What are vision language models?
Vision language models are AI systems designed to understand and reason across both visual and textual data. Unlike traditional computer vision (CV) models that only analyze images, or large language models (LLMs) that only process text, VLMs connect these two modalities to form a shared understanding.
VLMs are typically trained on large datasets containing paired images and text, such as photos with captions or documents that mix visuals and language. Through this training, VLMs learn how visual features (e.g., objects, scenes, and spatial relationships) map to words and meaning. This allows the models to describe images, answer questions about them, and reason about visual content using language.
How vision language models work
Vision language models combine visual understanding and language comprehension into a single system. While architectures vary, most VLMs follow the same core workflow outlined below.
1. Image encoding and visual feature extraction
- Images are processed by a vision encoder, often a convolutional neural network (CNN) or a vision transformer (ViT).
- The encoder extracts meaningful visual features such as objects, shapes, textures, and spatial relationships.
- These features are converted into numerical representations that the model can reason over.
2. Text encoding and language understanding
- Text inputs are processed by a language encoder, typically based on transformer architectures.
- The encoder captures semantic meaning, context, and relationships between words.
- The output is a structured representation of language that aligns with visual concepts.
3. Cross-modal alignment between vision and language
- The model learns to map image and text representations into a shared embedding space.
- In this space, related images and text are positioned closer together, while unrelated pairs are pushed apart.
- This alignment enables tasks like image captioning, visual question answering (VQA), and image-text retrieval.
- Models such as CLIP are well known for learning strong image-text alignment at scale.
4. Training vs. inference in VLMs
- Training:
- The model is trained on large datasets of paired images and text (e.g., captions, descriptions, or documents).
- Objectives encourage the model to correctly associate images with relevant language.
- Inference:
- Once trained, the model applies what it’s learned to new inputs.
- It can interpret images, answer questions, generate descriptions, or retrieve relevant content without additional training.
Vision language models vs. traditional computer vision models vs. large language models
While all three model types fall under the broader AI umbrella, they’re designed for very different purposes. The key differences lie in what data they can process, how they reason, and what kinds of tasks they’re best suited for. Understanding these distinctions helps teams choose the right model for the right problem. Here’s a quick comparison outlining the key differences:
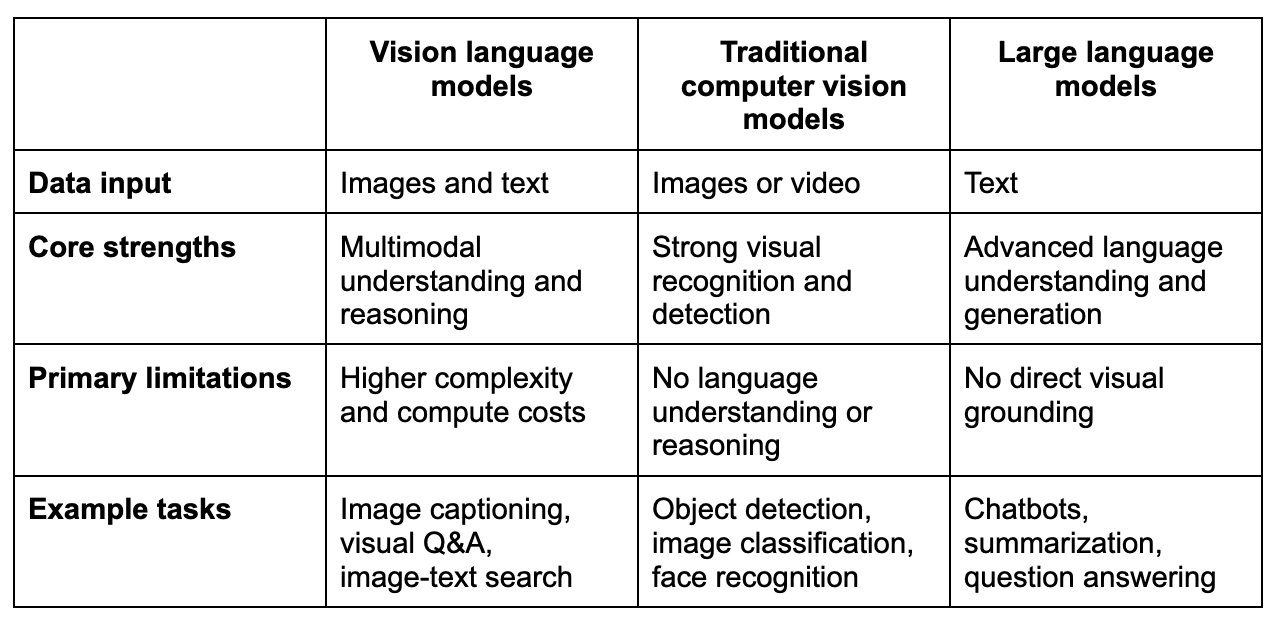
Key differences explained
- Traditional CV models focus exclusively on visual signals and are optimized for identifying what’s in an image, but not explaining it in natural language.
