Learning SQL is easy; Implementing SQL, not so much.
Halloween has come and gone. But, the tricks of the Halloween problem is here to stay! This has to be solved by databases every day. SQL made the relational database easy, accessible, and successful. SQL may be easy to write, but its implementation hides a lot of complexity. From the days of System R to NoSQL systems, all of us implementing SQL and SQL inspired languages like N1QL, have to learn the rules, requirements to ensure the declarative query language continues its extraordinary effectiveness and correctness. One such problem is the Halloween Problem. I’ll describe the problem briefly here. I highly recommend reading its history in the IEEE Annals of the history of computing – second link in the references section below.
The Problem:
Consider a simple table and index:
|
1 2 |
CREATE TABLE t (empid int primary key, salary int); CREATE INDEX i1 ON t(salary); |
Imagine you’ve loaded some data and the index i1 looks like this. The index entry has the numeric value for the salary, followed by the rowid.

Now, in the spirit of giving more to people who have it, we want to increase the salary of all the employees who have (salary > 50).
UPDATE t SET salary = salary + 100 WHERE salary > 50;
Query Plan: Here’s the general plan for executing the query. In this case, we’ll assume the query planner will use the index i1 to qualify the rows) to update.
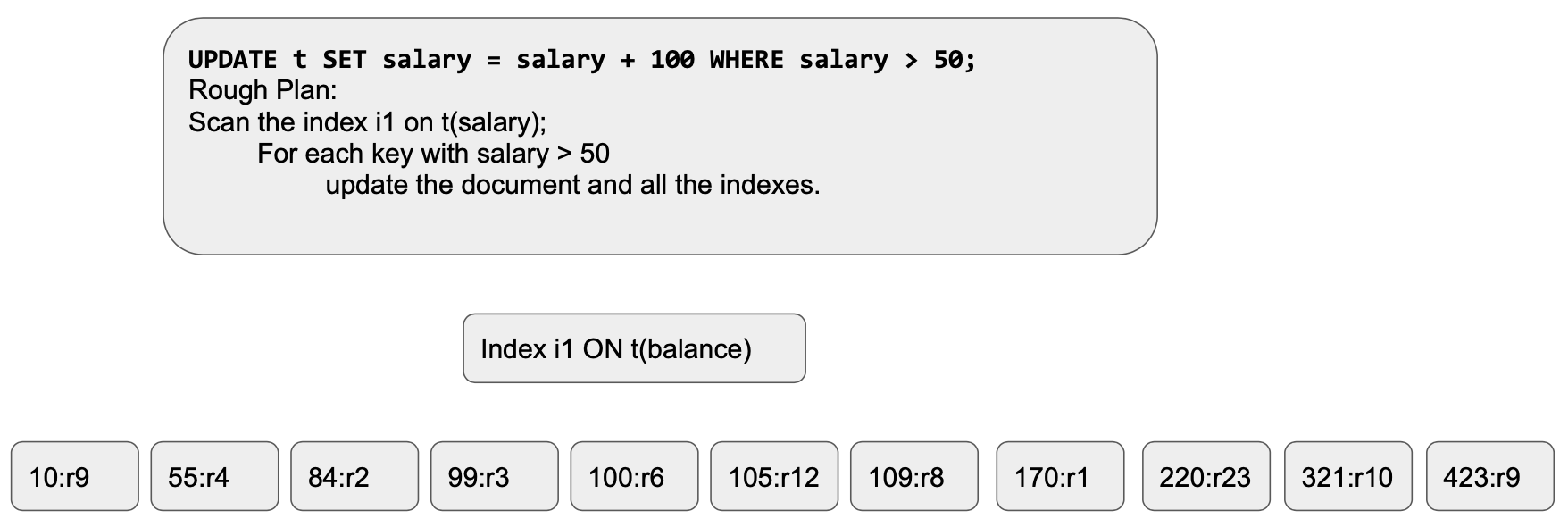
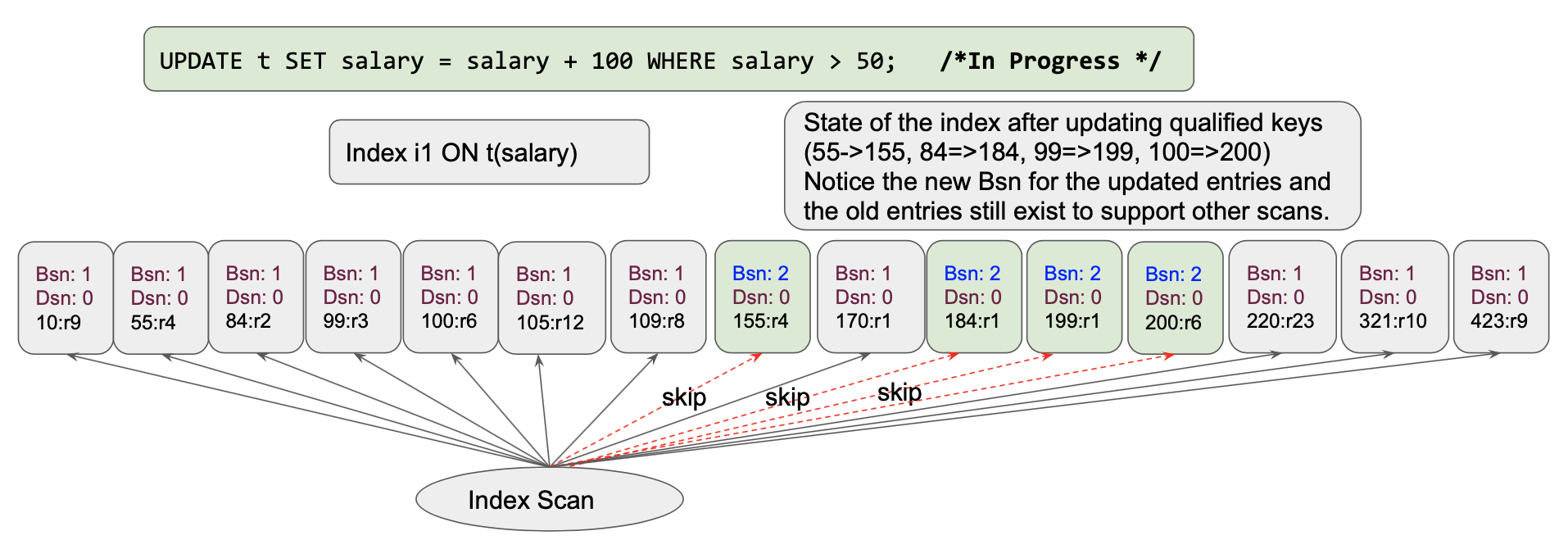
Query Execution: Once this starts to start executing, data rows will be updated and the index will get updated synchronously. the index will look something like this. Each qualified key get updated one by one [we’re scanning from left to right]. Here’s the state of the index after updating the initial four entries: (55->155, 84=>184, 99=>199, 100=>200)

Let’s see what happens after a couple of more changes.
As we move to the next item[155,r2] gets updated again to[255,r2]. This will repeat updating multiple keys multiple times. That violates the set manipulation rules where the intention is to take the set in the table t and update the qualified salaries by 100.

An additional manifestation of the Halloween problems.
INSERT INTO t SELECT * FROM t WHERE balance > 0;
Solution:
In traditional RDBMS (e.g. Informix), the solution is fairly straight forward. For each of the DML statements resulting in mutation, it keeps a sorted list of rowids updated within this statement. Before we update a row, we check to see if this row is already updated and skip it. For simple updates with limited range scans, this read overhead is hardly noticeable. For larger updates, the maintenance of a large list in memory can be an issue. Typically, the list is spilled out to disk once it gets sufficiently large.
Couchbase N1QL & GSI solution:
Couchbase is a distributed database with multiple services. The query service creates the execution plan and executes it. Here’s the overview of the solution.
