera la productividad de los desarrolladores al eliminar la necesidad de herramientas externas, codificación personalizada y gestión de modelos. Las funciones de Capella AI incluyen resumen, clasificación, análisis de sentimientos y enmascaramiento de datos.
A través de su plataforma unificada de datos para desarrolladores, Couchbase capacita a los clientes para ofrecer sus aplicaciones más críticas en este nuevo panorama impulsado por la IA, ofreciendo un suministro de datos persistente y con estado para las interacciones de la IA, la funcionalidad de las aplicaciones de agentes y el desarrollo y mantenimiento continuos de estos sistemas.
¿Por qué necesitamos servicios de IA?
El desarrollo y la explotación de aplicaciones agenéticas plantearán muchos nuevos retos centrados en los datos. Entre ellos figuran:
Trabajar con GenAI cambia radicalmente los flujos de trabajo cotidianos de los desarrolladores
Mientras que el concepto de Agentes es sencillo -crear programas basados en tareas que resuelven cosas de forma independiente, como hacer reservas en tu nombre-, el desarrollo de Agentes requiere nuevas técnicas más allá de la RAG para garantizar un comportamiento fiable y de confianza. Esto implica mantener un comportamiento consistente dentro de cada Agente y cada intercambio LLM para invocaciones continuas de Agentes a lo largo del tiempo. En lugar de limitarse a diseñar aplicaciones basadas en bases de datos, los desarrolladores tendrán que incorporar interacciones de Agentes entre las bases de datos y la funcionalidad de la aplicación. Nuestros nuevos Servicios de IA ayudarán a los desarrolladores a aprovechar estos nuevos flujos de trabajo y a ser competentes en el uso de LLMs en su desarrollo.
Todos deben aprender nuevas tecnologías y técnicas operativas
