Temos o prazer de anunciar que o lançamento do Couchbase Cloud 1.6 vem com uma série de aprimoramentos importantes, especialmente na importação de dados.
Esses aprimoramentos de recursos incluem a importação de documentos usando o Nuvem do Couchbase UI da Web com várias opções de geração e configuração de chaves. Isso proporciona uma maneira fácil de importar rapidamente pequenos conjuntos de dados, normalmente com menos de 100 MB, em uma variedade de formatos. Trata-se de uma extensão do o familiar cbimport ferramentae explora ainda mais as tecnologias nativas da nuvem, como o armazenamento local S3.
O novo recurso Import faz parte de uma estratégia de migração de dados, do local para a nuvem, além do Backup/Restore e do XDCR
Nesta postagem do blog, veremos alguns casos de uso e algumas "pegadinhas" durante a importação com o Couchbase Cloud. Não se trata de uma análise detalhada e exaustiva de todos os recursos; consulte nossa excelente documentação sobre o Couchbase Cloud para isso.
Visão geral dos recursos
Vamos dar uma olhada rápida na lista de recursos do Couchbase Cloud 1.6:
| Função | Operação |
|---|---|
| Expressão de geração de chave personalizada - O mesmo formato familiar da ferramenta cbimport - Ou escolha o UUID gerado automaticamente Verificar a chave gerada - Cole um documento JSON de amostra na interface do usuário e examine visualmente a chave gerada Opções de configuração - Ignorar documentos - Documentos de limite - Ignorar campos em documentos importados - Adicionalmente CSV - Inferir tipos de campo - Além disso, CSV - omitir tipos vazios |
Importações assíncronas e simultâneas - Continue com outras atividades enquanto importa seus dados em segundo plano Notificação por e-mail - Seja notificado por e-mail quando a importação for concluída. Vários métodos para carregar arquivos - Por meio do navegador da Web - Diretamente para o S3 por meio de cURL Armazenamento local de arquivos importados - Reimportar sem recarregar Importar histórico de atividades - Auditar sua atividade de importação Importar preservação de registros - Facilitar a solução de problemas |
O conjunto de dados de exemplo
Para ilustrar alguns dos recursos, usaremos um documento decididamente pequeno (apenas três) e decididamente artificial. Como o Import permite importar dados de uma variedade de formatos de arquivo, é necessário relembrar rapidamente quais são esses tipos de arquivo:
-
- Lista JSON
- Uma lista JSON é uma lista (indicada por colchetes) de qualquer número de objetos JSON (indicados por chaves) separados por vírgulas.
- Linhas JSON
- As linhas JSON são um arquivo em que cada linha tem um objeto JSON completo separado nessa linha.
- CSV (variáveis separadas por vírgulas)
- O formato CSV "achata" os dados JSON e não oferece suporte a matrizes ou valores aninhados.
- Arquivo
- Arquivo compactado de documentos JSON individuais
- Lista JSON
Agora, vamos dar uma olhada nos três documentos em si:
Pessoa com id 101 |
Pessoa com id 102 |
Pessoa sem identificação |
| { "id": 101, "short.name": "JS", "%SS%": "091-55-1234", "name":{ "first": "John", "full.name": "John P Smith", "last": "Smith" }, "contato": { "@email": "john.smith@gmail.com“, "Office": { "cell#": "1-555-408-1234" } } } |
{ "id": 102, "short.name": "JS", "%SS%": "091-55-1234", "name":{ "first": "Jane", "full.name": "Jane P Smith", "last": "Smith" }, "contato": { "@email": "jane.smith@gmail.com“, "Office": { "cell#": "1-555-408-2345" } } } |
{ "short.name": "AS", "%SS%": "091-55-0000", "name":{ "primeiro": "Adam", "full.name": "Adam P Smith", "last": "Smith" } } |
O arquivo people.json
Crie um arquivo com os três documentos acima.
|
1 2 3 4 5 |
[ {"%SS%":"091-55-2345","contact":{"@email":"jane.smith@gmail.com","Office":{"cell#":"1-555-408-2345"}},"id":102,"name":{"first":"Jane","full.name":"Jane P Smith","last":"Smith"},"short.name":"JS"}, {"%SS%":"091-55-1234","contact":{"@email":"john.smith@gmail.com","Office":{"cell#":"1-555-408-1234"}},"id":101,"name":{"first":"John","full.name":"John P Smith","last":"Smith"},"short.name":"JS"}, {"%SS%":"091-55-0000","name":{"first":"Adam","full.name":"Adam P Smith","last":"Smith"},"short.name":"AS"} ] |
O processo de importação de dados
Agora que temos o arquivo de dados, vamos começar o processo de importação. Antes de começarmos, criei um teste de bucket com tamanho de 100 MB. Isso é suficiente para que eu possa importar esse pequeno conjunto de dados. Alguns pontos a serem observados:
-
- Você precisa ter Administrador privilégios.
