If you’re a developer working with Couchbase or Capella, you’ll want to know about Capella DataStudio. It’s a free, community-supported tool with a slick, single-pane-of-glass UI for managing Capella Operational, Capella Columnar, and Couchbase Server Clusters. Not only does it boost developer productivity, but it also makes your experience a whole lot smoother (and cooler).
Now, it comes with a brand new feature: Synthetic Data Generator.
Capella DataStudio’s Synthetic Data Generator is designed to empower developers with a seamless, no-code way to create realistic and meaningful data for their projects. Whether you’re testing applications, training machine learning models, or simulating large-scale systems, this feature provides unparalleled flexibility and power.
What is Synthetic Data?
Synthetic data is not just “fake” data; it’s designed to mimic the properties, distributions, and relationships of real-world data. While fake data might generate random values without context, synthetic data aims to:
-
- Maintain logical relationships between fields (e.g., city and state are consistent)
- Follow realistic distributions, such as generating values that adhere to normal or weighted distributions
- Be statistically relevant for testing, analysis, and simulation
- This makes synthetic data incredibly useful in scenarios where real data is unavailable, sensitive, or insufficient
Read on to dig into synthetic data generation or watch this video to see it in action.
Key features of Capella DataStudio’s Synthetic Data Generator
Realistic, correlated data
Our generator ensures data relationships are meaningful. For example, addresses include matched city, state, zip code, latitude, and longitude values. Names and demographics are logically consistent.
Built-in typesets, fully configurable
Choose from a wide array of built-in typesets to jumpstart your data generation. Each type can be customized to suit your specific needs, whether it’s names, locations, dates, or numeric fields.
Extendible: bring your own typesets
Got your own datasets or specific requirements? Import custom typesets to extend the generator’s capabilities and create tailored data that fits your unique use case.
Primary Key / Foreign Key relationships
Model complex datasets with ease by defining relationships between fields. Foreign keys can reference primary key data, enabling realistic relational data structures.
Expression Handling with Powerful Functions
Leverage built-in functions to create complex expressions without writing a single line of code. Combine and manipulate fields dynamically for ultimate control over your data.
No restrictions on data size
Generate data at any scale, from a few rows for small tests to millions of documents for large-scale simulations. There are no limits to what you can create.
Seamless integration with Capella Operational and Couchbase Server
Take your synthetic data further by importing it directly into Capella Operational or Couchbase Server. This ensures a streamlined workflow from generation to deployment.
Why choose Capella DataStudio for synthetic data generation?
With its intuitive UI and robust feature set, Capella DataStudio’s Synthetic Data Generator is the ultimate tool for creating high-quality, meaningful datasets. Whether you’re a developer, data scientist, or tester, this feature will save time, reduce complexity, and enhance your projects with realistic data. Explore its endless possibilities and redefine your data creation experience.
Synthetic data generation
Let’s look at how the Synthetic Data Generator works.
