"Os aplicativos sem pesquisa são como a página inicial do Google sem a barra de pesquisa."

É difícil projetar um aplicativo sem uma boa pesquisa. Hoje em dia, também é difícil encontrar um banco de dados sem uma busca integrada. Do MySQL ao NoSQL, do Sybase ao Couchbase, todos os bancos de dados têm suporte para busca de texto - integrado como o Couchbase ou por meio de integração com a Elastic - como é o caso do Cassandra. Ao contrário do SQL, a funcionalidade de busca de texto não é padronizada. Todos os aplicativos precisam da melhor busca possível, mas nem todos os bancos de dados oferecem a mesma funcionalidade de busca de texto. É importante entender os recursos disponíveis e o desempenho de cada implementação de busca de texto e escolher o que melhor se adapta às necessidades do seu aplicativo. Após motivar a pesquisa de texto, você aprenderá sobre os recursos de pesquisa de texto necessários para uma pesquisa eficaz, comparará e contrastará esses recursos no MongoDB e no Couchbase com exemplos.
Vamos examinar os requisitos de pesquisa no nível do aplicativo.
-
Pesquisa exata: (WHERE item_id = "ABC482")
-
Pesquisa de intervalo: (WHERE item_type = "shoes" and size = 6 and price between 49.99 and 99.99)
-
Pesquisa de cordas:
-
(WHERE lower(name) LIKE "%joe%")
-
(WHERE lower(name) LIKE "%joe%" AND state = "CA")
-
-
Pesquisa de documentos:
-
Encontre joe em qualquer campo do documento JSON
-
Encontre documentos que correspondam ao número de telefone (408-956-2444) em qualquer formato (+1 (408) 956-2444, +1 510.956.2444, (408) 956 2444)
-
-
Pesquisa complexa: (WHERE lower(title) LIKE "%dictator%" and lower(actor) LIKE "%chaplin" and year < 1950)
As pesquisas de intervalo nos casos (1) e (2) podem ser tratadas com índices B-Tree típicos de forma eficiente. Os dados são bem organizados pelos dados completos que você está pesquisando. Quando você começa a procurar o fragmento da palavra "joe" ou a combinar números de telefone com vários padrões em um documento maior, os índices baseados em B-Tree sofrem. Simples tokenizações e o uso de índices baseados em B-Tree pode ajudar em casos simples. Você precisa de novas abordagens para seus casos de pesquisa no mundo real.
A seção de apêndice deste blog tem mais detalhes sobre como os índices de árvore invertida são organizados e por que eles são usados para a pesquisa empresarial em Lucene e Bleve. O Bleve alimenta a pesquisa de texto completo do Couchbse. O MongoDB usa índices baseados em B-Tree até mesmo para pesquisa de texto.
Vamos nos concentrar agora no suporte à pesquisa de texto no MongoDB e no Couchbase.
O conjunto de dados que usei é de https://github.com/jdorfman/awesome-json-datasets#movies
MongoDB: https://docs.mongodb.com/manual/text-search/
Couchbase: https://docs.couchbase.com/server/6.0/fts/full-text-intro.html
Visão geral da pesquisa de texto do MongoDB: Crie e consulte o índice de pesquisa de texto em strings de documentos do MongoDB. O índice parece ser um simples índice de árvore B com camadas adicionais para o analisador integrado. Isso traz muitos problemas de dimensionamento e desempenho que discutiremos mais adiante. O índice de pesquisa de texto está totalmente integrado à infraestrutura do banco de dados MongoDB e à sua API de consulta.
O MongoDB fornece índices de texto para suportar consultas de pesquisa de texto somente em strings. Seus índices de texto podem incluir apenas campos cujo valor seja uma string ou uma matriz de elementos de string. Uma coleção só pode ter um índice de pesquisa de texto, mas esse índice pode abranger vários campos.
Visão geral do Couchbase FTS (Full-Text Search): O Full-Text Search oferece amplos recursos para consultas em linguagem natural. O Bleve, implementado como um índice invertido, alimenta o índice de texto completo do Couchbase. O índice é implantado como um dos serviços e pode ser implantado em qualquer um dos nós do cluster.