- O balde deve existir.
- O tamanho do bucket deve ser suficiente para conter o conjunto de dados importado.
- Não é necessário ter um usuário do banco de dados.
- Não é necessário lista branca seu IP.
Fazer upload do arquivo
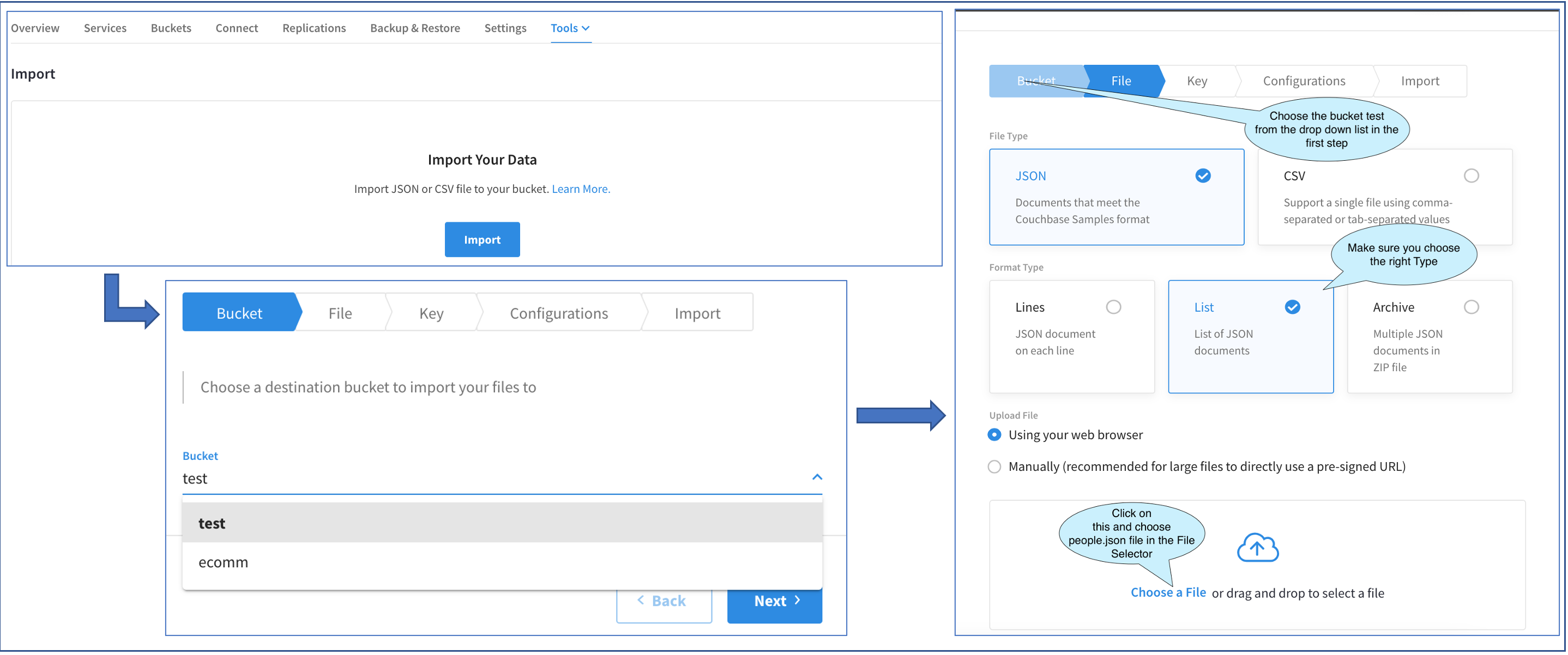
O diagrama acima mostra a progressão de três telas. Acesse a primeira tela Import Main UI Cluster > Tools > Import.
Como estamos realizando a importação pela primeira vez, a interface principal de importação tem apenas um Importação botão. Ao clicar nesse botão, aparece a tela Fly-out de importação. O restante das operações será realizado nesse Fly-out.
