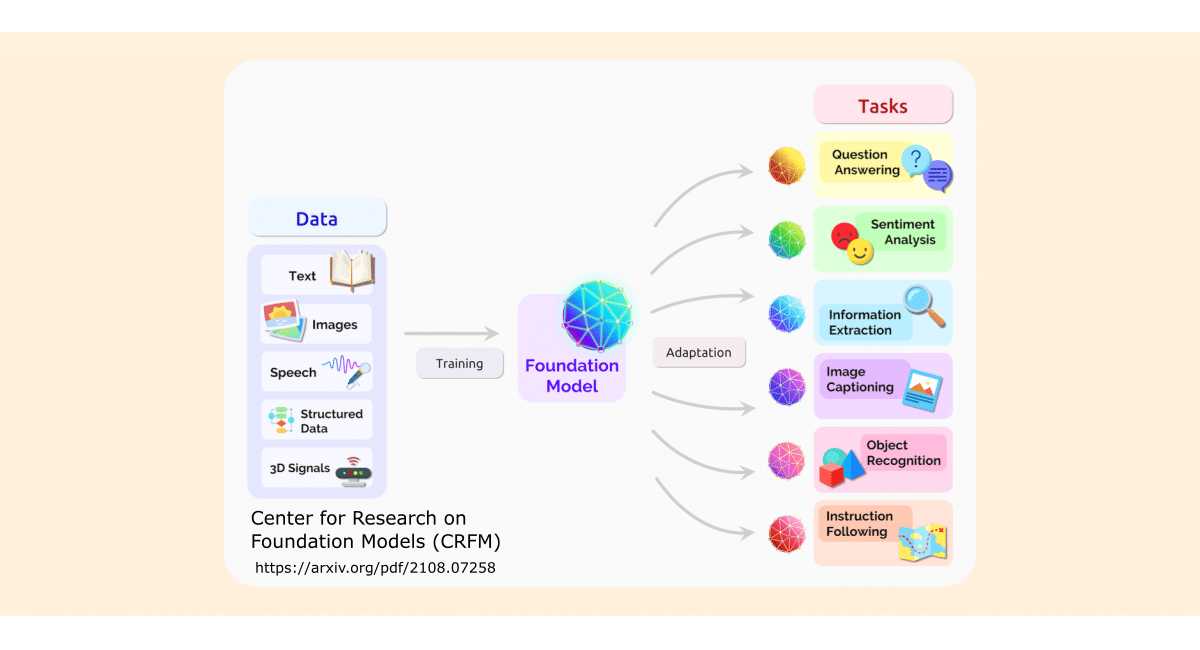
What is a Foundation Model?
A foundation model is a powerful type of artificial intelligence (AI) trained on massive amounts of general data, allowing it to tackle a broad range of tasks. Foundation models, such as OpenAI’s GPT (Generative Pre-trained Transformer) series or Google’s BERT (Bidirectional Encoder Representations from Transformers), are designed to capture general language patterns and knowledge from diverse sources on the internet. These models can then be fine-tuned on smaller, task-specific datasets to perform tasks like text classification, summarization, translation, question answering, and more. This fine-tuning makes developing new AI applications faster and inexpensive.
To learn more about foundation models, their inner workings, training methodologies, and real-world applications, continue reading.
How Do Foundation Models Work?
Foundation models, such as those based on the transformer architecture like GPT or BERT, function through extensive pre-training on diverse datasets followed by fine-tuning for specific tasks. Here’s a breakdown of how these models work:
Pre-Training
- Data Collection: Foundation models are trained on large and diverse datasets from books, websites, articles, and other text sources. This helps the model learn various language patterns, styles, and information.
- Learning Objectives: During pre-training, the models are typically trained to predict parts of text given other parts of the text. For example, in the case of GPT, the model predicts the next word in a sentence given the previous words (a process known as autoregressive training). On the other hand, BERT uses a masked language model approach where some words in the input are randomly masked, and the model learns to predict these masked words based on the context provided by the other unmasked words.
- Model Architecture: The transformer architecture used in these models relies heavily on self-attention mechanisms. These allow the model to weigh the importance of different words in a sentence or document regardless of their position, enabling it to effectively understand context and relationships between words.
Fine-Tuning
- Task-Specific Data: After pre-training, the model can be fine-tuned with smaller, task-specific datasets. For example, for a sentiment analysis task, the model would be fine-tuned on a dataset of text samples labeled with sentiments.