MongoDB |
Couchbase |
|||
Nome |
Pesquisa de texto - 4.x |
Pesquisa de texto completo (FTS) - 6.x. |
||
Funcionalidade |
Pesquisa de texto simples para indexar campos de cadeia e pesquisar uma cadeia em apenas um ou mais campos de cadeia. Usa seu Índices B-Tree para o índice de pesquisa de texto.Pesquisa em toda a string composta e não pode separar os campos específicos. |
Pesquisa de texto completo para encontrar qualquer coisa em seus dados. Oferece suporte a todos os tipos de dados JSON (string, numérico, booleano, data/hora); a consulta oferece suporte a expressões booleanas complexas e expressões difusas em qualquer tipo de campo. Usa o índice invertido para o índice de pesquisa de texto. |
||
Instalação |
Pesquisa de texto: Disponível com a instalação do MongoDB. Não há opção de instalação separada. |
Disponível com a instalação do Couchbase. Pode ser instalado com outros serviços (dados, consulta, índice etc.) ou instalado separadamente em nós de pesquisa distintos. |
||
Criação de índice em um único campo |
db.films.createIndex({ title: "text" }); |
curl -u Administrador:senha -XPUT http://localhost:8094/api/index/films_title -H 'cache-control: no-cache' -H 'content-type: application/json' -d '{ "name": "films_title", "type": "fulltext-index", "params": { "mapping": { "default_field": "title" } }, "sourceType": "couchbase", "sourceName": "films" }' |
||
Criação de índice em vários campos |
db.films.createIndex({ title: "text", genres: "text"});Antes de criar esse índice, você precisa eliminar o índice anterior. Só pode haver um índice de texto em uma coleção. Você precisa do nome dele, que pode ser obtido por: db.films.getIndexes() ou especificar o nome ao criar o índice.db.films.dropIndex("title_text"); |
Você pode criar vários índices em um bucket (ou espaço de chave) sem restrições.curl -u Administrator:password -XPUT http://localhost:8094/api/index/films_title_genres -H 'cache-control: no-cache' -H 'content-type: application/json' -d '{ "name": "films_title_genres", "type": "fulltext-index", "params": { "mapping": {"types": { "genres": { "enabled": true, "dynamic": false }, "title": { "enabled": true, "dynamic": false }}}}, "sourceType": "couchbase", "sourceName": "films" }' |
||
Usando pesos |
db.films.createIndex({ title: "text", genres: "text"}, {weights:{title: 25}, name : "txt_title_genres"}); |
Feito dinamicamente por meio do reforço usando o ^ mofidier.curl -XPOST -H "Content-Type: application/json" \ http://172.23.120.38:8094/api/index/films_title_genres/query \ -d '{ "explain": true, "fields": [ "*" ], "highlight": {}, "query": { "query": "title:charlie^40 genres:comedy^5" } }' |
||
Opção de idioma |
O idioma padrão é o inglês. Passe um parâmetro para alterar isso.db.films.createIndex({ title: "text"}, { default_language: "french" }); |
Os analisadores estão disponíveis em 24 idiomas. Você pode alterá-lo ao criar o índice alterando o seguinte parâmetro."default_analyzer": "fr", |
||
Índice de texto sem distinção entre maiúsculas e minúsculas |
Não diferencia maiúsculas de minúsculas por padrão. Estendido para novos idiomas. |
Não diferencia maiúsculas de minúsculas por padrão. |
||
insensível a diacríticos |
Com a versão 3, o índice de texto não é sensível a diacríticos. |
Sim. Ativado automaticamente no analisador apropriado (por exemplo, francês) |
||
Delimitadores |
Traço, hífen, sintaxe_padrão, aspas, pontuação_terminal e espaço em branco |
Cada trabalho é analisado com base na especificação da linguagem e do analisador. |
||
Idiomas |
15 idiomas:dinamarquês, holandês, inglês, finlandês, francês, alemão, húngaro, italiano, norueguês, português, romeno, russo, espanhol, sueco, turco |
Os filtros de tokens são compatíveis com os seguintes idiomas.
Árabe, catalão, chinês, japonês, coreano, curdo, dinamarquês, alemão, grego, inglês, espanhol (castelhano), basco, persa, finlandês, francês, gaélico, espanhol (galego), hindi, húngaro, armênio, indonésio, italiano, holandês, norueguês, português, romeno, russo, sueco, turco |
||
Tipo de índice |
Índice B-Tree simples contendo uma entrada para cada palavra com haste em cada documento.Os índices de texto podem ser grandes. Eles contêm uma entrada de índice para cada palavra pós-temporal exclusiva em cada campo indexado para cada documento inserido. |
Índice invertido. Uma entrada por palavra com haste no índice INTEIRO (por partição de índice). Portanto, os tamanhos dos índices são significativamente menores. Quanto maior for o conjunto de dados, o índice FTS do Couchbase é muito mais eficiente em comparação com o índice de texto do MongoDB. |
||
Efeito de criação de índice em INSERTS. |
Afetará negativamente a taxa de INSERÇÃO. |
As taxas INSERT/UPSERT não serão afetadas |
||
Manutenção de índices |
Mantido de forma síncrona. |
Mantido de forma assíncrona. As consultas podem especificar a obsolescência usando o parâmetro de consistência. |
||
consultas de frases |
Suportado, mas lento.As pesquisas de frases são lentas, pois o índice de texto não inclui os metadados necessários sobre a proximidade das palavras nos documentos. Como resultado, as consultas por frase serão executadas com muito mais eficiência quando a coleção inteira couber na RAM. |
Suportado e rápido.