A primeira tela do Fly-out nos permite escolher o balde. Tenho dois baldes. Vamos escolher o teste balde.
A próxima tela nos pede para escolher o tipo de arquivo. Nosso arquivo de amostra é um arquivo JSON e o tipo de arquivo é um LISTA. Depois de escolher isso, temos algumas opções para carregar o arquivo. Podemos fazer isso pelo navegador ou fazer o upload manualmente por meio de um URL.
Normalmente, arquivos com menos de 100 MB podem ser carregados por meio do navegador. Portanto, vamos escolher essa opção. Clicando em Escolha um arquivo traz à tona o Seletor de arquivos (não mostrado aqui). Esse é o seletor de arquivos padrão. Vamos em frente e escolher people.json.
Se o arquivo fosse maior que 100 MB, teríamos optado por carregar manualmente por meio de um URL. Ao clicar nessa opção, apareceria uma caixa de texto com um cURL que teríamos copiado e executado em uma janela de terminal em nosso laptop.
Independentemente do método de upload de arquivos, o restante do processo é o mesmo.
Gerar a chave
Depois que o arquivo for escolhido, vamos prosseguir para a seção de geração de chaves. Observe que, neste momento, o arquivo ainda não foi carregado de fato. Isso ocorrerá algumas etapas mais adiante.
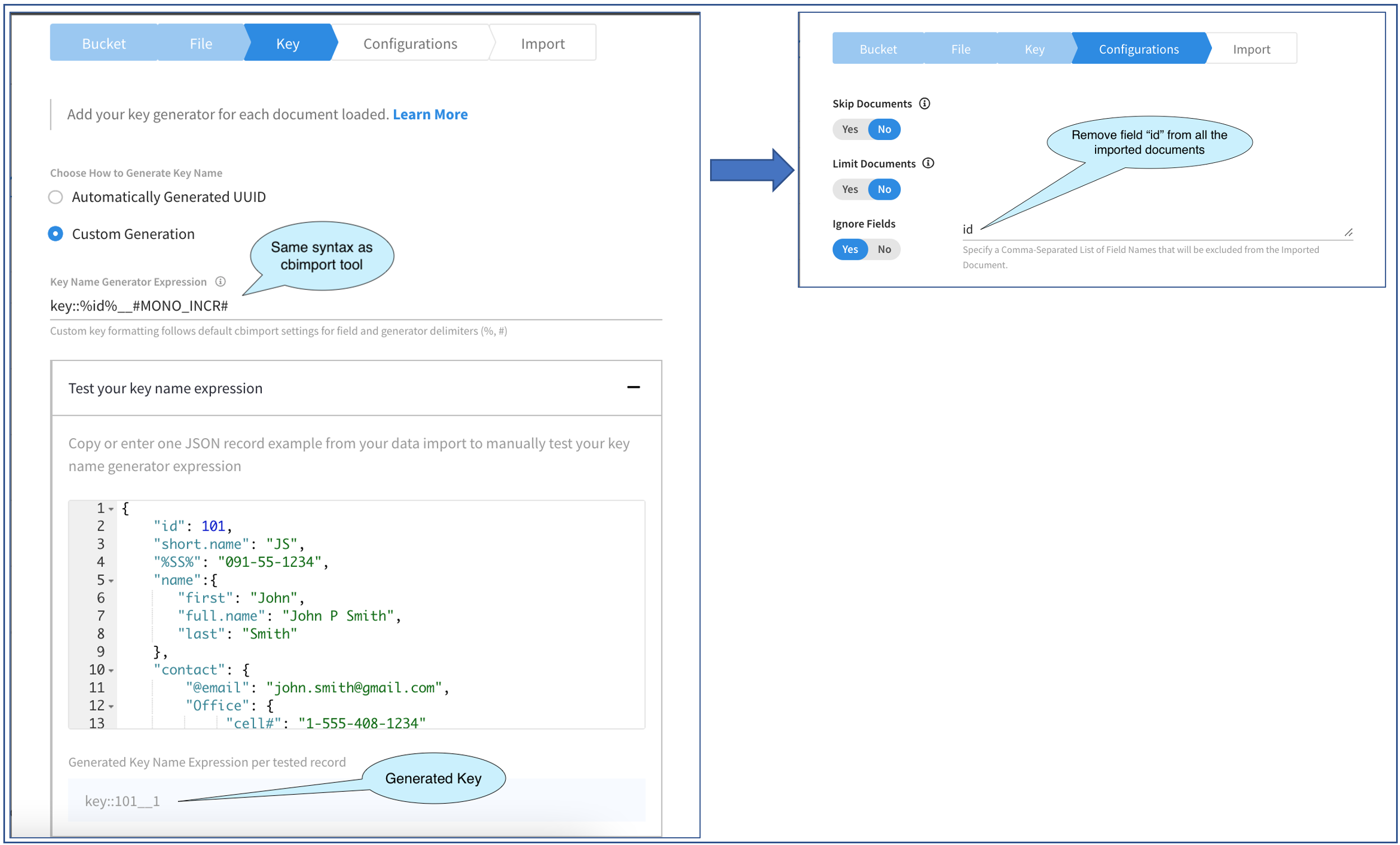
A figura acima mostra a progressão por duas telas no Fly-out de importação.