- Adjusting the Model: During fine-tuning, the entire model or parts of it are slightly adjusted to perform better on the specific task. This process involves training the model further, but now with the task-specific objective in mind (like classifying sentiments or answering questions).
- Specialization: This step tailors the general abilities acquired during pre-training to particular requirements and nuances of a specific task or domain, improving performance considerably compared to training a model from scratch on the same task.
Deployment
- Deployment for Use: Once fine-tuned, foundation models can be deployed in various applications, ranging from virtual assistants and chatbots to tools for automatic translation, content generation, and more.
Imagine a foundation model like a master chef. It devours enormous quantities of ingredients (data) and learns how they interact (relationships). Then, based on this knowledge, it can whip up various dishes (perform tasks) – from crafting a delicious soup (writing text) to a beautiful cake (generating an image).
Types and Examples of Foundation Models
Foundation models vary widely in architecture, training objectives, and applications, each tailored to leverage different aspects of learning and interaction with data. Below is a detailed exploration of the various types of foundation models:
Autoregressive Models
Autoregressive models like the GPT series (GPT-2, GPT-3, GPT-4) and XLNet use a training approach where the model predicts the next word in a sequence given all previous words. This training method enables these models to generate coherent and contextually relevant text, which is particularly useful for creative writing, chatbots, and personalized customer service interactions.
Autoencoding Models
Autoencoding models, including BERT and RoBERTa, are trained to understand and reconstruct their inputs by first corrupting them, typically using a technique known as masked language modeling, where random tokens are hidden from the model during training. The model then learns to predict the missing words based only on their context. This ability makes them highly effective for understanding language structure and applications like text classification, entity recognition, and question answering.
Encoder-Decoder Models
Encoder-decoder models such as T5 (Text-to-Text Transfer Transformer) and BART are versatile tools capable of transforming input text into output text. These models are particularly adept at handling complex tasks such as summarization, translation, and text modification by learning to encode an input sequence into a latent space and then decode it into an output sequence. Their training often involves various text-to-text conversion tasks, providing broad applicability across many domains.
Multimodal Models
Multimodal models like CLIP (from OpenAI) and DALL-E are designed to process and generate content that spans different data types, such as text and images. By understanding and generating multimodal content, these models become crucial for tasks involving interpreting the relationship between images and textual descriptions, such as in image captioning, text-based image retrieval, or creating images from descriptions.
Retrieval-Augmented Models
Retrieval-augmented models, such as RETRO (Retrieval-Enhanced Transformer), enhance the capabilities of traditional language models by integrating external knowledge retrieval processes. This approach allows the model to fetch relevant information from a large database or corpus during the prediction phase, leading to more informed and accurate outputs. This is particularly beneficial in applications requiring detailed factual accuracy and depth, such as question answering and content verification.
Sequence-to-Sequence Models
Sequence-to-sequence (seq2seq) models like Google’s transformer and Facebook’s BART handle tasks that require transforming an input sequence into a closely related output sequence. These models are foundational in machine translation and document summarization, where the entire content or its meaning must be accurately captured and conveyed in another form.
Each type of foundation model is uniquely suited to specific tasks, thanks to its distinct training and operational design. In the next section, let’s explore some use cases to elaborate on the functionality of foundation models.
Use Cases for Foundation Models
Foundation models are changing different industries with their adaptability and capacity to learn from large datasets. Below are a few interesting examples:
- Natural Language Processing (NLP): Foundation models are the backbone of many NLP applications. They power machine translation, enabling seamless communication across languages. They can also be used for tasks like sentiment analysis (understanding the emotional tone of text) or chatbot development for more natural human-computer interaction.
- Content Creation: Foundation models can generate different creative text formats, from poems and scripts to marketing copy, aiding content creators and marketers.
- Image and Video Analysis: In the visual domain, foundation models excel at image and video analysis. They can be used for tasks like object detection in security cameras, medical image analysis to assist doctors, or generating realistic special effects in movies.
- Scientific Discovery: These models can accelerate scientific research by analyzing massive datasets to identify patterns and relationships that traditional methods might miss. This ability can aid drug discovery, materials science, or climate change research.
- Automation: Foundation models can automate repetitive tasks, such as document summarization or data entry, freeing up time for more complex work.
These are just a few examples of use cases for foundation models, and the potential applications are constantly expanding as researchers explore new possibilities. They hold immense promise for transforming various industries and our daily lives.