Schema builder
The schema is built Field by Field, one row at a time. Each row has a minimum of two attributes:
-
- The field name
- The Data Type of the Field – this could come from the core or user typeset
Depending on the Data Type, more attributes may be exposed:
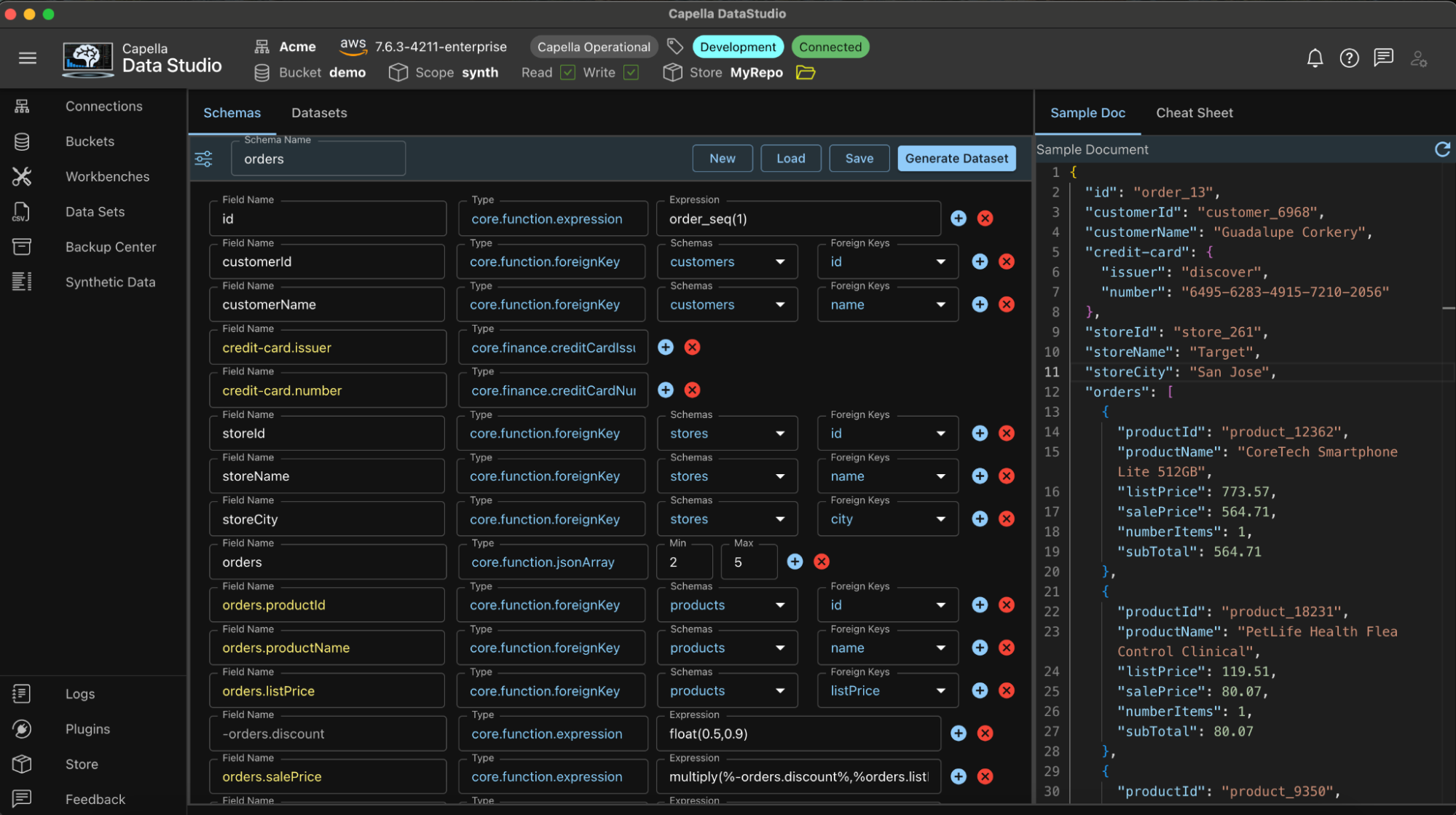
Example of the orders schema
Field name
-
- Field names can be any JSON compliant field name
- Nested JSON objects are specified by dotted format
- Deeply nested JSON supported
- Field names with a double dash prefix will be treated as a Primary Key
- When Generating Datasets, these keys will also be exported and will be saved as localStore/SyntheticData/DataSets/schemaName.pk file
- Primary Keys can be specified only in fields in root document
- JSON Objects, Nested Fields, and Hidden Fields cannot be Primary Keys
- Field names with a single dash prefix will be treated as a Hidden Field
- Hidden fields are used as temporary storage used in field reference
- Hidden fields cannot be Primary Key
- Hidden fields will not appear in JSON document
- JSON Objects cannot be hidden
- Nested fields can be hidden
Data type
The data type is selected from a dialog box:

Picture shows both the core typesets and a user supplied typeset (acme.pizzas)
Core typesets
Provided by Capella DataStudio:

User typesets
Provided by you to extend the functionality of the Data Generator. You need to provide two files:
-
- A CSV file with data
- A manifest file describing the Typeset