A primeira tela nos permite especificar como a chave do documento deve ser gerada. Aqui temos algumas opções: Ou geração automática a chave ou gerar a chave usando um expressão fornecido por nós. A primeira opção é simples e pode ser usada para casos de teste pequenos em que a chave do documento não é importante. Vamos selecionar a segunda opção e gerar as chaves do documento de acordo com um determinado padrão.
Precisamos especificar a Expressão na Expressão do gerador de nome de chave. Trata-se de uma string e segue a mesma sintaxe dos geradores de chaves cbimport. A chave gerada pode ser texto estático ou derivado de um valor do campo no documento a função de gerador como MONO_INCR ou UUID com qualquer combinação dos três.
Alguns aspectos a serem observados ao criar a expressão:
-
- Os nomes dos campos são sempre colocados entre "%"
- As funções do gerador estão sempre entre "#"
- Qualquer texto que não esteja envolvido em "%" ou "#" é um texto estático e estará no resultado de todas as chaves geradas.
- Se uma chave precisar conter um "%" ou "#" em um texto estático, eles precisarão ser substituídos por um "%" ou "#" duplo (ex.: "%%" ou "##").
- Se uma chave não puder ser gerada porque o campo especificado no gerador de chaves não está presente no documento, a chave será ignorada.
A expressão que escolhemos para este exemplo é: key::%id%__#MONO_INCR#. Com isso queremos dizer:
-
- Substitua %id% pelo valor do campo "id" no documento.
- Substitua #MONO_INCR# por um número monotonicamente crescente começando com 1.
- Trate o restante como texto estático na chave
Essa tela também oferece uma maneira interessante de verificar a sintaxe da expressão, bem como a chave real gerada pela expressão.
Para isso, precisamos colar um documento de amostra no arquivo Editor JSON. Eu fiz isso, como você pode ver. Dos três documentos no arquivo, apenas os dois primeiros têm a id e, por isso, tive o cuidado de escolher um documento que tivesse o campo. Esse validador, é claro, funciona apenas com documentos JSON e não com um documento CSV. Por fim, como você pode ver na imagem acima, eu "embelezei" o documento JSON. Isso foi feito por conveniência. Isso teria funcionado mesmo se eu tivesse colado o documento em uma única linha. À medida que digitamos a expressão, o gerado é mostrada na parte inferior. É muito interativo e permite que você brinque com as expressões e verifique instantaneamente a chave gerada.
Quando estiver satisfeito, você poderá passar para configuração e é exatamente isso que faremos. Essa tela oferece três opções, das quais estamos interessados na última, Ignorar campos. Essa opção permite que você importe todos os documentos do arquivo, mas sem os campos especificados no documento. Essa opção permite que você especifique vários campos, delimitados por vírgulas.
Em nosso exemplo aqui, como criamos o valor de id parte da chave do documento, realmente não precisamos que essas mesmas informações também estejam no documento, portanto, vamos removê-las. Para fazer isso, digitei a string como id. Observe que este é um texto simples e você não deve colocar os nomes dos campos aqui dentro de "%".