La creación de funcionalidades basadas en IA introduce nuevos flujos de trabajo de desarrollo, integraciones y procesos en el ciclo de vida de desarrollo de software actual. Las interacciones de IA se volverán programáticas, y nuevos tipos de datos, como vectores, serán generados y consumidos durante estos intercambios. Los nuevos servicios de IA introducidos en Couchbase Capella ayudarán a los desarrolladores y arquitectos a abordar estos nuevos procesos, incluyendo la automatización de RAG (Generación Aumentada de Recuperación)Los servicios de IA de Capella ayudarán a los DevOps a asegurarse de que los agentes hacen lo que se espera de ellos y no crean sorpresas. Los servicios de IA de Capella ayudarán a DevOps a asegurarse de que los agentes están haciendo lo que esperábamos y no crean sorpresas.
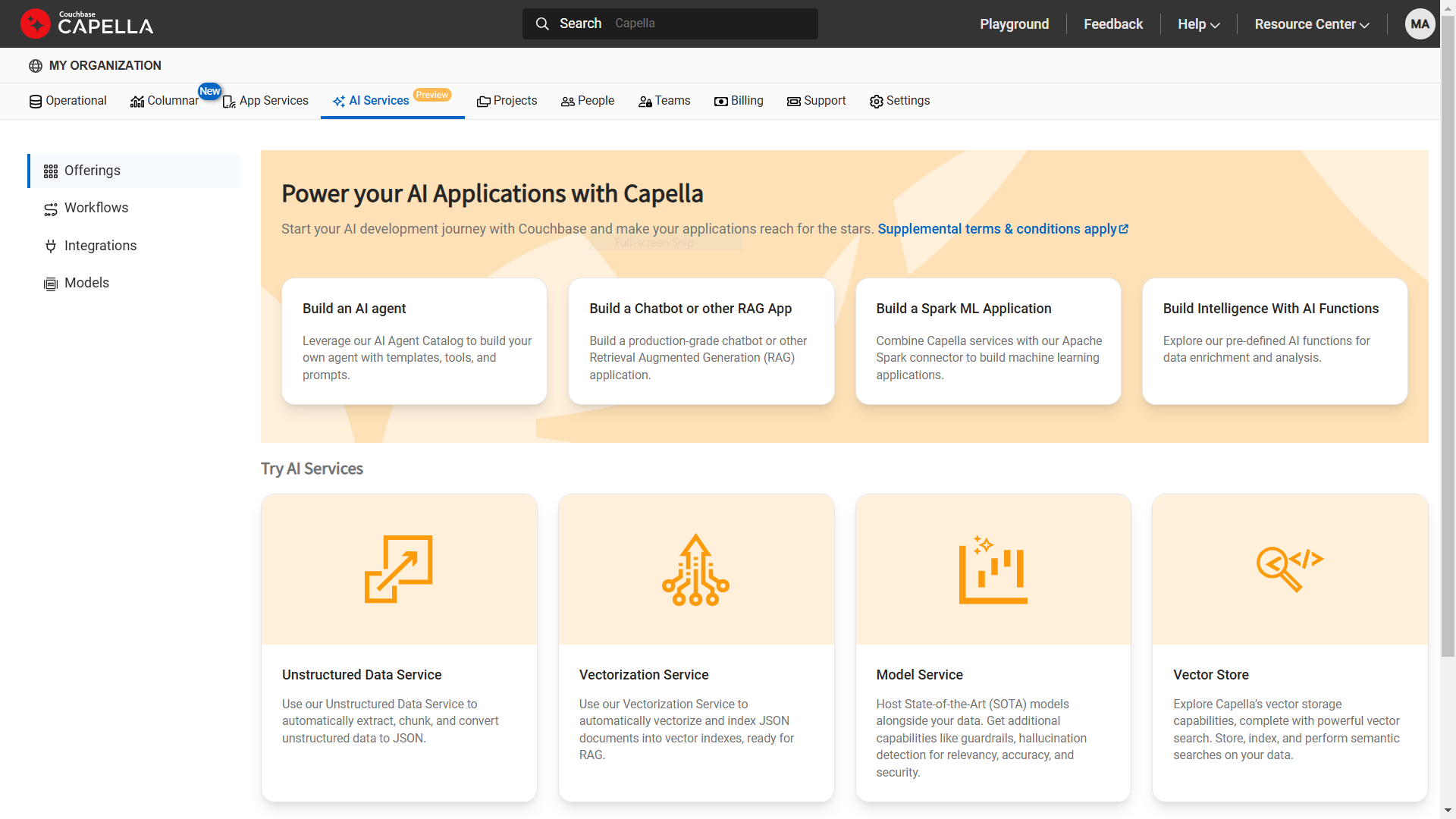
Interfaz de gestión basada en web de Capella AI Services
Ofrecer datos propios a modelos privados
Según nuestras conversaciones con los clientes, lo que más miedo da de GenAI es compartir datos que no deberían compartirse públicamente. Sin embargo, en muchos casos se necesitan datos de propiedad de la empresa para garantizar que el conocimiento del LLM sea lo más preciso y contextual posible. Esto puede requerir enseñar el modelo con datos empresariales confidenciales y privados que no pueden divulgarse públicamente. Para cumplir este requisito, los LLM deben privatizarse o alojarse de forma privada y no exponerse al público. Para satisfacer esta necesidad, Capella alojará los modelos lingüísticos de forma privada en nombre de sus clientes.
Conversaciones intensivas con LLM
La búsqueda vectorial y los asistentes de chatbot son sólo las primeras aplicaciones de GenAI. Representan interacciones únicas con un modelo lingüístico. Lo que veremos en un futuro próximo es la evolución de la RAG para abarcar una explosión de intercambios múltiples con los LLM, similar a una multitud de conversaciones de ida y vuelta. También veremos Agentes trabajando en concierto como un conjunto, conversando con múltiples modelos a través de múltiples conversaciones continuas para completar tareas más grandes y complejas. Cuando conocimos por primera vez la RAG, se presentó como un flujo de trabajo de una sola ruta con muchos pasos. En realidad, los flujos de trabajo de los agentes serán recursivos y mucho más complejos.