User typeset process
When a document is generated with user typesets, the following happens:
-
- One random row is read from the file
- The row is cached in a row-cache
- The fields are then read from this row-cache
- Once any field is read, that field is nulled in the row-cache
- If the field is null, the entire row-cache is invalidated and a new random row is read
- The fields are read from the row cache and for a given document, the data is correlated
- Each document starts with a new row-cache
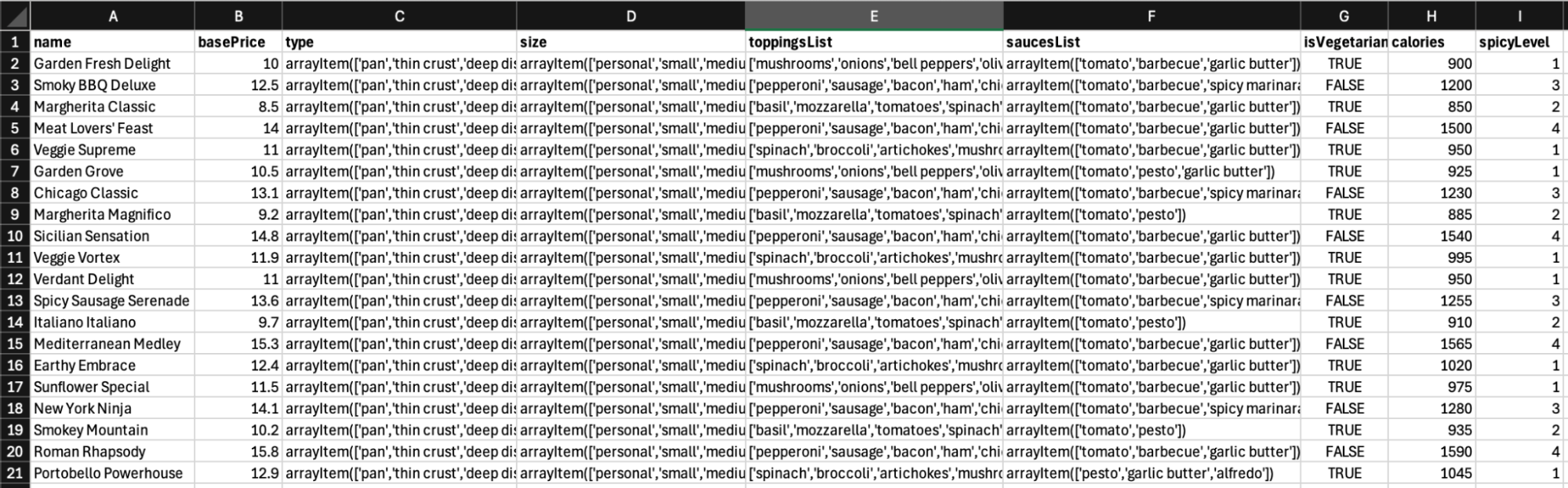
Example of pizzas typeset

Core function
There are three special data type:
-
- expression
- foreignKey
- jsonArray
1. core.function.expression
Expressions are a powerful way of customizing the schema:
-
- Expressions are just strings
- They can have embedded references (enclosed in %%) and functions
Document and expression architecture
Let’s see how the document is built:
-
- The document is built, top down, row by row.
- We always have a partial document at every row stage.
- First, the expression is a string
- It goes to an Expression Evaluator
- The partial document, with its fields and values is supplied to the evaluator.
- This means, the previous fields and their evaluated values are now available.
- The partial document, with its fields and values is supplied to the evaluator.
- The string is then examined for references
- References are field names, previously used, and their values, from the partial document.