Exemplos de geração de chaves
| Expressão de geração de chaves | Chave gerada |
|---|---|
| key::%id%::#MONO_INCR# | key::102::1 |
| key::%id%::#UUID# | key::102::29ee002c-06e4-4dbf-bb5b-b2f148167536 |
| key::%id%::###UUID# | key::101::#3c671afe-fb02-48aa-a027-d74a8d38bcbc |
chave::%short.name%_%%%SS%%% |
chave::AS_091-55-0000 |
key::%name.full.name% |
key::Adam P Smith |
| key::%contact.@email% | key::jane.smith@gmail.com |
| key::%%%contato.@email% | key::%jane.smith@gmail.com |
| contato##::%contato.@email% | contact#::jane.smith@gmail.com |
| Tel##:%contato.Office.cell#% | Tel#:1-555-408-1234 |
Verificar e executar a importação
Agora que a chave foi gerada de forma satisfatória e a importação de dados foi configurada para ignorar a chave id nos documentos, vamos prosseguir para a próxima etapa: verificar e executar a importação.
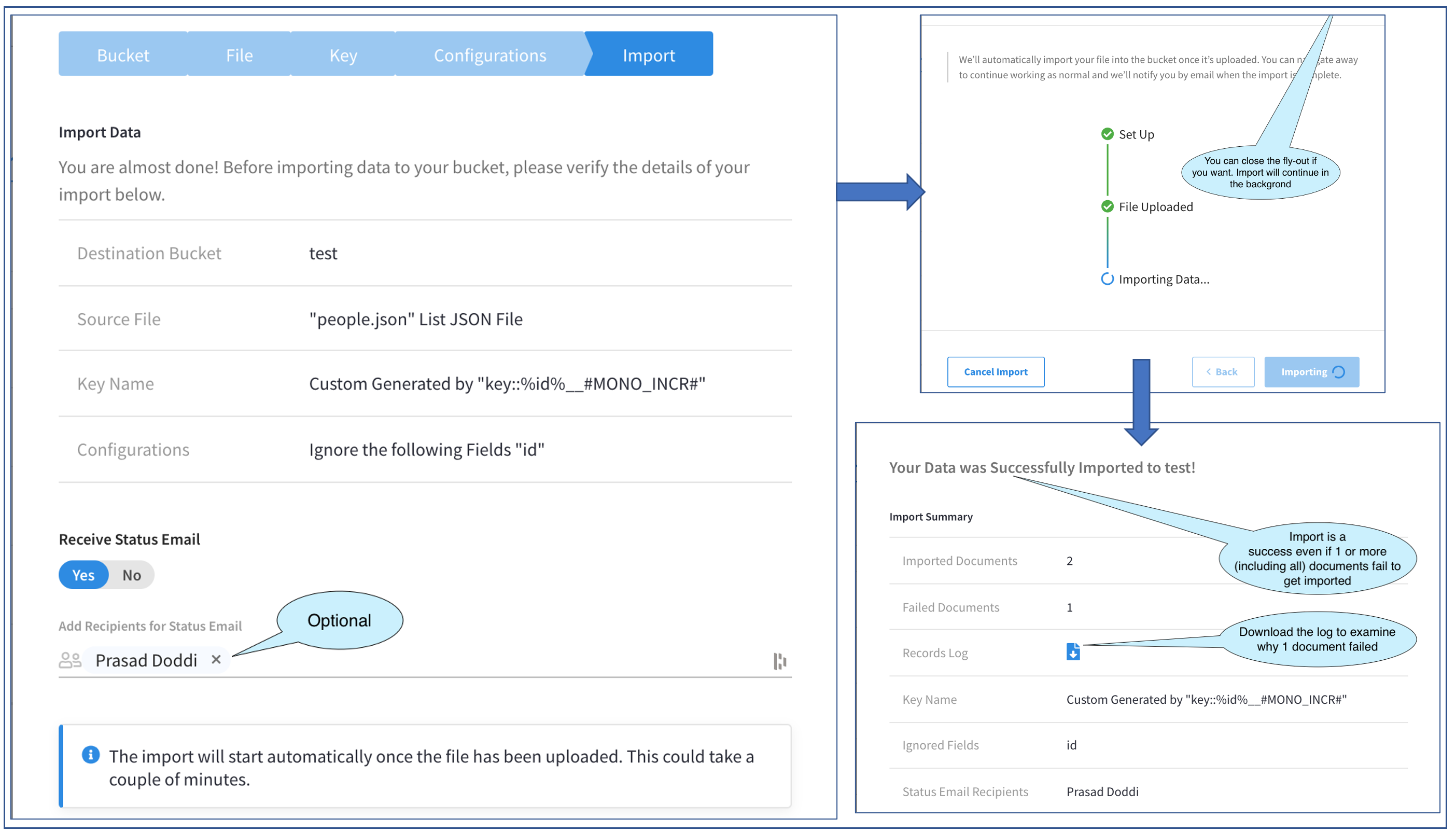
A imagem acima mostra a progressão por três telas no Fly-out.
