Couchbase is an enterprise data platform that enables performance at scale by combining a unique memory-first architecture with N1QL –which combines the agility of SQL with the power of JSON – amongst other built-in features as as Full-Text Search, Eventing, Analytics, and Global Secondary Indexing.
Enterprises that aim at providing a modern, reliable, and customized user experience across their technology offerings typically provision several clusters of Couchbase nodes. These different clusters offer the same performance at scale across different verticals, use cases, and mission-critical systems, in addition to simply having additional clusters that serve as disaster recovery/backup mechanisms. While Couchbase’s intuitive user interface allows seamless and easy management of the clusters and data buckets – by offering several one-click functionality for the various maintenance and administration tasks (i.e. rebalance, adding a node, failover, etc) – it is becoming more and more important to have a holistic view of the entire Couchbase ecosystem. This is especially true in cases where a given organization deploys multiple clusters for geo-locality of data or for supporting several microservices that span different segments, cost centers, or verticals.
Getting Started: Exporting Performance Metrics
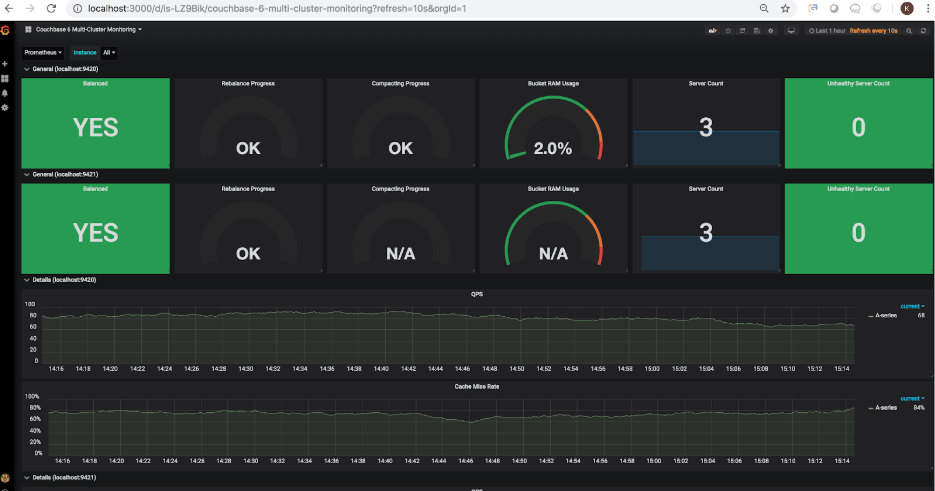
Using Couchbase Exporter (that was developed by our community partner TOTVS Labs) in combination with Prometheus, and Grafana, it is now possible to export the key performance metrics of one or more clusters and visualize their various performance aspects through a graphical dashboard. The following snapshot illustrates a sample monitoring dashboard for 2 Couchbase clusters:
Below are the detailed instructions on how to install and configure Couchbase Exporter, Prometheus, and Grafana:
First, let’s start with installing the required open source components needed to make all this work.
Couchbase Exporter
Install Couchbase Exporter either by cloning the GitHub repo https://github.com/totvslabs/couchbase-exporter and building from source, or by downloading the binary of the latest release from https://github.com/totvslabs/couchbase-exporter/releases – Once installed, a separate Couchbase Exporter process needs to be ran for each Couchbase Server cluster to be monitored using the following syntax:
|
1 |
./couchbase–exporter —couchbase.username Administrator —couchbase.password password —web.listen–address=“:9420” —couchbase.url=“https://52.38.xx.xx:8091” |
By default, Couchbase Exporter will run on port 9420 and will attempt to connect to the Couchbase Server running on https://localhost:8091, however, for most users, it is best to specify a free port number as well as the Couchbase Cluster in question explicitly (the IP address of any node of an existing cluster will suffice). For the purposes of this tutorial, I will be running 2 instances of Couchbase Exporter against 2 AWS EC2 Demo clusters located at the time of writing at 52.38.xx.xx and 52.40.xx.xx. The second instance of Couchbase Exporter is started using the following:
|
1 |
$ ./couchbase–exporter —couchbase.username Administrator —couchbase.password password —web.listen–address=“:9421” —couchbase.url=“https://52.40.xx.xx:8091” |
Here are the screenshots of running these 2 Couchbase Exporter instances. Note these instances are now running on https://localhost:9420 and https://localhost:9421, respectively. These 2 URLs will be used later on to configure Prometheus.