- References are replaced by the values
- This means that references can also be inside of functions
- The string is then examined for functions
- The functions are then executed and their values are replaced in the partial document.
- The Evaluator finally returns back the output.
- The document is built, top down, row by row.
2. core.function.foreignKey
Foreign keys and data correlation
When working with relational data, maintaining referential integrity through foreign keys is crucial. Here’s how our synthetic data generator handles foreign key relationships:
How foreign keys work
First, you’ll need to generate your primary dataset. Let’s say you have a schema for Departments that generates a CSV file containing department IDs and names. These department IDs serve as primary keys in the Departments dataset.
When you create another schema, say for Employees, you can specify fields that reference these existing primary keys. The schema builder provides two drop-down menus:
-
- A dropdown to select the source dataset (e.g., “Departments”)
- A dropdown to select which primary key field to reference (e.g., “id”)
Data generation process
When generating data with foreign key references, the system:
-
- Randomly selects a row from the source dataset
- Reads the primary key value(s) from that row
- Uses these values in the new dataset being generated
Maintaining data correlation
An important feature is how we handle multiple foreign key references. If your schema references multiple columns from the same source dataset, the values are pulled from the same row to maintain logical correlation.
For example, if your Employee schema references both department_id and department_location from the Departments dataset, both values will come from the same department record. This ensures that the synthetic data maintains realistic relationships between related fields.
This approach helps create more realistic synthetic datasets by preserving the referential integrity and logical relationships present in real-world data.
3. core.function.jsonArray
JSON array configuration
When configuring a JSON array field, you can specify:
-
- Minimum number of objects in the array
- Maximum number of objects in the array
The generator will then create arrays with a random number of objects within your specified range.
Structure and limitations
The JSON arrays follow these rules:
-
- Each array contains simple, flat JSON objects
- Nesting of arrays is not supported (no arrays within arrays)
- Each object in the array follows the same structure
Data generation
Once the schema has been built to your satisfaction, it’s time to generate data.
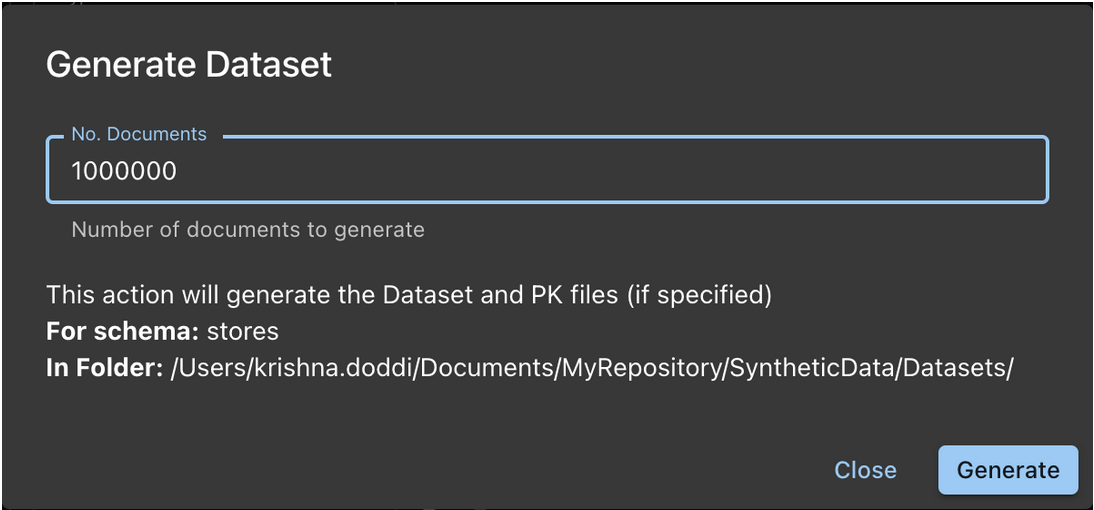
Picture shows generating synthetic dataset
-
- Dataset is generated and written to LocalStore/SyntheticData/DataSets/
- The dataset filename is schemaName.json
- This is a JSON Lines file
- If the document has fields marked as Primary Key (prefixed with double-dash), then, a schemaName.pk is also produced
- The .pk file is a CSV file
- If any field has the seq() function, the sequences are incremented by 1
