Applications get data from Couchbase Server in different ways – they can use basic key-value operations, secondary indexes (views) or full-text search. As a developer, how do you decide whether you should use secondary indexes or full-text search for your new app feature? This blog explains the differences between secondary indexes and full-text indexes so that you know what you should use to access data in Couchbase based on the scenario you have at hand.
Views in couchbase server are defined in javascript using a map function, which pulls out data from your documents and an optional reduce function that aggregates the data emitted by the map function. In the map function, you can specify what attributes to build the index on. Views are eventually indexed and queries are eventually consistent with respect to the documents stored.
Visually, this is how a data structure for a secondary index looks like –
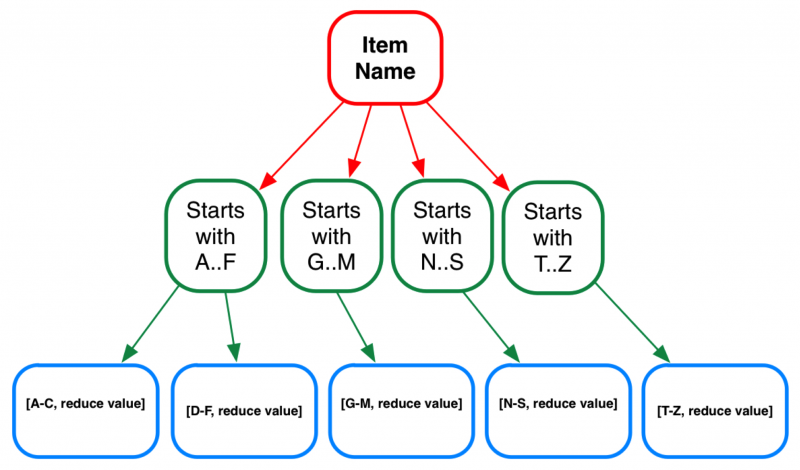
Using a B-tree data structure for secondary indexes optimizes quick key based lookups (in this case ‘Item name’) and range queries. For example, imagine that you are building a product catalog app and want to list all the product names that starting with ‘A’ till ‘F’. Using a secondary index in Couchbase on ‘item name’, only parts of the B-tree data nodes would need to be accessed.
So why use Couchbase’s full-text search capability?
Imagine that you want to list all the products in your store having the keyword ‘red’ – this includes items such as ‘red sweaters’, ‘red pants’ or even items with the color attribute ‘red’. A full-text index maps document terms to the list of document IDs – which means you can quickly get back the list of document IDs that have a particular term in them.
Couchbase server integrates with Elasticsearch, a full-text search engine. Using the Couchbase adapter for Elasticsearch, documents are replicated in real-time to Elasticsearch. Elasticsearch parses each document and builds a full-text index so that you can search across all your documents from your app.
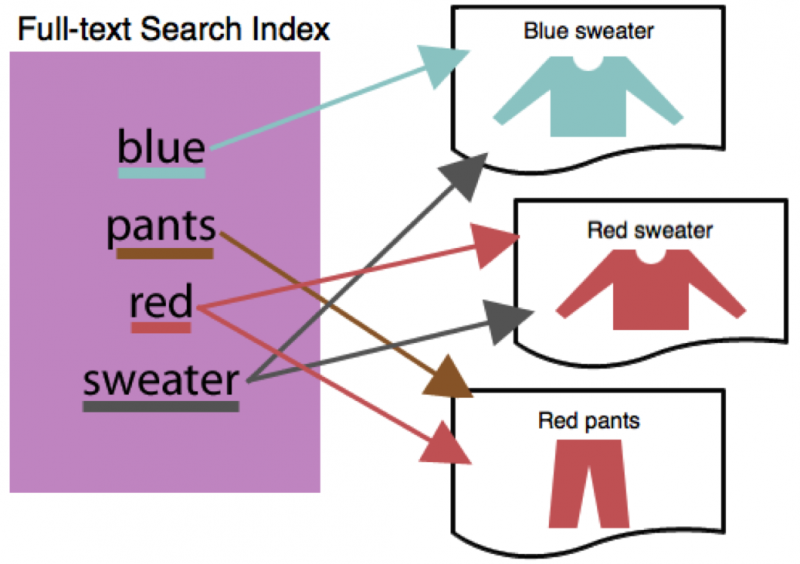
The figure above shows how a full-text index maps document terms found in the documents to document IDs. This data-structure is elegant for ad-hoc search querying – so for example, if you’re looking for “sweaters”, you get the document id’s relevant to Red and Blue sweaters.
Now that you understand about secondary indexes and full-text indexes, let’s take a look at when you should use full-text search and when you should consider using a secondary index in your app.
You should use full-text search when :
– you want to search through large amounts of textual data such as web page content, blog posts, digital articles and, content metadata. Full-text search indexes will allow you to search across the entire dataset, across any attribute in addition to some relevance form of ranking the results.
– your app needs term based search.
You should use secondary search when :
This was a great overview on how to choose search methods. Thank you.
I\’d like to add that another key differentiation is:
– Full Text Search results are generally intended for human consumption.
– Secondary Index results are intended for machine/programmatic consumption.