- LLMs excel at reasoning with text but lack awareness of visual context unless it’s described to them.
- VLMs bridge the gap between CV models and LLMs, enabling grounded reasoning across both image and text modalities.
Well-known VLMs like CLIP learn to align images and language, while multimodal versions of GPT-5 extend this capability to more general reasoning and interaction.
When to use a vision language model vs. a single-modal model
Use a vision language model when:
- The task requires understanding both images and text together
- Users need explanations, answers, or reasoning grounded in visual content
- Applications involve multimodal search, document understanding, or visual assistance
Use a traditional computer vision model when:
- The task is purely visual (e.g., detecting defects, counting objects)
- Speed, efficiency, or edge deployment is critical
- No language-based reasoning or explanation is required
Use a large language model when:
- The problem involves only text (e.g., summarization, content generation)
- Visual context is unnecessary or already encoded in text
- You need flexible natural language reasoning
Key capabilities and tasks
The ability to jointly understand visual content and natural language allows VLMs to interpret, reason, and interact with images in ways that are more flexible and human-like, such as:
Image captioning
VLMs can generate natural language descriptions of images by identifying objects, actions, and relationships within a scene. This capability is commonly used for accessibility tools, content moderation, and media management.
Visual question answering
Visual question answering allows users to ask questions about an image and receive relevant, context-aware answers. The model must understand both the visual content and the intent behind the question to respond accurately.
Image-text retrieval
VLMs support cross-modal search by matching images to text and vice versa. This enables use cases such as finding products based on descriptions or retrieving relevant images using natural language queries.
Multimodal reasoning
VLMs can reason across visual and textual inputs to draw conclusions, compare elements, or follow instructions grounded in images. This capability is critical for complex tasks like visual assistance and decision support.
Document and scene understanding
VLMs can interpret documents and real-world scenes that combine text and visuals, such as forms, diagrams, screenshots, or street images. This enables applications like document analysis, workflow automation, and environment-aware systems.
Use cases for vision language models
By combining modalities, VLMs enable richer interactions, better automation, and more accurate insights across many industries where understanding both visual content and language is essential. Common use cases include:
- Visual search and discovery: Enable users to search for products, images, or content using natural language descriptions instead of keywords.
- Customer support and troubleshooting: Interpret screenshots or photos submitted by users to provide faster, more accurate assistance.
- Document processing and analysis: Extract meaning from documents that combine text, tables, charts, and images, such as invoices, contracts, and reports.
- Accessibility tools: Generate image descriptions and answer visual questions to support users with visual impairments.
- Healthcare and medical imaging: Analyze medical images alongside clinical notes to support diagnosis, documentation, and research.
- Retail and e-commerce: Power visual product recommendations, image-based search, and automated catalog tagging.
- Autonomous systems and robotics: Help machines understand their environment and follow language-based instructions grounded in visual context.
- Content moderation and safety: Identify and interpret visual content alongside text to enforce policies more accurately.
Training data and architectures
Vision language models rely on large-scale multimodal data and specialized architectures to learn the relationships between images and language. The quality of the data and the design of the model architecture play a critical role in how well a VLM performs across tasks.