- There is no limit to the number of documents
Example datasets
customer.json
|
1 2 3 4 5 6 7 8 9 |
[ {"id":"customer_1","name":"Lula Kuhic","gender":"Demi-man","age":65,"email":"Electa29@yahoo.com","address":{"street":"46938 VonRueden Village Suite 474","city":"Los Angeles","state":"California","zip":"90001","geo":{"latitude":33.7423,"longitude":-117.4412}},"phones":{"home":"(310) 788-5382","cell":"(310) 923-5319"}}, {"id":"customer_2","name":"Chelsea Wilderman","gender":"Transsexual female","age":58,"email":"Augusta_Mann27@yahoo.com","address":{"street":"8409 Jesse Mill Apt. 289","city":"Sacramento","state":"California","zip":"95814","geo":{"latitude":38.8607,"longitude":-121.0356}},"phones":{"home":"(916) 879-6009","cell":"(916) 503-2269"}}, … ] |
customer.pk
|
1 2 3 4 |
id,name "customer_1","Lula Kuhic" "customer_2","Chelsea Wilderman" … |
Dataset preview
You can preview the generated datasets. The preview panel supports previewing the data either in JSON format or table format.
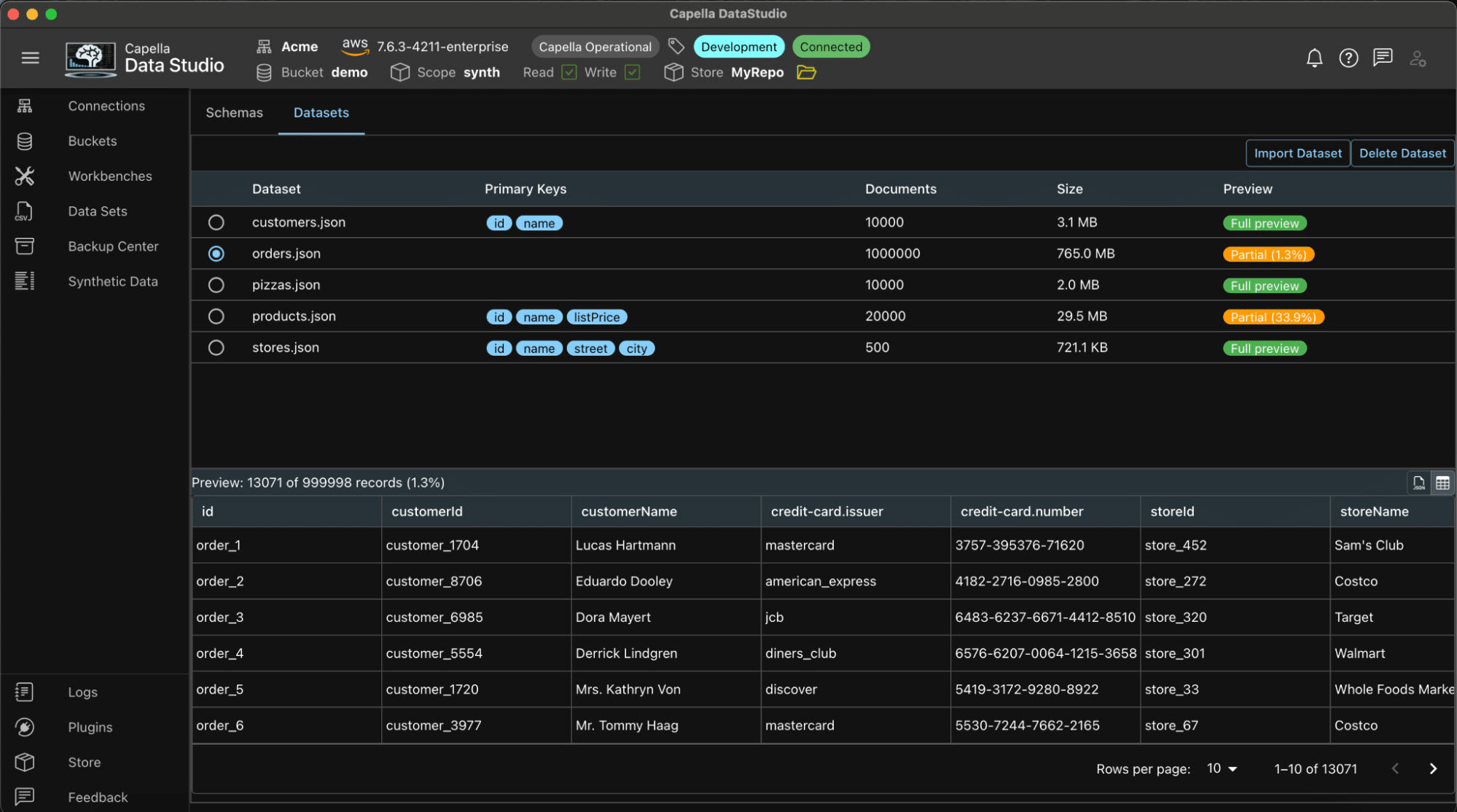
Picture shows the preview panel and the table preview
Import
You can import the generated dataset into your Couchbase collection:
-
- Import uses the cbimport utility and offers all its import options
- There is no file limit to import
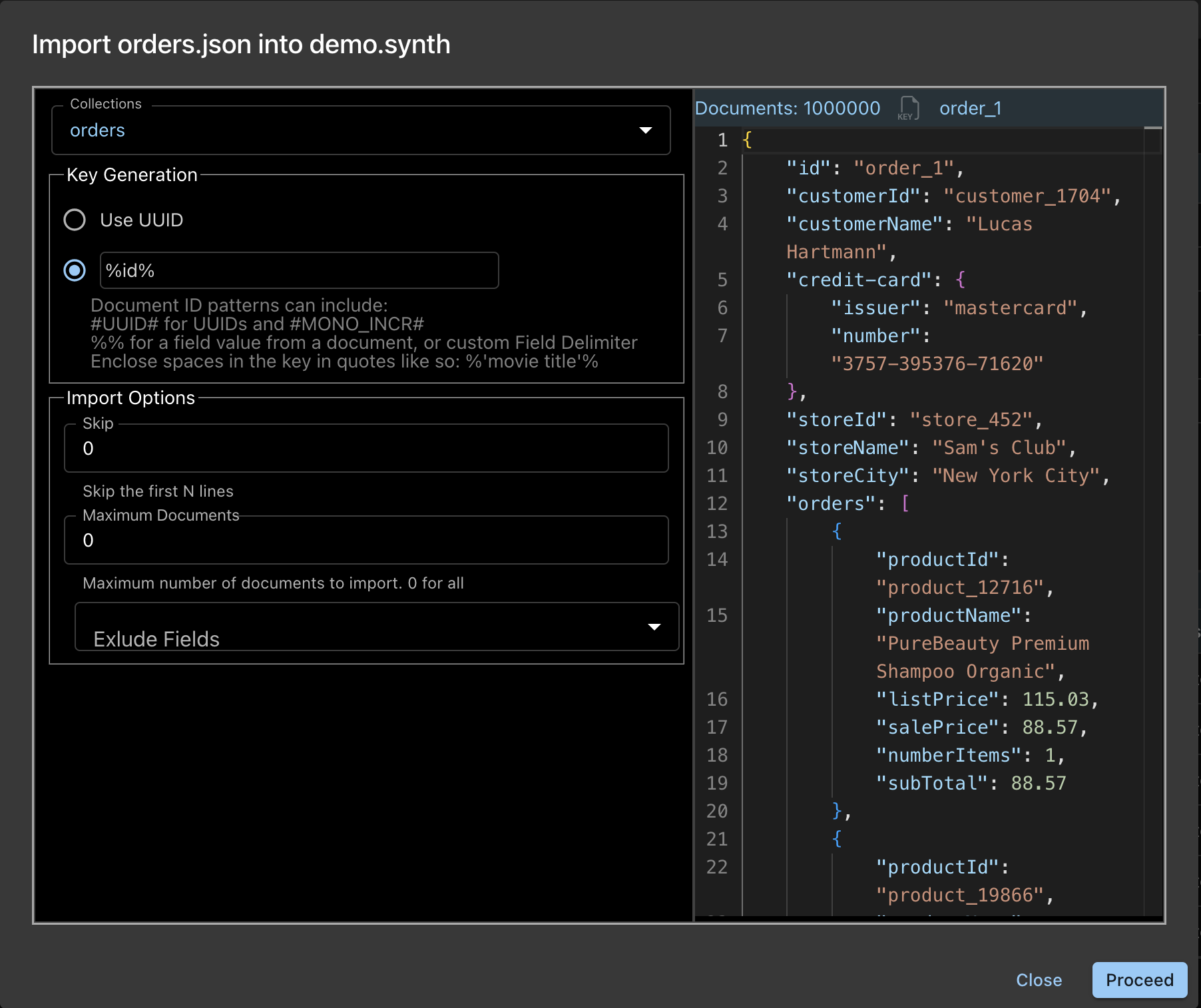
Picture shows the import dialog box and options
Ready to boost your productivity?
Capella DataStudio is the tool developers have been waiting for. Whether you’re managing Couchbase Server, Capella Operational, or Capella Columnar clusters, this app makes your job easier, faster, and yes—cooler.