Vamos começar com a primeira. Essa tela verifica o que pretendemos fazer e nos permite voltar atrás caso tenhamos perdido alguma coisa. Além disso, ela nos permite especificar uma lista de usuários que receberão um e-mail de confirmação após a conclusão da importação. Isso é muito conveniente para arquivos de importação grandes que podem ser executados em segundo plano enquanto realizamos outras tarefas. Isso, é claro, é opcional. Eu optei por me adicionar para receber o e-mail de confirmação. A lista de usuários que são exibidos no seletor para Adicionar destinatários são os administradores que fazem parte do projeto.
A próxima tela inicia a importação propriamente dita. A importação é executada no modo fundo e não precisa que o Fly-out esteja aberto. Podemos fechar o Fly-out clicando no botão X no canto superior direito (não visível na foto). Também temos a opção de cancelamento a importação. Neste exemplo, eu a manterei aberta até a conclusão.
Após a conclusão, a terceira tela da imagem acima é exibida. Observe que ainda é possível acessar essa tela na página Main Import (Importação principal), e verificaremos isso mais tarde.
A terceira tela exibe a Resultado da importação. Nesse momento, também receberíamos o e-mail de confirmação. Em nosso exemplo aqui, essa tela nos informa que dois documentos foram importados com êxito e um falhou. O status geral é de uma importação bem-sucedida.
Um aspecto importante a ser observado aqui é que o sucesso geral da importação não depende do sucesso da importação de dados de todos, alguns ou nenhum dos documentos. O sucesso do processo de importação é apenas o fato de o processo ter sido concluído sem falhas.
Voltando ao nosso exemplo, vamos nos aprofundar um pouco mais nessa falha de um documento. Para solucionar problemas essa falha, recebemos um botão útil para download o Registro de registros e é isso que faremos.
Solução de problemas com o registro de registros
Este é o registro de registros que baixei. (Eu recortei algumas linhas).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
Custom generator key: key::%id%__#MONO_INCR# User args: --verbose --ignore-field id ======================= 2021-06-03T01:50:07.322+00:00 (Rest) GET https://cb:8091/pools/default 200 2021-06-03T01:50:07.322+00:00 (Plan) Executing transfer plan ... 2021-06-03T01:50:07.330+00:00 (Rest) GET https://cb:8091/pools/default/buckets 200 2021-06-03T01:50:07.331+00:00 (Rest) GET https://cb:8091/pools/default/nodeServices 200 2021-06-03T01:50:07.356+00:00 ERRO: Key generation for document failed, field id does not exist -- jsondata.(*Parallelizer).... 2021-06-03T01:50:07.376+00:00 ERRO: Data transfer failed: Some errors occurred while transferring data, ... 2021-06-03T01:50:07.376+00:00 (Plan) Transfer plan failed due to error Some errors occurred while transferring data, ... 2021-06-03T01:50:07.376+00:00 JSON import failed: 2 documents were imported, 1 documents failed to be imported 2021-06-03T01:50:07.376+00:00 JSON import failed: Some errors occurred while transferring data, see logs for more details JSON import failed: 2 documents were imported, 1 documents failed to be imported JSON import failed: Some errors occurred while transferring data, see logs for more details |
A linha de erro é: ERRO: Falha na geração de chaves para o documento, o campo id não existe. O erro diz que o campo "id" não existe em algum documento. Isso, é claro, está correto e é o motivo pelo qual esse documento não foi importado.
Verificação dos documentos importados
Agora que a importação foi concluída e também realizamos um pouco de solução de problemas, vamos verificar os documentos importados.
Precisamos ver dois documentos com o formato de chave correto e os documentos não devem ter o id já que configuramos o Import para ignorar esse campo. Para verificar, vamos abrir a janela Ferramentas > Visualizador de documentos.