Reducir la latencia para mejorar la experiencia del usuario
La latencia es el enemigo de la IA. Es especialmente intolerable cuando intervienen personas reales. Como hemos mencionado antes, esperamos reducir la latencia alojando los modelos junto a su suministro de datos. Al igual que Netflix, creemos que los contenidos deben procesarse cerca de donde se consumen: en los dispositivos móviles de los usuarios. Una gran ventaja de Capella es que ofrece un almacén de datos local, Couchbase Lite, para procesar los intercambios LLM directamente en los dispositivos. Esto ayudará a mantener contentos a los usuarios porque no tendrán que esperar exclusivamente a que los LLM alojados en la nube respondan.
Preprocesamiento de datos no estructurados antes de la vectorización
La incorporación de datos estructurados y no estructurados en el proceso de GAR es esencial. Los datos no estructurados, como los archivos PDF, no están inmediatamente listos para ser consumidos por un LLM. Estos datos deben analizarse, dividirse en fragmentos lógicos y transformarse en texto simple o JSON antes de que puedan introducirse en un modelo de incrustación o en la base de conocimientos de un LLM. Esto se denomina a menudo "Preprocesamiento y Chunking", o preparación de datos no estructurados para su inclusión en los procesos RAG de un Agente. Capella ofrecerá un servicio de datos no estructurados para preparar objetos como PDF que se utilizarán como fuentes para incrustaciones vectoriales y su indexación. Durante este proceso, extraemos metadatos importantes, troceamos y vectorizamos los datos en función de su contenido semántico y generamos incrustaciones vectoriales de alta calidad para obtener información sobre IA.
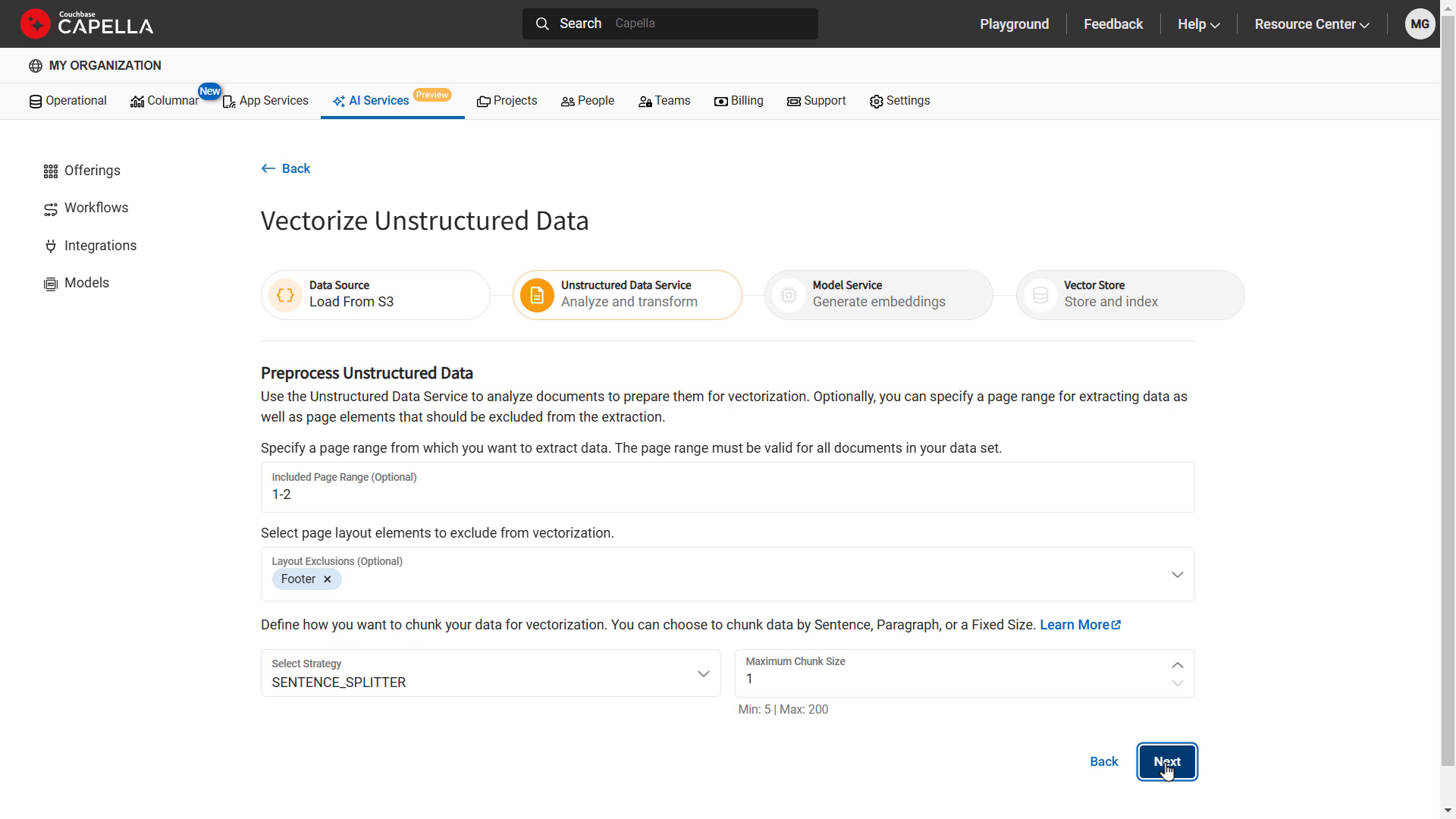
Flujo de trabajo basado en web para la gestión de datos no estructurados mediante servicios de IA
Vectorización: creación y transmisión de vectores en tiempo real
Una vez procesados, estos datos no estructurados, además de los datos operativos y semiestructurados habituales, pueden introducirse en un modelo de incrustación para crear índices vectoriales (vectores) que sirvan de guías contextuales dentro de un aviso a un LLM. El proceso de creación de vectores como un servicio de flujo continuo permite establecer el contexto y crear vectores en tiempo real a medida que el agente se ejecuta. La cantidad de dimensiones e incrustaciones de vectores podría ser inmensa, alcanzando potencialmente los miles de millones. Este volumen supondrá un reto para las plataformas de datos existentes, que no están preparadas o no están suficientemente diseñadas para gestionar tal escala.