Let’s look at the query when we have an index: CREATE INDEX i1 ON t(salary)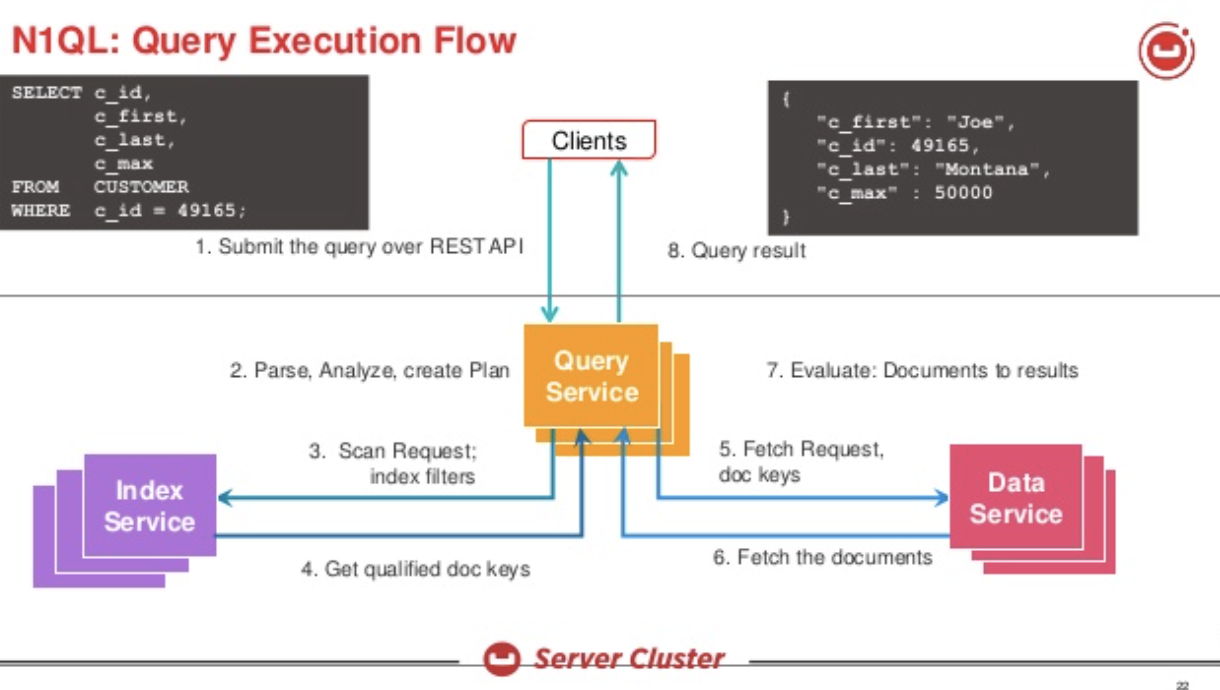 N1QL will create a plan like this: UPDATE statement, the plan will use the index scan to identify the documents to update, fetch the document, update it and write it back. It’s important to note that this update is done to documents synchronously. These changes will flow through DCP and index updates happen asynchronously. Even then, for larger updates, the scan of the index and updates can be going on while the updates are done to the index being scanned.
N1QL will create a plan like this: UPDATE statement, the plan will use the index scan to identify the documents to update, fetch the document, update it and write it back. It’s important to note that this update is done to documents synchronously. These changes will flow through DCP and index updates happen asynchronously. Even then, for larger updates, the scan of the index and updates can be going on while the updates are done to the index being scanned.
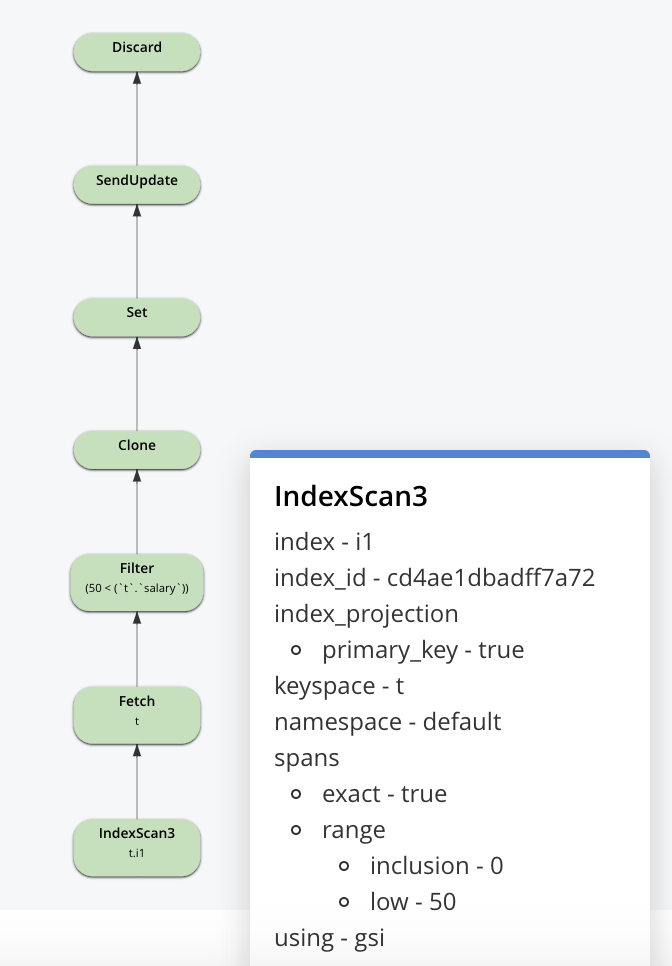
Now, let’s look at the index scan itself. Indexes can be built on Memory-Optimized Index (MOI) or Standard Secondary (using Plasma Storage Engine). Both of these have the concept of snapshot. Instead of updating the values in-place, we use MVCC to provide the required functionality and performance.