Prometheus
Install Prometheus with your installation method of choice following the steps outlined in https://prometheus.io/docs/prometheus/latest/installation/ – Once installed, you may now edit the prometheus.yml file that is available in the same directory as the Prometheus binary. This YAML file needs to be modified to specify the Couchbase Exporter targets that were configured in step 1. In this example, we will modify the scrape_configs section of the YAML file as follows:
|
1 2 3 4 5 6 7 8 9 |
scrape_configs: # The job name is added as a label `job=<job_name>` to any timeseries scraped from this config. – job_name: ‘couchbase’ # metrics_path defaults to ‘/metrics’ # scheme defaults to ‘http’. static_configs: – targets: [‘localhost:9420′, ‘localhost:9421’] |
Once the scrape_configs section is modified to point to the Couchbase Exporter instances, now we can start Prometheus as follows:
|
1 |
$. /prometheus —config.file=prometheus.yml |
Now Prometheus should be started and accessible via port 9090 (i.e. https://localhost:9090)
Grafana
Install Grafana with your installation method of choice following the steps outlined in https://docs.grafana.org/installation/ – Once installed, you should be able to start Grafana (i.e. $ sudo service grafana–server start ) and access it on port 3000 (i.e. https://localhost:3000) – Default username and password are admin/admin, however, it is highly recommended to set these credentials according to your organization’s security policy.
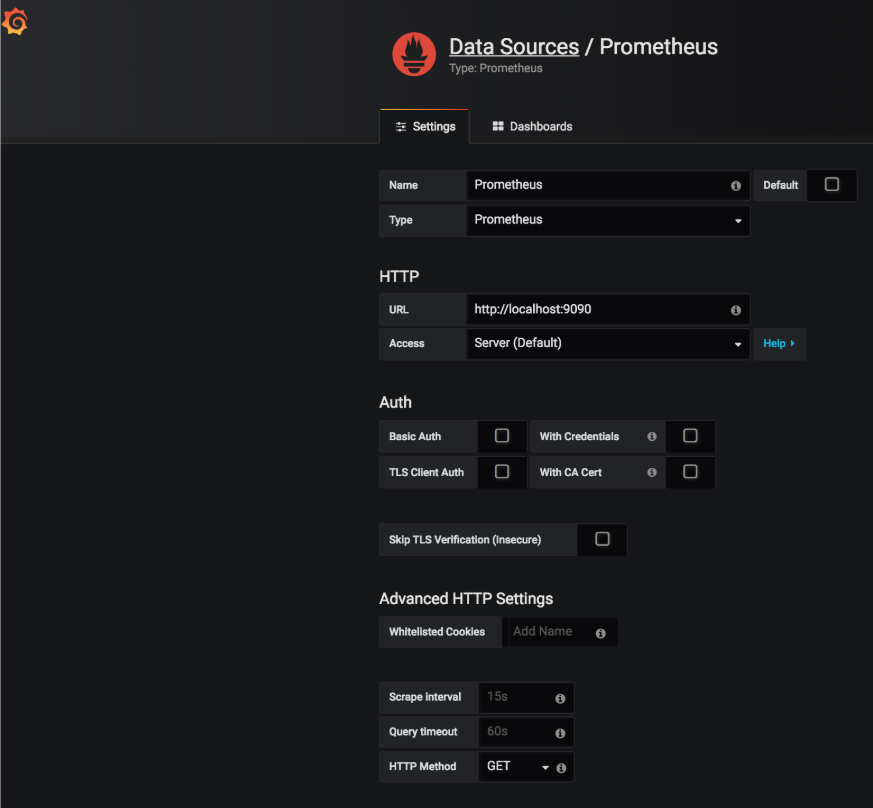
Now that Grafana has been installed and started, let’s add and configure the Prometheus data source as follows:
Visualizing the Performance Metrics:
Now that Couchbase Exporter, Prometheus, and Grafana have been properly installed and configured, we will now proceed to import a sample Grafana dashboard using this sample JSON. This is a sample dashboard for illustrative purposes only and does not constitute a recommendation on what metrics to monitor for your particular use case. Your organization is likely to need a custom dashboard with specific Couchbase metrics relevant to your individual use case and therefore this example does not necessarily fit that particular purpose.
Once the dashboard is imported, you should be able to load it in Grafana. The following screenshot depicts the state of the 2 clusters configured in step 1.