Inclua os vetores de termos durante a criação do índice. |
||
Pesquisa de texto |
db.films.find({$text: {$search: "charlie chaplin"}})Isso encontra todos os documentos que contêm charlie OU chaplin. Ter ambos, charlie e chaplin, dará uma pontuação maior. Como só pode haver UM índice de texto por coleção, essa consulta usa esse índice independentemente do campo que indexa. Portanto, é importante decidir qual dos campos deve estar no índice. |
|
||
Pesquisa de frase exata |
db.films.find({$text: {$search: "\"charlie chaplin\""}}) |
|
||
| Exclusão exata | db.films.find({$text: {$search: "charlie -chaplin"}});
Todos os filmes com "charlie", mas sem "chaplin". |
|
||
| Ordem dos resultados. |
Não ordenado por padrão.Projete e classifique por pontuação quando precisar.db.films.find({$text: {$search: "charlie chaplin"}}, {score: {$meta: "searchscore"}}).sort({$meta: "searchscore"}) |
Ordenado por pontuação (decrescente) por padrão. É possível ordenar por qualquer campo ou metadados. Isso ordena por título e pontuação (decrescente)
|
||
| Pesquisa de idioma específico |
db.articles.find({ $text: { $search: "leche", $language: "es" } }) |
O analisador de linguagem terá determinado as características do índice e da consulta. | ||
| Pesquisa sem distinção entre maiúsculas e minúsculas |
db.film.find( { $text: { $search: "Lawrence", $caseSensitive: true } } )
|
Determinado pelo analista. Use o filtro de token to_lower para que todas as pesquisas não diferenciem maiúsculas de minúsculas. Veja mais em: https://docs.couchbase.com/server/6.0/fts/fts-using-analyzers.html | ||
| Limitar o conjunto de resultados de retorno. |
db.films.find({$text: {$search: "charlie chaplin"}},{score: {$meta: "searchscore"}}).sort({$meta: "searchscore"}).limit(10) |
Oferece suporte ao equivalente de LIMIT e SKIP no SQL usando os parâmetros "size" e "from", respectivamente.
|
||
| Classificação complexa |
db.films.find({$text: {$search: "charlie chaplin"}},{score: {$meta: "searchscore"}}).sort({year : 1, $meta: "searchscore"}).limit(10) |
Ordenado por pontuação (decrescente) por padrão. É possível ordenar por qualquer campo ou metadados. Isso classifica por título (crescente), ano (decrescente) e pontuação (decrescente)
|
||
| Consulta complexa |
Use a estrutura de agregação. A pesquisa do $text pode ser usada em uma estrutura de agregação com algumas restrições.db.articles.aggregate(
|
Como você viu até agora, a própria consulta do FTS é bastante sofisticada. Além disso, o FTS oferece suporte a facetas para agrupamento e contagem simples. https://docs.couchbase.com/server/6.0/fts/fts-response-object-schema.html
Na próxima versão, o N1QL (SQL para JSON) usará o índice FTS para predicados de pesquisa.
|
||
| Índice completo do documento | Não oferece suporte à indexação completa de documentos. Todos os campos de cadeia de caracteres deverão ser especificados na chamada createIndex.
db.films.createIndex({título: "texto", gêneros: "texto", elenco: "texto", ano: "texto"});
|
Por padrão, ele suporta a indexação do documento completo, reconhece automaticamente o tipo de campo e o indexa de acordo. | ||
| Tipos de consulta |
Pesquisa básica, deve ter, não deve ter. |
Consultas Match, Match Phrase, Doc ID e PrefixConsultas de campo de Conjunção, Disjunção e BooleanoConsultas de intervalo numérico e intervalo de datasConsultas geoespaciaisConsultas Query String, que empregam uma sintaxe especial para expressar os detalhes de cada consulta (consulte Consulta Query String Query para obter informações) |
||
| Analisadores disponíveis | Somente analisadores incorporados. | Analisadores incorporados e personalizáveis. Veja mais em: https://docs.couchbase.com/server/6.0/fts/fts-using-analyzers.html#character-filters/token-filters |
||
Criar e pesquisar por meio da interface do usuário |
Não no produto básico. |
Integrado ao console |
||
| API REST |
Indisponível. |
Disponível.
https://docs.couchbase.com/server/6.0/fts/fts-searching-with-the-rest-api.html https://docs.couchbase.com/server/6.0/rest-api/rest-fts.html |
||
SDK |
A pesquisa de texto é incorporada à maioria dos SDKs do Mongo. Por exemplo, https://mongodb.github.io/mongo-java-driver/ |
https://docs.couchbase.com/java-sdk/2.7/full-text-searching-with-sdk.html |
||
| Tipos de dados suportados | Somente strings. Não há suporte para nenhum outro tipo de dado. | Todos os tipos de dados JSON e datas e horas.
