Every benchmark raises few question marks as it answers some. So with every benchmark, you need to sift through the data yourself to get the full scoop. I have been benchmarking for a while starting at the TPC era with benchmark wars and not here at Couchbase where we drive performance deep into the product through internal and external benchmarks with many of our customers and partners.
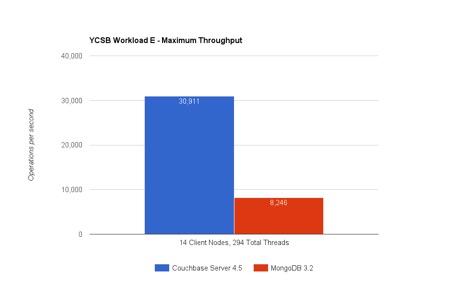
I hope some of you have already seen the benchmark results from Avalon comparing MongoDB 3.2 and Couchbase Server 4.5. You can find the full disclosure here. I am going to dig deeper into some of the details of the benchmark here and try to explain why Couchbase Server is faster in both query execution (YCSB Workload E) and key value access (YCSB Workload A). Ok let’s tear apart the results:
Workload E: Threaded Conversations Query
Workload E in YCSB simulates a threaded conversation and the objective is to retrieve a range query as fast as possible that is looking for ~50 conversations (items). There is also a light insert workload that accompanies the query (%5 of operations are INSERTs). So How is Couchbase Server able to execute >3.7X time more queries/sec vs MongoDB?
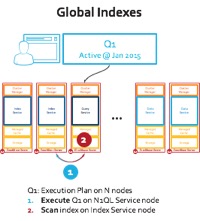
#1 Query Execution with Global Indexes in Couchbase Server
Both Couchbase and MongoDB distribution (sharding) allows the data, to be distributed evenly across nodes. Each node takes an equal slice of the total items. This test has 150 million items distributed across 9 nodes. Workload E range scan query operates over an index. MongoDB indexes partition to align to the data on each node. That is every node gets an index partition that locally indexes the data. In this test, Couchbase Server uses global indexes instead. Global Indexes independently partition the index.
Why is this important? This means MongoDB query execution require a scatter-gather across the 9 server nodes it has: see the local index picture below. Instead Couchbase Server N1QL engine uses 1 of the indexes to do a single network hop to perform the range scan: see the global index picture below.
 |
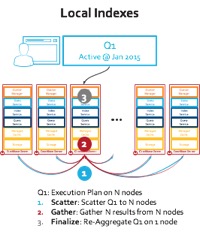 |
Figure: Query Execution with Global and Local Index Distribution
There is a fundamental problem here with local index architecture: In step#1 the range query arrives is distributed to all nodes. In this model, any one node in the cluster cannot answer the question as the index used for query execution is distributed aligned to data distribution. Every node has to execute the same range scan (by the way, query in YCSB Workload E runs a range scan with “order by” and “limit 50”) and grab the items that fall into the range. That means you have node-count*50 items travelling to coordinating node. This test executes thousands of queries and the waste replicates until the network gets saturated! But that isn’t the most serious problem with local indexes…
Let’s say, we add a new node, or expand this cluster to 100 nodes, each new node still has to perform the query. You cannot scale the query by adding nodes! In fact things get worse as network saturates between nodes. You also waste a large sum of CPU capacity and engage all nodes all the time.
In case of a query execution in N1QL with global index, picture is much different. N1QL pushes down “order by” & “limit” to the index and brings in only 50 items. No network overload… In fact N1QL adds more efficient retrieval using a compressed resultset (RAW). You can add a node or expand to 100 nodes, and you will see real benefits in throughput. In fact you can repeat the YCSB Workload E test with 20 or 30 nodes, I’d expect to see a bigger difference between Couchbase Server and MongoDB throughputs.
#2 Memory Optimized Indexes
Global indexes are great but they are challenging to maintain. The global index that is residing on 1 of the nodes is keeping up with updates going on across the entire cluster – or at least all the mutations relevant to the index. You need an extremely efficient index structure that can be keep up with updates to data while performing high speed scans.
Couchbase Server 4.5 introduced a new storage architecture for global indexes called memory-optimized indexes (MOI). MOI optimizes for memory storage and has a smaller footprint in memory and uses a lock free index maintenance logic to index heavy updates to data with massive parallelism. MongoDB uses a version of a B-Tree index that is fairly classic among many relational and NoSQL databases. Couchbase Server comes with HB+Tree and some HB+Trie indexes as well. They are used with the Standard Storage mode of Indexes and in Map-Reduce Views. What we found however is this new skiplist structure and lock-free approach increases the index maintenance and scan performance greatly in the case of global indexes.