La especialización impulsará la necesidad de muchos modelos y muchos agentes
Los desarrolladores tendrán que hacer un seguimiento de los programas que interactúan con los modelos de IA, porque los modelos evolucionarán con el tiempo. Para mantener actualizados sus conocimientos, los modelos lingüísticos tendrán que hacerse más pequeños para poder reducir sus ciclos de aprendizaje. A medida que los modelos se especialicen, también se centrarán más en temas o contextos específicos, como un modelo que prediga patrones meteorológicos, evalúe resultados de pruebas médicas o comprenda leyes físicas concretas. Del mismo modo, los agentes también se especializarán en su funcionalidad. Esto creará la necesidad de un índice de catálogo que mantenga diferentes agentes y sus interacciones con modelos especializados.
Mantener un contexto persistente en el tiempo
Los agentes de larga duración necesitarán que los datos persistan para garantizar que los resultados del agente sean coherentes y los esperados a lo largo del tiempo. Esto supone un reto porque los grandes modelos lingüísticos no mantienen el contexto de una conversación a otra. Necesitan que se les vuelva a informar de su contexto de una sesión a otra, lo que exige que se conserven las conversaciones.
Los conocimientos LLM cambian con el tiempo, y los agentes necesitan guardarraíles
El problema de la conservación de los datos se complica aún más por el hecho de que los conocimientos de un LLM son dinámicos y crecientes, lo que significa que el modelo puede no dar la misma respuesta a una pregunta de un momento a otro. Por lo tanto, los desarrolladores deben incorporar rutinas de verificación de la fiabilidad para comprobar los resultados esperados y la coherencia de los intercambios del LLM a lo largo del tiempo. Esto significa que la conversación LLM de ayer debe ser preservada y persistida para que pueda ser usada como datos de validación para la interacción LLM de hoy. Esto significa que las interacciones de los Agentes con los LLM -junto con sus entradas, salidas de respuesta y metadatos contextuales- deben conservarse en cada conversión para una mayor validación de la precisión. Esto generará una gran cantidad de datos que deben almacenarse en una base de datos. Base de datos preparada para IA, como Couchbase.
