A sintaxe da consulta é limitada. As consultas são ilimitadas.
Empurramento de predicado, agrupar por pushdown, paginação de deslocamento, paginação do conjunto de teclas, otimização da união, otimização de pesquisaJá discutimos tudo isso. Ainda assim, é importante entender o fluxo de execução padrão e simples - embora lento - da consulta.
Lukas Eder explicou o ordem real de execução do SQL. Como o N1QL é inspirado no SQL e o segue de perto, essa explicação também se aplica aqui. Recomendo muito a leitura.
Com o N1QL, você pode usar a explicação visual para ver a estrutura do plano e o fluxo de dados. Essa é uma maneira fácil de entender a ordem de execução antes de otimizar o desempenho por meio da criação de índices. Usei o exemplo de viagem incorporado e, portanto, forcei a varredura primária com a dica USE INDEX.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
SELECT hotel.name, hotel.country, COUNT(hr.ratings.Service) csr, RANK() OVER(ORDER BY COUNT(hr.ratings.Service) ), DENSE_RANK() OVER(ORDER BY COUNT(hr.ratings.Service)) FROM `travel-sample` AS hotel USE INDEX (def_primary) INNER JOIN `travel-sample` AS airport ON (hotel.country = airport.country) LEFT OUTER UNNEST hotel.reviews AS hr WHERE hotel.type = "hotel" AND airport.type = "airport" AND hr.ratings.Service >= 4 GROUP BY hotel.name, hotel.country HAVING COUNT(hr.ratings.Service) > 0 ORDER BY COUNT(hr.ratings.Service) OFFSET 0 LIMIT 10 |