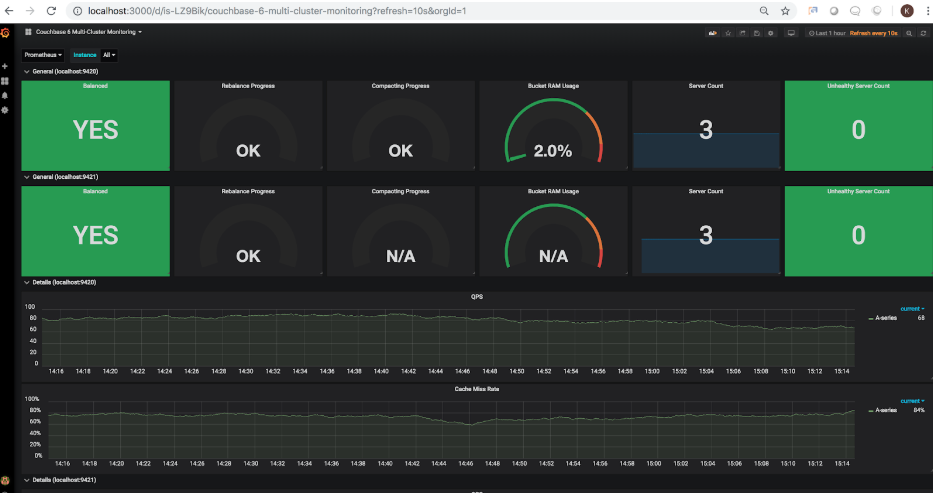
You may have noticed that the bucket RAM usage for the second cluster is showing N/A. This correctly reflects the fact that the second cluster does not have any buckets at the moment. Let’s go ahead and add sample buckets to that cluster. Once added, the dashboard is refreshed to show the updated bucket RAM usage at 15.5% (this percentage will vary based on the RAM allocated to the cluster):
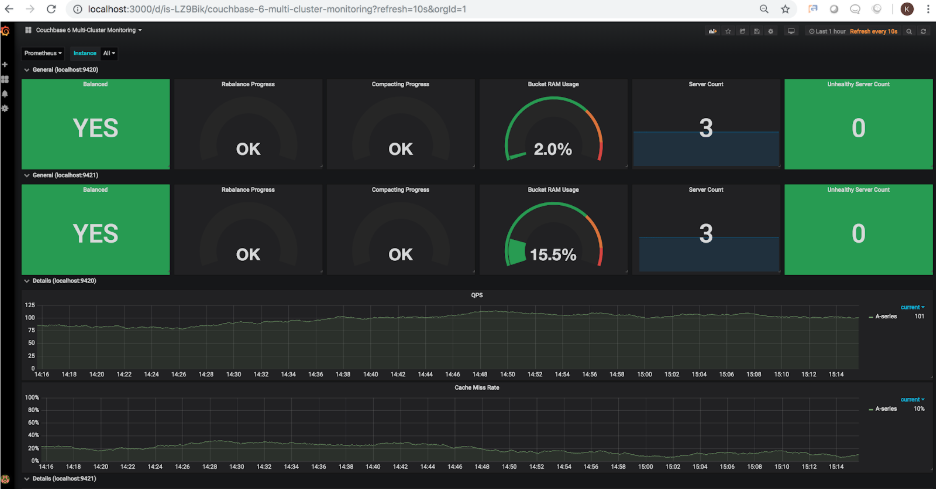
Each cluster was initially configured to have 3 nodes. Let’s go ahead and add a 4th node to the second cluster. Once a node is added, the refreshed dashboard will show the following:

Since the 4th node was added, and the cluster has not been rebalanced, the server count has been updated to show 4 nodes in total, however, the rebalance status is correctly showing the rebalance not being complete. Let’s go ahead and trigger a rebalance. Once the rebalance is triggered through he Couchbase UI, the refreshed dashboard will showing the following:
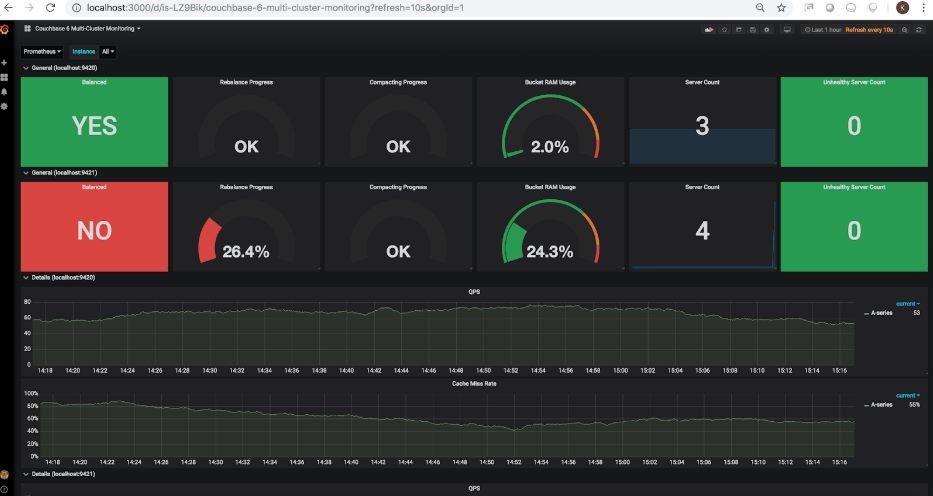
As you can see, the rebalance indicator is now showing 26.4% progress. Once the rebalance is complete, the refreshed dashboard will show the following:
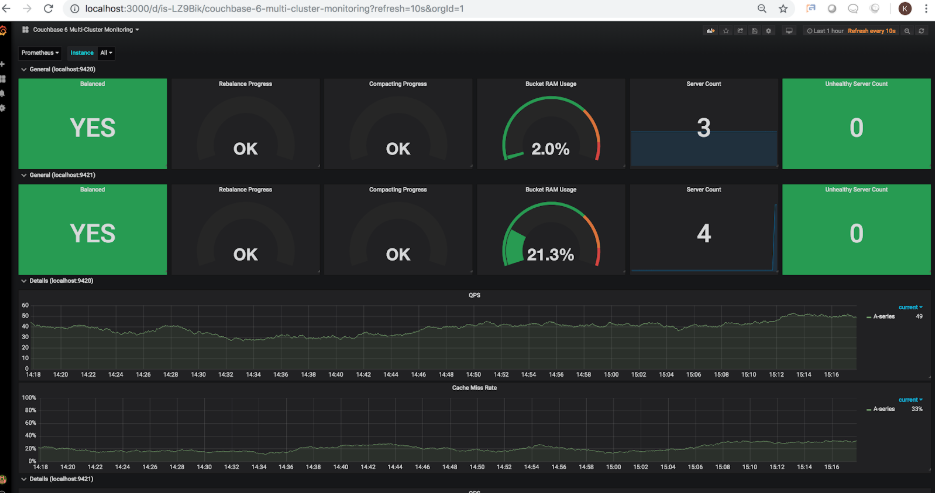
The rebalance is now complete, and you may notice now that the bucket RAM usage shows 21.3%, to reflect the additional node’s capacity being added to the cluster, therefore reducing the actual overall usage of the 3 samples buckets.
Recap:
In this blog, we have installed Prometheus, Grafana, and Couchbase Exporter in order to monitor multiple Couchbase clusters. The Grafana dashboard allows visually monitoring key metrics and performance indicators for Couchbase Server clusters in one central place. In addition, Prometheus allows configuration of alerting rules that would send notifications to a user or mailing list about certain conditions for when a given metric falls or exceeds a certain threshold.