Training data for vision language models
Vision language models require diverse training data to capture both broad multimodal knowledge and task-specific or domain-specific relationships between images and text. This data includes:
- Image-text pairs: The most common training data format, where images are paired with captions, descriptions, or surrounding text
- Web-scale datasets: Large collections of publicly available images and text used to learn broad visual and linguistic concepts
- Annotated datasets: Carefully labeled data for tasks like visual question answering, document understanding, or scene interpretation
- Domain-specific data: Specialized datasets (e.g., medical images with clinical notes or product images with metadata) used to improve performance in specific industries
Common VLM architectures
Several architectural paradigms have emerged for vision language models, each balancing efficiency, flexibility, and reasoning capability in different ways:
- Dual-encoder models:
- Use separate encoders for images and text
- Learn to align visual and language representations in a shared embedding space
- Well suited for retrieval tasks and scalable training (e.g., CLIP)
- Encoder-decoder models:
- Encode visual inputs and generate text outputs directly
- Commonly used for image captioning and visual question answering (e.g., BLIP)
- Unified multimodal models:
- Process images and text together within a single transformer-based architecture
- Enable advanced multimodal reasoning and flexible task handling
Role of transformers and attention mechanisms
- Transformer architectures allow models to attend to relevant parts of both images and text.
- Attention mechanisms help the model understand relationships between visual regions and words or phrases.
- This design is key to enabling complex reasoning across modalities.
Limitations of vision language models
While vision language models unlock powerful multimodal capabilities, they also come with important limitations that teams should understand before deploying them in real-world applications.
- Data quality and bias: VLMs are trained on large image-text datasets that may contain noise, inaccuracies, or societal biases, which can affect model outputs and fairness.
- High computational cost: Training and running VLMs requires significant compute resources, making them expensive to build, deploy, and scale.
- Limited visual grounding: Models may generate confident but incorrect responses if visual details are subtle, ambiguous, or outside their training distribution.
- Generalization challenges: Performance can drop when models encounter unfamiliar domains, image styles, or real-world scenarios that aren’t well represented in training data.
- Interpretability issues: It’s often difficult to understand why a VLM produced a specific output, which can be problematic in regulated or high-stakes settings.
- Latency constraints: The complexity of multimodal processing can introduce delays, limiting suitability for real-time or edge applications.
- Ethical and privacy concerns: Using images that include people, private spaces, or sensitive information raises privacy, consent, and misuse risks.
Recognizing these limitations is essential for applying vision language models responsibly and for selecting appropriate safeguards, evaluation methods, and use cases.
Evaluation and performance metrics
Evaluating vision language models requires measuring both visual understanding and language performance, often across multiple tasks. Because many VLM outputs are open-ended, effective evaluation typically combines automated metrics with human judgment.
Task-specific metrics
Depending on the specific task formulation, standard predictive performance metrics include:
- Accuracy: Commonly used for classification-style tasks such as visual question answering with fixed answer sets
- Precision, recall, and F1 score: Measure how well the model identifies relevant outputs, especially in retrieval or detection tasks
- Top-k accuracy: Evaluates whether the correct answer appears among the model’s top predictions
Generation quality metrics
For tasks where the model generates free-form text, specialized metrics include:
- BLEU: Measures overlap between generated text and reference captions or answers, often used for image captioning and translation tasks
- ROUGE: Focuses on recall and is commonly applied to summarization-style outputs
- CIDEr and METEOR: Designed specifically for evaluating image captions by comparing them to multiple human references
Retrieval and alignment metrics
When the goal is to evaluate how well models associate images and text, metrics include:
- Recall@K: Assesses how often the correct image or text is retrieved within the top K results
- Mean reciprocal rank (MRR): Evaluates ranking quality in image-text retrieval tasks
- Cross-modal similarity scores: Measure how well image and text embeddings align in shared representation spaces
Human evaluation
Because automated metrics can lack nuance, human judgment is often incorporated to provide a more holistic assessment of model behavior.
- Human reviewers assess qualities that automated metrics struggle to capture, such as correctness, relevance, reasoning, and fluency.
- Human evaluation is especially important for multimodal reasoning and open-ended generation tasks.
