Report
FEATURES


Code snippet
CUSTOMERS



Resources



FAQ
Get quick answers about how Couchbase and MongoDB compare in terms of performance, scalability, and more.
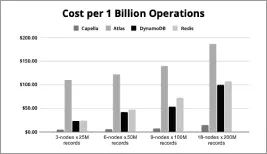
Couchbase outperforms MongoDB on throughput and latency in independent benchmarks, including YCSB testing, due to its memory-first architecture and built-in caching layer.
Couchbase Hyperscale Vector Index achieves 700+ QPS at billion-vector scale. MongoDB Atlas returned 2 QPS with 40-second latency in the same VectorDBBench test conditions.
Couchbase uses SQL++, a superset of SQL that supports JOINs, aggregations, and complex queries on JSON. MongoDB uses a proprietary query language with no native JOIN support.
Couchbase typically delivers lower TCO than MongoDB through built-in caching, fewer required add-ons, and more efficient cluster sizing, reducing infrastructure and licensing costs.
Yes. Couchbase includes Couchbase Lite and Capella App Services for offline-first mobile and edge apps. MongoDB deprecated Atlas Device Sync in 2024, leaving mobile users without a replacement.
Check out our developer portal to explore NoSQL, browse resources, and get started with tutorials.

Get hands-on with Couchbase in just a few clicks. Capella DBaaS is the easiest and fastest way to get started.

Want to learn more about Couchbase offerings? Let us help.