Below are the resources used throughout this blog:
Author
4 Comments
-
Great article, thanks!
I also wrote an exporter for Couchbase that I think could be of interest to you. It scrapes all metrics from Couchbase API, even XDCR and I added Prometheus and Grafana sample configuration.
The exporter still needs some minor improvements but it is very much ready to use:
https://github.com/leansys-team/couchbase_exporterAnd the Docker version:
https://hub.docker.com/r/blakelead/couchbase-exporterPlease check it, I think it is worth your time (and mine, I’d love feedback :))
-
Great article to get started with monitoring with Prometheus. Thanks for sharing !!
This article did covered the integration part really well but missed out a lot on scalability, high availability, fail-back recovery, customizations and automation scope of this integration which are important aspect of creating monitoring tool solutions.
Which we have tried discussing all of them in the following undermentioned article.
Please, take a look. I hope it’s worth your time. Plus, would love the feedback on the developed solutions.
#automation #couchbase #prometheus #grafana #monitoring #alerting #scalability #opensourcedevelopment
-
Updated link for article & our analysis of this integration tool: https://hackernoon.com/dissecting-the-couchbase-monitoring-integration-with-prometheus-and-grafana-ge1v6263t
-
-
The article relay helps to get more details on what going on in side the cluster.
I have set this up on my cluster. We have 3 Node cluster
1 (Index) Node
2 (Data, Query and Search) Node.Which metrics should I check per Node and which metrics should be checked on whole cluster???
Leave a comment
You must be logged in to post a comment.