String, numérico, booleano, data e hora, objeto e matrizes. GEOPOINT para consultas ao vizinho mais próximo. Veja : https://docs.couchbase.com/server/6.0/fts/fts-geospatial-queries.html |
||
| Vetores de prazo. | Sem suporte. | Disponível. Os vetores de termos são muito úteis na pesquisa de frases. | ||
| Facetamento | Sem suporte |
Termo FacetaFaceta de intervalo numéricoFaceta Intervalo de datashttps://docs.couchbase.com/server/6.0/fts/fts-response-object-schema.html |
||
| Consultas AND avançadas (conjunções) | Sem suporte. |
curl -u Administrator:password -XPOST -H "Content-Type: application/json" http://172.23.120.38:8094/api/index/filmsearch/query -d '{"explain": verdadeiro,"fields": [“*”],"highlight": {},"query": {"conjuncts":[ {"field": "title", "match": "kid"}, {"field": "cast", "match": "chaplin"}]}}’ |
||
| Consultas OR avançadas (disjuntos) | Sem suporte. |
curl -u Administrator:password -XPOST -H "Content-Type: application/json" http://172.23.120.38:8094/api/index/filmsearch/query -d '{"explain": verdadeiro,"fields": [“*”],"highlight": {},"query": {"disjuncts":[ {"field": "title", "match": "kid"}, {"field": "cast", "match": "chaplin"}]}}’ |
||
| Consultas de intervalo de datas | Sem suporte.
Necessita de pós-processamento, o que pode afetar o desempenho. |
Suportado pelo FTS.
{
|
||
| Consultas de intervalo numérico | Sem suporte. | curl -u Administrator:password -XPOST -H "Content-Type: application/json" http://172.23.120.38:8094/api/index/filmsearch/query -d '{ "explain": verdadeiro, "fields": [ “*” ], "highlight": {}, "query": { "field": "year", "min":1999, "max":1999, "inclusive_min": true, "inclusive_max":true } }’ |
Desempenho:
Embora uma comparação elaborada de desempenho ainda esteja pendente, fizemos uma comparação rápida com 1 milhão de documentos da Wikipédia. Veja o que vimos:
Tamanhos de índice.
| Couchbase (6.0) | MongoDB (4.x) | |
| Tamanho da indexação | 1 GB (queimadura) | 1,6 GB |
| Tempo de indexação | 46 segundos | 7,5 min |
Taxa de transferência de consultas de pesquisa (consultas por segundo):
Couchbase Mongodb
Termos de alta frequência 395 79
Med termos de frequência 6396 201
Baixa termos de frequência 24600 643
Alta ou Alta termos 145 82
Alta ou média termos 258 78
Pesquisa de frases 107 50
Resumo:
O MongoDB fornece um índice simples de pesquisa de strings e APIs para fazer pesquisas de strings. O índice B-tree que ele cria para a pesquisa de strings também é bastante grande. Não se trata de pesquisa de texto.
O índice de texto do Couchbase é baseado no índice invertido e é um índice de texto completo com um número significativamente maior de recursos e melhor desempenho.
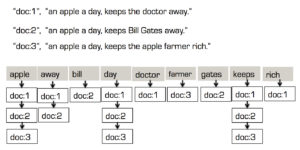
Por que o Inverted Index para o índice de pesquisa?
Pesquisas simples, exatas e de intervalo podem ser realizadas por Árvore B como índices para uma varredura eficiente. As pesquisas de texto, no entanto, têm requisitos mais amplos de stemming, stopwords, analisadores etc. Isso requer não apenas uma abordagem de indexação diferente, mas também filtragem pré-indexação, ferramentas de análise personalizadas, stemming específico de idioma e insensibilidade a casos.
O índice de pesquisa pode ser criado usando o B-TREE tradicional. Mas, diferentemente dos índices B-tree em valores escalares, o índice de texto terá várias entradas de índice para cada documento. Um índice de texto somente para esse documento poderia ter até 12 entradas: 8 para nomes de elenco, uma para gêneros, duas para o título depois de remover a palavra de parada (in) e o ano. Documentos maiores e contagens de documentos aumentarão exponencialmente o tamanho do índice de texto.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
{ "cast": [ "Whoopi Goldberg", "Ted Danson", "Will Smith", "Nia Long" ], "gêneros": [ "Comédia" ], "título": "Fabricado na América", "ano": 1993 } } |
Solução: Aqui entra a árvore invertida. A árvore invertida tem os dados (termo de pesquisa) na parte superior (raiz) e tem várias chaves de documentos nas quais o termo existe na parte inferior, fazendo com que a estrutura se pareça com uma árvore invertida. Índices de texto populares em Lucene, Bleve são todos implementados como índices invertidos.