Figure: Skiplist lock-free indexing with memory-optimized global indexes
To give you a quick sense of the difference we are seeing, here is the comparison of Couchbase Server Indexing with standard and memory-optimized index storage modes. Memory optimized indexes are >20x faster in query response times.
Even though some of these features are not in use in the benchmark, it is worth mentioning that Couchbase Server can index array structures with multi-level nesting. For example, movies and showtimes may be normalized into 2 separate tables in relational world, however, both MongoDB and Couchbase models data with a single “movie” document that contain an array of showtimes. To update showtimes for a single movie, you issue a single update. However an array index would receive many updates as it indexes each individual showtime. The update rate for the index amplify equal to the size of the array… So all this means one thing: Even systems that may have a low update rate to items, may need array indexes that needs to keep up with 10x, 20x or 100x the amount of updates, depending on the size of the embedded arrays in documents. MOI helps greatly under these conditions as it can keep up with >100Ks of updates with enough computational resources.
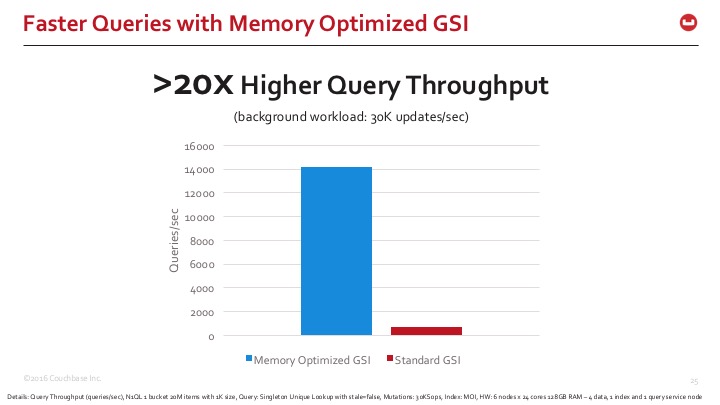
Deeper Dive into YCSB Workload E Results
One consolidated view that tells the whole story is the %95th latency and throughput overlaid graph. This is how I view all performance results personally. – If you are the benchmarking type, you know the saying: “it makes no sense to look at latency without throughput and, visa versa”.
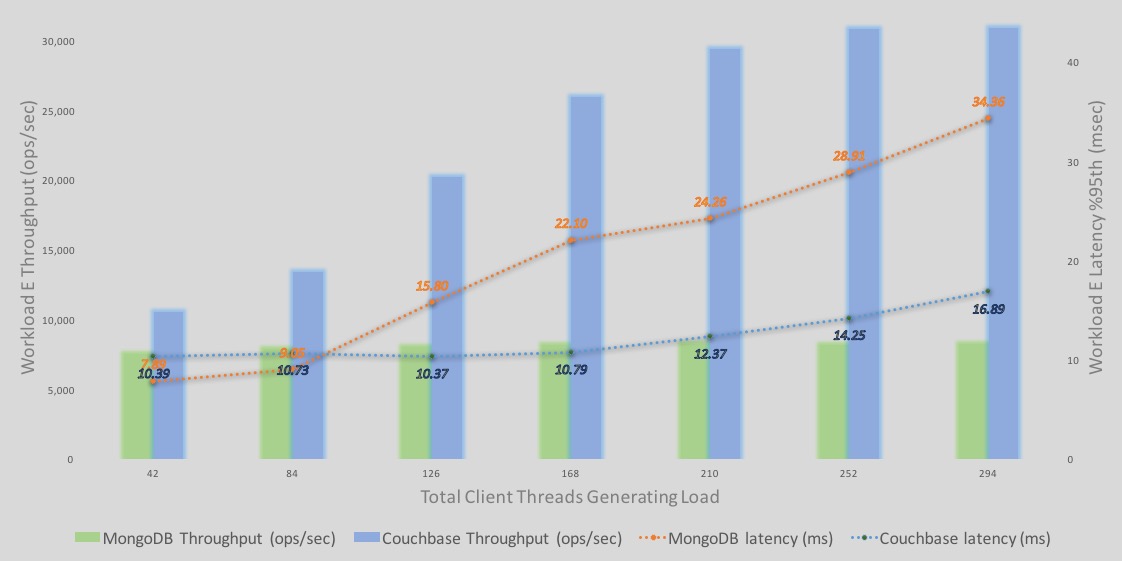
Here is a detailed breakdown of the Workload E query execution throughputs and latencies.
-The bars represent throughput – blue is Couchbase and green is MongoDB. Y Axis is the throughput numbers.
-The lines represent latency – blue is Couchbase and orange is MongoDB. Secondary Y Axis on the right, represent latency numbers with descending latency line represents worse or higher latency. In other words, secondary axis for latency is a descending axis (dropping dotted lines represent higher latency).