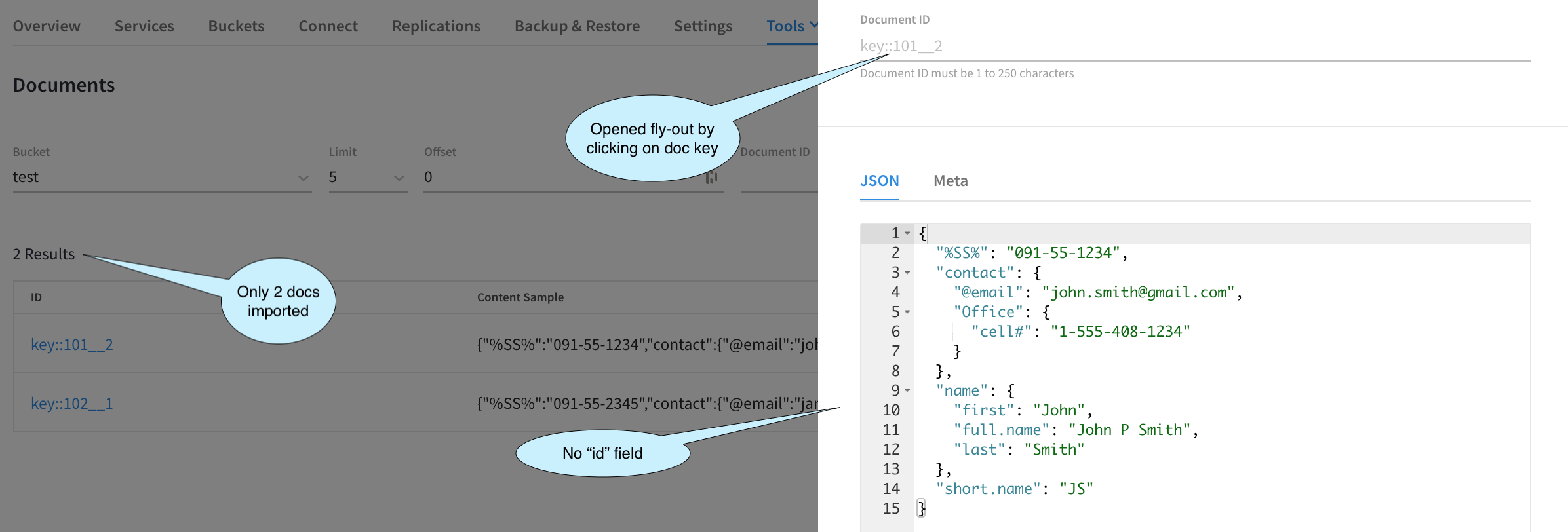
A imagem acima apenas confirma que alcançamos o resultado desejado.
Tela principal de importação: Lista de atividades
Quando o Fly-out de importação é fechado, voltamos à tela principal. Agora, vemos uma lista de todas as nossas atividades de importação de dados. No exemplo abaixo, realizei várias importações e também cancelei uma para ilustrar a interface do usuário da atividade.
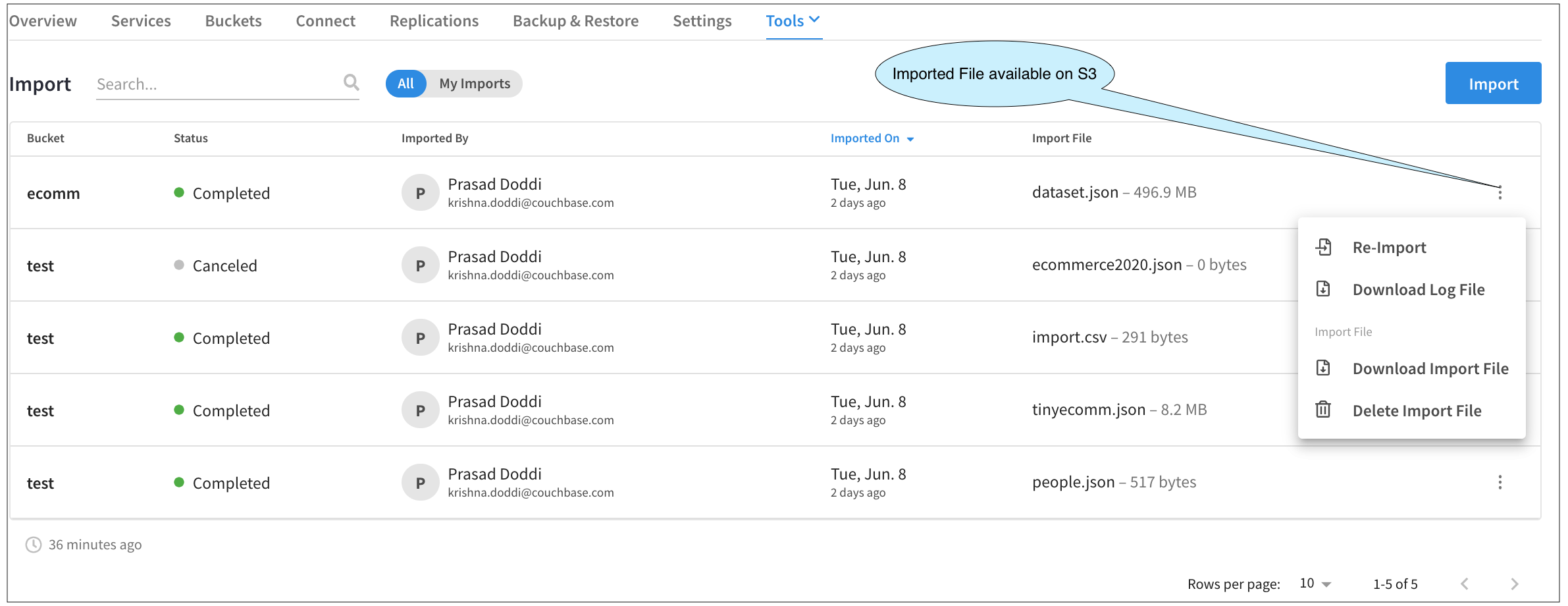
Se tivéssemos fechado o Fly-out de importação (clicando no botão X), então o status disso apareceria como Em andamento.
Essa tela não funciona apenas como um registro de auditoria, mas também podemos realizar outras atividades.
Clicar em qualquer linha aqui abre a janela Resultado da importação Fly-out. Clicando no botão botões de três pontos em cada linha abre um menu no qual podemos fazer o download do arquivo de registro, etc.
Um dos itens mais interessantes do menu é Reimportar. Como os arquivos carregados estão agora no armazenamento em nuvem (S3 no caso da AWS, por exemplo), podemos usar o mesmo arquivo para importação, evitando a etapa inicial de carregar o arquivo do seu laptop. Ao clicar nessa opção, você passará novamente pelas etapas de importação, mas, dessa vez, poderá reutilizar o arquivo importado e manter todas as seleções feitas anteriormente, como Tipo de arquivo, Expressão de chave etc. É claro que você sempre poderá alterá-las. Como o processo é praticamente o mesmo, não passaremos por isso novamente nesta demonstração.
Práticas recomendadas e "Peguei!"s
Aqui estão algumas práticas recomendadas a serem consideradas em seu projeto, bem como alguns "pegadinhas!" comuns a serem evitados:
-
- Verifique o tipo de arquivo durante a importação
- Não misture
LINHASeLISTAtipo Arquivos JSON. - A importação pode ser exibida como bem-sucedida, mas nenhum documento ou apenas um documento (o último) será importado.
- Não misture
- Verifique a chave gerada sempre que possível ao usar a expressão de geração de chave personalizada.
- Tome cuidado especial com o delimitador de campo %
- Por exemplo, se você não o fizer e especificar a chave personalizada como
key::idem vez dekey::%id%no final do processo de importação de dados, você verá apenas um documento com a chave comokey::id
- Certifique-se de que o tamanho do balde seja suficiente para armazenar os documentos importados.
- Se você tiver um cluster de três nós e especificar 100 MB como o tamanho do bucket e decidir importar um arquivo de 2 GB, com nomes de chave longos (como UUIDs gerados automaticamente), o bucket será rapidamente preenchido com metadados.
- Lembre-se de que todos os Buckets do Couchbase Cloud são apenas de ejeção de valor.
- Use o cURL para importar arquivos grandes, geralmente com mais de 100 MB.
- Toda vez que você quiser fazer upload por meio disso, o cURL poderá ser diferente, portanto, não reutilize o comando cURL antigo.
- Verifique o tipo de arquivo durante a importação
Conclusão
Esta foi uma análise mais detalhada de alguns casos de uso e de alguns "pegadinhas" durante a importação de dados com o Couchbase Cloud. Confira este artigo para saber mais sobre outros novos recursos do Couchbase Cloud 1.6, incluindo a nova API pública e muito mais.
Se você ainda não aproveitou as vantagens do Avaliação gratuita do Couchbase Cloud No entanto, experimente hoje mesmo!