Try Capella DataStudio for free and check out our tutorial videos:
With Capella DataStudio, managing data has never been this fun or productive!
Appendix – functions supported in expressions
Table shows list of available functions to use in expressions:
| Type | Example | Output |
| int(min,max) | int(1,10) | 6 |
| float(min,max) | float(1.234,10.587) | 5.824 |
| float(min,max,dec) | float(1,10,2) | 5.82 |
| normal(mean,std,dec) | normal(50,10,3) | 56.48 |
| bool() | bool() | FALSE |
| bool(bias) | bool(0.8) | TRUE |
| date(from,to) | date(01/01/2024,12/31/2024) | “02/02/2024” |
| time(from,to) | time(08:00 am, 5:00 pm) | “08:47 AM” |
| arrayItem(array) | arrayItem([“cat”,”mouse”,”dog”]) | “cat” |
| arrayItem(array) | arrayItem([“cat:2″,”mouse:1″,”dog:7”]) | “dog” |
| arrayItems(array,length) | arrayItems([“cat”,”mouse”,”dog”],2) | [“cat”,”mouse”] |
| arrayItems(array,length) | arrayItems([“cat:2″,”mouse:1″,”dog:7”]) | [“cat”,”dog”] |
| arrayKV(array,field) | arrayKV([“cat:2″,”mouse:1″,”dog:7″],”cat”) | 2 |
| gps(latitude,longitude) | gps(37.3382,-121.8863) | gpsObject |
| gpsNearby(gps,radius) | gpsNearby(%gps%,20) | gpsObject |
| seq(startNumber) | seq(1000) | 1030 |
| uuid() | uuid() | “e46b493a-…” |
| add(num1,num2) | add(1.23,3.45) | 4.68 |
| subtract(num1,num2) | subtract(1.23,3.45) | -2.22 |
| multiply(num1,num2) | multiply(1.23,3.45) | 4.24 |
| percent(num,den) | percent(1.23,3.45) | “35.65%” |
| accumulate(num,name) | accumulate(%orders.subTotal%,sale) | 1304.84 |