How to Train Foundation Models
Training foundation models is a complex endeavor requiring significant computational resources and expertise. Here’s a simplified breakdown of the key steps:
- Data Collection and Preparation: The foundation is built on data. Enormous amounts of unlabeled data relevant to the desired tasks are collected. This data could be text for large language models (LLM), images for computer vision models, or a combination for multimodal models. Cleaning and preprocessing the data to ensure its quality and consistency is crucial.
- Model Architecture and Selection: The type of foundation model you choose depends on the data and tasks. Once selected, the model architecture is fine-tuned to handle the massive datasets effectively.
- Self-Supervised Learning: This is where the magic happens. Unlike supervised learning with labeled data, foundation models leverage self-supervised learning techniques. The model itself creates tasks and labels from the unlabeled data. This involves tasks like predicting the next word in a sequence for text data or identifying missing parts of an image.
- Training and Optimization: The model is trained on the prepared data using powerful computing resources like GPUs or TPUs. Depending on the model size and dataset complexity, this training process can take days or even weeks. Techniques like gradient descent are used to optimize the model’s performance.
- Evaluation and Refinement: After training, the model’s performance is evaluated on benchmark datasets or specific tasks. If the results aren’t ideal, the model might be further refined by adjusting hyperparameters or even going back to the data preparation stage for quality improvement.
It’s important to note that training foundation models is an ongoing process. Researchers are constantly exploring new techniques for data handling, model architectures, and self-supervised learning tasks to improve model performance and maturity.
Foundation Model Benefits
Foundation models offer significant benefits, contributing to widespread adoption and use across various domains. Here’s a closer look at some key advantages:
- Versatility and Adaptability: Unlike traditional, narrowly focused AI models, foundation models are versatile. They can be fine-tuned for a wide range of tasks within their domain (text, image, etc.) or even across domains for multimodal models. This flexibility saves time and resources compared to building new models from scratch for each specific task.
- Efficiency and Cost-Effectiveness: Pre-trained foundation models provide developers with a solid starting point. Fine-tuning them for specific tasks is often faster and less computationally expensive than training entirely new models from scratch. This efficiency translates to cost savings and faster development cycles.
- Improved Performance: Foundation models, due to their massive training on large amounts of datasets, often outperform traditional models on various tasks. They can achieve higher accuracy in machine translation, image recognition, or text summarization tasks.
- Democratization of AI: The availability of pre-trained foundation models lowers the barrier to entry for AI development. Even smaller companies or researchers without access to massive computational resources can leverage these models to create innovative AI applications.
- Acceleration of Scientific Discovery: Foundation models can analyze massive scientific datasets, uncovering hidden patterns and relationships that traditional methods might miss. This ability can significantly accelerate scientific progress in areas like drug discovery, materials science, or climate change research.
Foundation Model Challenges
Foundation models, despite their remarkable capabilities, come with their own set of challenges that researchers are actively working to address. Here are some key areas of concern:
- Data Bias and Fairness: Foundation models inherit biases present in the data they’re trained on. This can lead to discriminatory or unfair outputs. Mitigating bias requires careful data selection, curation, and development of fairer training algorithms.
- Explainability and Interpretability: Understanding how foundation models arrive at their outputs can be difficult. This lack of transparency makes identifying and addressing potential errors or biases challenging. Research is ongoing to develop methods for making these models more interpretable.
- Computational Resources: Training and running foundation models requires significant computational power and resources like GPUs or TPUs. This can limit accessibility for smaller companies or researchers without access to such infrastructure.
- Security and Privacy Concerns: The vast amount of data used to train foundation models raises security and privacy concerns. Malicious actors could exploit vulnerabilities in the training data or the models themselves. Ensuring robust security measures and responsible data handling practices are crucial.
- Environmental Impact: Training these models can consume a significant amount of energy. Developing more energy-efficient training methods and using renewable energy sources are important considerations for the sustainable deployment of foundation models.
Key Takeaways
Foundation models represent a significant leap forward in AI capabilities. Their versatility, efficiency, and ability to learn from huge amounts of data are paving the way for a new generation of intelligent applications that will transform various industries and our daily lives.
To keep learning more about topics related to artificial intelligence (AI), explore the resources below:
- A Guide to Generative AI Development
- How Generative AI Works with Couchbase
- Can Developers Reduce Software TCO with AI?
- AI Cloud Services, Capella iQ, and Vector Search
- A Guide to Vector Search
- What is Vector Similarity Search?
- What are Vector Embeddings?
- Couchbase Customers are Using AI and ML to Fight Financial Fraud
- Adaptive Applications
Leave a comment
You must be logged in to post a comment.