Construir un agente implica seleccionar un LLM para el razonamiento y la llamada a funciones, gestionar herramientas y datos, mantener avisos, optimizar con caché e iterar en busca de calidad. El sitio Catálogo de agentes de Couchbase se integra a la perfección con la plataforma de desarrollo Capella para agilizar este proceso y reducir la carga cognitiva de los desarrolladores. Nuestro catálogo multiagente ayuda a los desarrolladores a gestionar las herramientas, los conjuntos de datos, las plantillas, los datos de referencia y los avisos en todos los agentes. Admite la selección semántica de herramientas para consultas, proporciona herramientas prediseñadas y ofrece la mejor infraestructura de servicio de modelos de su clase para alojar LLM. Entre las funciones adicionales se incluyen la aplicación de guardarraíles, la detección de alucinaciones, la auditoría del linaje de consultas, la previsión y la integración de RAG-as-a-Service (RAGaaS) para la evaluación de la calidad de los agentes.
Minimizar los costes de las conversaciones de LLM
Las conversaciones con los LLM serán costosas y lentas. Los agentes entablarán multitud de conversaciones con los LLM, lo que supone un reto importante. Por eso cada CSP está entusiasmado con los modelos que soporta (Bedrock/Claude, Gemini, ChatGPT) como futuros generadores de ingresos. Con el rendimiento de los agentes, los milisegundos cuestan dinero. Couchbase aprovechará múltiples ventajas de rendimiento ya incorporadas en Capella para que las interacciones LLM sean más rápidas y rentables. Entre ellas se incluye la capacidad de almacenar en caché las consultas más comunes, lo que minimiza las visitas redundantes a un LLM y ofrece almacenamiento en caché semántico y conversacional de los resultados de LLM para las respuestas más comunes. Capella también ofrece funciones de ajuste del rendimiento, como el escalado multidimensional y la replicación entre centros de datos. Esperamos que Capella ofrezca a los clientes una convincente ventaja de precio/rendimiento.
Stephen O'Grady, analista principal de RedMonk, profundiza en los retos y las oportunidades: "A medida que la IA continúa transformando la empresa, está planteando nuevos retos significativos para la infraestructura. Para aplicar la IA a sus negocios actuales, las empresas se han visto obligadas a integrar fuentes de datos grandes y dispares y una serie de modelos de IA en rápida evolución mediante flujos de trabajo complicados. Esto ha creado la demanda de una plataforma de datos alternativa y multimodal con acceso no sólo a los datos de formación necesarios, sino también a los modelos para aplicarlos. Esta es la oportunidad para la que se han creado los nuevos Capella AI Services de Couchbase."
Conclusión: Bienvenido a nuestro mundo de IA.
Couchbase está ampliando su plataforma de datos para desarrolladores para incluir una serie de servicios de IA que apoyen tanto la creación como el funcionamiento de aplicaciones agénticas. Estos servicios responden a múltiples necesidades acuciantes de persistencia y organización de datos cuando los agentes están en funcionamiento, y simplifican muchos de los quebraderos de cabeza iniciales a los que se enfrentan los desarrolladores al crearlos. Estos servicios se ofrecerán a clientes y clientes potenciales cualificados como una vista previa privada. Estamos muy entusiasmados con lo que estamos introduciendo para dar soporte a aplicaciones críticas en este nuevo mundo de la IA. ¡Únase a nosotros!
Para más información
-
- Leer el comunicado de prensa
- Echa un vistazo Servicios de IA de Capella o Inscríbase en el Vista previa privada
- Blog: ¿Qué es el GAR?
- Blog: ¿Qué es un agente de IA?
- Inscríbase en el webcast: Hoja de ruta para la nueva era de los agentes de IA: retos y oportunidades