Here are a couple of things from the Nitro paper.
Immutable snapshots: Concurrent writers add or remove items into the skiplist. A snapshot of the current items can be created to provide a point-in-time view of the skiplist. This is useful for providing repeatable stable scans. Users can create and manage multiple snapshots. If an application requires atomicity for a batch of skiplist operations, it can apply a batch of operations and create a new snapshot. Changes would be invisible until a new snapshot is created.
Fast and low overhead snapshots: Readers of the skiplist use a snapshot handle to perform all lookup and range queries. An indexer application typically requires many snapshots to be created every second for servicing index queries. So the overhead of creating and maintaining a snapshot should be minimal for servicing the high rate of snapshot generation. Nitro snapshots are very cheap and is an O(1) operation.
To implement these, the index uses two things: BornSnapshot version and DeadSnapshot version. Let’s look at the state of the initial index.
 As the changes, change in the values simply add new nodes in the skiplist with updated values, bornSnapshot and deadSnapshot values.
As the changes, change in the values simply add new nodes in the skiplist with updated values, bornSnapshot and deadSnapshot values.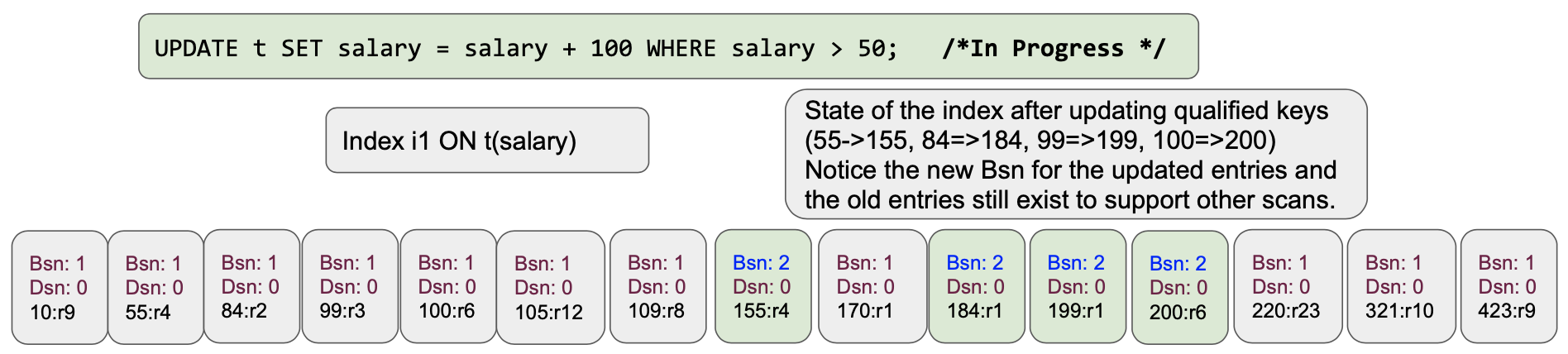
Using the bornSnapshot and deadSnapshot versions on the entries, index scanner (aka iterator) simply chooses the right entries to qualify index entries to read. That’s how it creates a snapshot and will not read the previously updated value in the same scan. This not only provides stable scans, but it also avoids the Halloween problem altogether! This also eliminates the need for updated-documentid list maintenance within the query service. Good engineering addressed the problem; great engineering avoids the problem altogether. :-)
Finally, a Halloween art by David Haikney, VP of Couchbase Customer Support! Watch the full video!
Happy Halloween to all @couchbase ! 🎃 pic.twitter.com/vqwW7sk3v6
— David Haikney (@dhaikney) October 31, 2020
References
- Halloween Problem
- A well-intentioned query and the Halloween Problem, Los Alamos National Laboratory, Anecdotes, IEEE Annals of the History of Computing
- Couchbase Global Secondary Index
- Nitro: A Fast, Scalable In-Memory Storage Engine for NoSQL Global Secondary Index