Operational performance metrics
Beyond output quality, practical deployment also requires evaluating how efficiently models perform under real-world system constraints, such as:
- Latency: Time required to process image-text inputs and generate outputs
- Throughput: Number of requests handled over a given time period
- Resource usage: Memory and compute requirements during inference
A balanced evaluation strategy ensures that vision language models are accurate, reliable, and practical to deploy.
Future trends in vision language models
Vision language models are continuing to evolve as research pushes beyond basic image-text alignment toward deeper understanding, reasoning, and real-world interaction. Several key trends are shaping the next generation of VLM capabilities. Some of these include:
- Stronger multimodal reasoning: Models will move beyond merely describing images to performing step-by-step reasoning grounded in visual evidence, enabling more reliable decision-making and analysis.
- Unified multimodal architectures: Future VLMs are likely to handle images, text, video, audio, and other modalities within a single cohesive model rather than in separate components.
- Better grounding and reliability: Research is increasingly focused on reducing hallucinations and improving how models tie their outputs directly to visual inputs.
- More efficient training and inference: Advances in model compression, distillation, and hardware optimization will lower costs and make VLMs more practical at scale and on edge devices.
- Domain-specialized VLMs: Expect more models trained or fine-tuned for specific industries such as healthcare, finance, manufacturing, and scientific research.
- Integration with agents and tools: VLMs will increasingly be combined with autonomous agents, allowing systems to perceive environments, plan actions, and interact with the world using both vision and language.
- Greater emphasis on ethics and governance: As adoption grows, transparency, privacy protection, and bias mitigation will become central to VLM development and deployment.
Together, these trends point toward vision language models becoming a foundational layer for multimodal AI systems that can see, understand, reason, and act more like humans in complex environments.
Key takeaways and related resources
Vision language models represent a major step forward in AI by unifying visual understanding and natural language reasoning within a single system. By learning from paired image-text data and aligning vision and language in shared representations, VLMs enable interactions that are more flexible, context aware, and human-like across a wide range of applications.
Key takeaways
- Vision language models are designed to jointly understand images and text, unlike traditional computer vision models or large language models that operate on a single modality.
- VLMs learn the relationships between visual features and language by training on large datasets of paired images and text.
- Most vision language models rely on separate vision and language encoders that are aligned in a shared representation space.
- Models such as CLIP demonstrate that large-scale image-text alignment enables strong multimodal retrieval and reasoning.
- Vision language models are especially effective for tasks that require multimodal understanding, including image captioning, visual question answering, and document or scene interpretation.
- Despite their capabilities, VLMs face significant limitations in data quality, bias, computational cost, generalization, and interpretability.
- Continued advances in architectures, efficiency, and grounding are positioning vision language models as a foundational component of future multimodal AI systems.
To learn more about topics related to AI advancements, you can visit the related resources below:
Related resources
- A Complete Guide to the AI App Development Process – Blog
- Build Your First Open Source AI Agent With Couchbase – Blog
- App Development Costs (A Breakdown) – Blog
- A Guide to AI Data Management – Blog
- An Overview of Unstructured Data Analysis – Blog
FAQs
How are vision language models trained and evaluated? Vision language models are trained on large-scale paired image-text datasets, and are evaluated on benchmark tasks such as image-text retrieval, visual question answering, captioning, and multimodal reasoning.
How do vision language models understand the relationship between images and text? They learn to map visual and textual inputs into a shared embedding space where related images and text are positioned close together, enabling alignment and reasoning across modalities.
How do vision language models handle multimodal inputs? VLMs process images and text through separate encoders, then combine their representations using attention mechanisms or shared architectures to jointly reason over both inputs.
Are vision language models suitable for real-time or edge applications? They can be used in real time for some applications, but high computational costs and latency often require optimization, smaller models, or cloud-based deployment rather than edge devices.
What ethical or privacy concerns are associated with vision language models? Key concerns include bias inherited from training data, misuse of images containing people or sensitive information, and challenges related to consent, surveillance, and data privacy.
How can businesses get started with vision language models? Businesses can begin by experimenting with pretrained models or APIs, identifying high-impact multimodal use cases, and gradually fine-tuning or integrating VLMs based on their data, infrastructure, and compliance needs.