A few observations;
–Throughput: Couchbase Server throughput continues to increase higher with more load. MongoDB throughput increases as well but only a small amount before it quickly levels off.
–Latency for Couchbase start off higher than MongoDB (42 and 84 clients). However Couchbase Server throughput is higher under in both 42 and 84 client loads. I’d bet that under the same throughput, latencies in both engines may be similar under this light load. However as the load increase, latencies increase. However with the effect of global indexes and MOI, Couchbase pushes better throughput until we get to >250 clients. Couchbase Server also levels off at this point.
Workload A: Recording and Reading User Sessions
Workload A in YCSB simulates a workload that capture and read recent user actions with 50% reads and 50% updates. This is a basic key/value workload. You will notice that the operations/sec is much higher here. This is because each operation deals with a single item only. Workload E on the other hand handles 50 items per query.
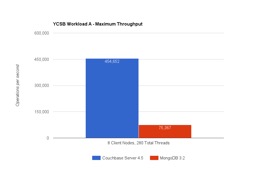
You may roll your eyes and think, simple read and write over 1K of data isn’t greatly challenging. However doing this efficiently is hard. Many databases tune to reading or writing but not both! When you put both together, it gets challenging to keep up. But How is Couchbase Server able to execute 6X time more operations on the same HW (9 node c3.8xlarge on Amazon Web Services) vs MongoDB?
#3 Faster Cache Data Access
One of the important reasons Couchbase can do the read/write faster (under millisecond) is because of its utilization of built in caching. Many databases, including others I worked on in the past, would tell you to get a caching tier in front of the database to not over-tax the database. However Couchbase Server is never deployed with a separate caching tier. It has memcached already built in for fast data access. We can also cache the parts of the document we need, sometimes only its metadata, sometimes with its data.
#4 Proxyless Efficient Client-Server Communication
Couchbase Server comes with a smart client that is able to cache the cluster topology and its distributions map. This means, clients already know the exact Couchbase Server node to talk to when they get the key value. There are no hops in communication. No middle man, no rerouting… This makes it efficient to communicate.
There are additional features that have indirect effect on Couchbase Server communication: Partial reads & updates to documents. If the workload here is modified to read and update a subset of the document, you could see results improvements from using the new API.
Deeper Dive into YCSB Workload A Results
Here is the the %95th latency and throughput overlaid graph.
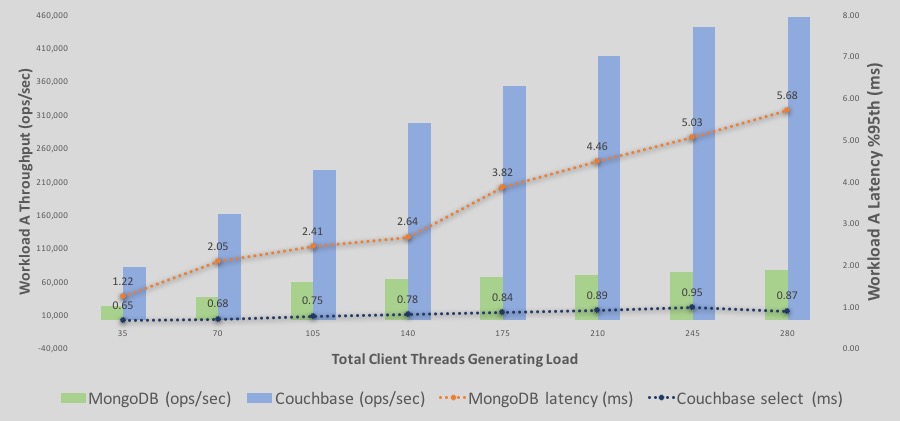
Here is a detailed breakdown of the Workload A read/write execution throughputs and latencies.
-The bars represent throughput – blue is Couchbase and green is MongoDB. Y Axis is the throughput numbers.
-The lines represent latency – blue is Couchbase and orange is MongoDB. Secondary Y Axis on the right, represent latency numbers with descending latency line represents worse or higher latency. In other words, secondary axis for latency is a descending axis.
A few observations;
–Throughput: Couchbase Server throughput continues to increase higher with more load. MongoDB throughput increases as well with a slower slope up to 140 clients. However at around >210 threads it levels off.
–Latency for Couchbase start off lower than MongoDB and continues that way. At the end, Couchbase still is in sub-millisecond latency range while MongoDB gets to >5ms latency for 95% latency.
I realize every benchmark can raise scepticism but I’d encourage all of you to try Couchbase Server and tell us what you see in your custom YCSB executions. If you are not seeing the results you expect, let us know