Aqui está o plano visual. A execução do plano e o fluxo de dados são de baixo para cima. Começa com uma varredura de índice primário e uma varredura de índice secundário e termina com o operador de paginação LIMIT antes de retornar os resultados para o aplicativo.
A explicação visual é interativa. Você pode clicar em cada operador para ver os parâmetros definidos para esse operador pelo otimizador, conforme mostrado para alguns dos operadores abaixo.
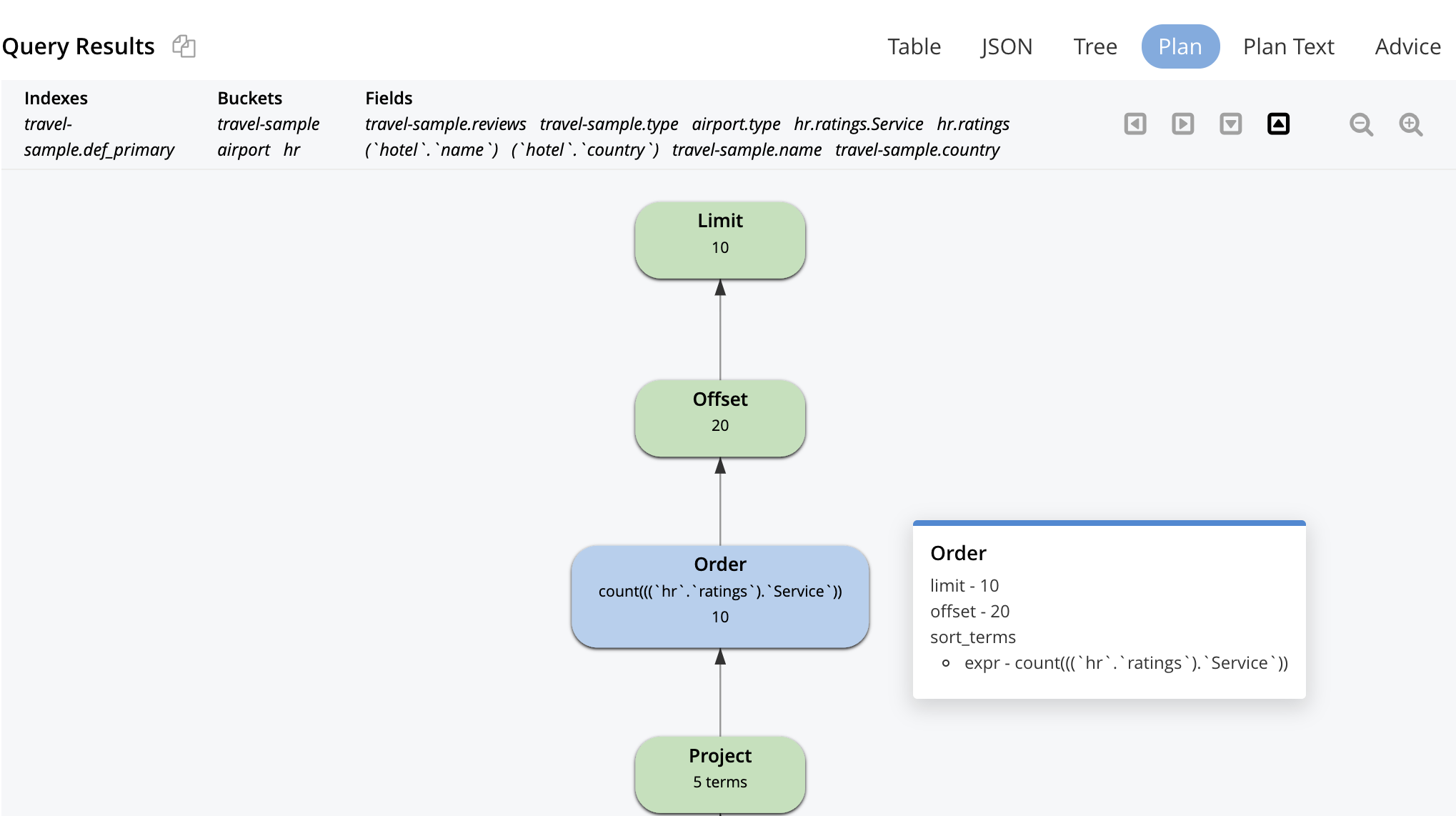
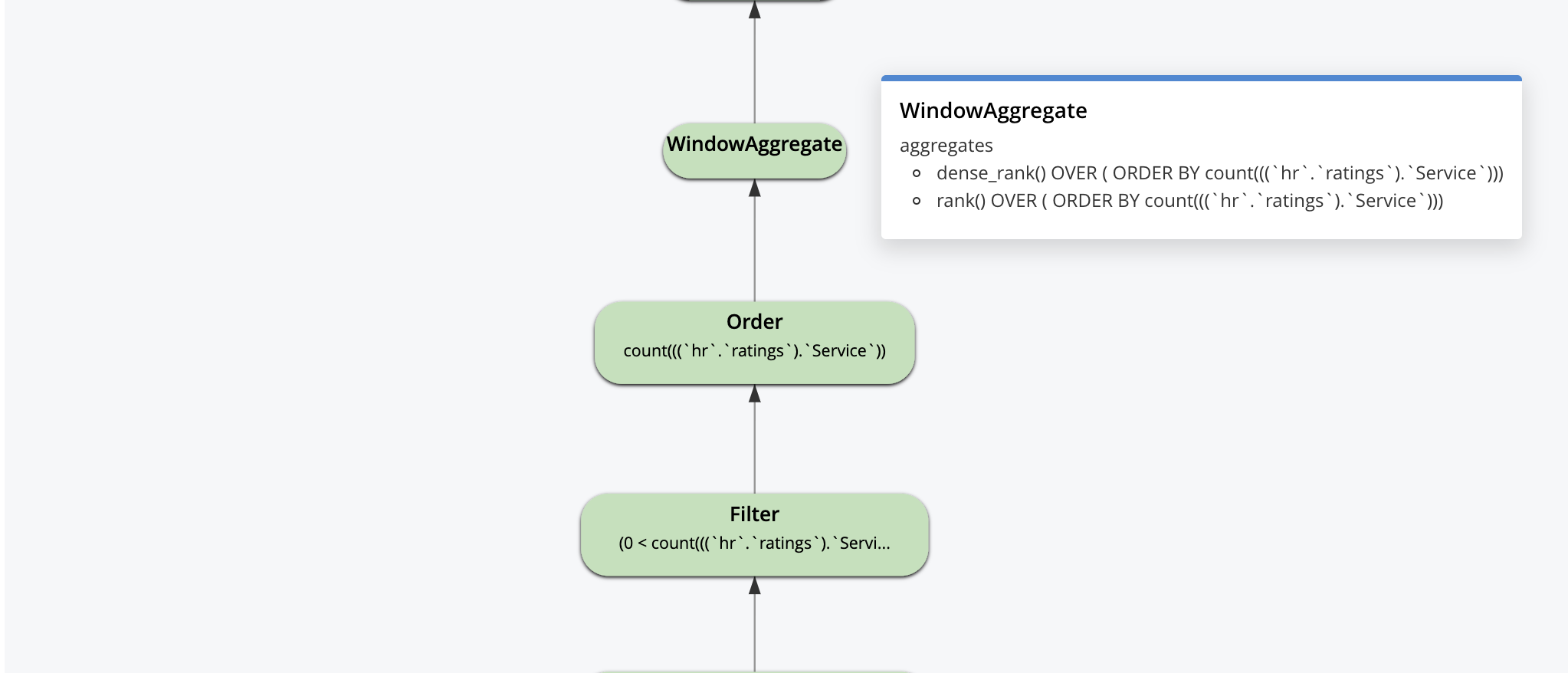
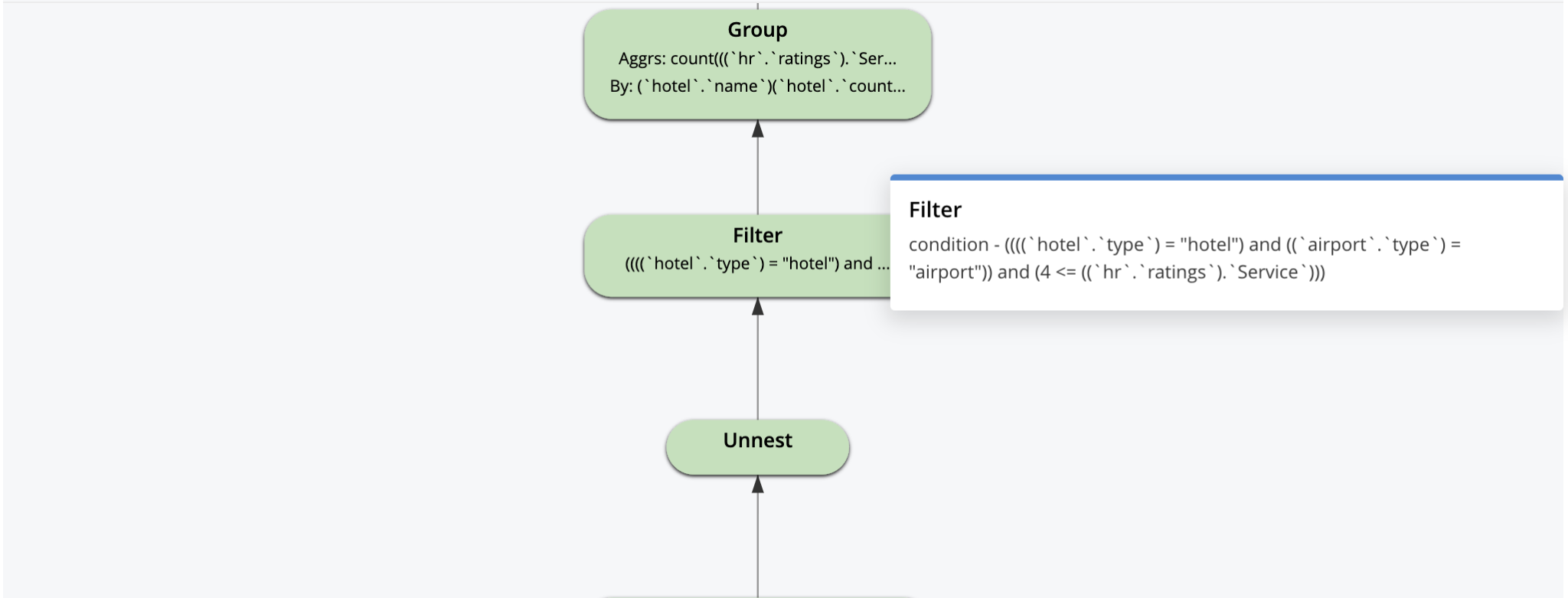
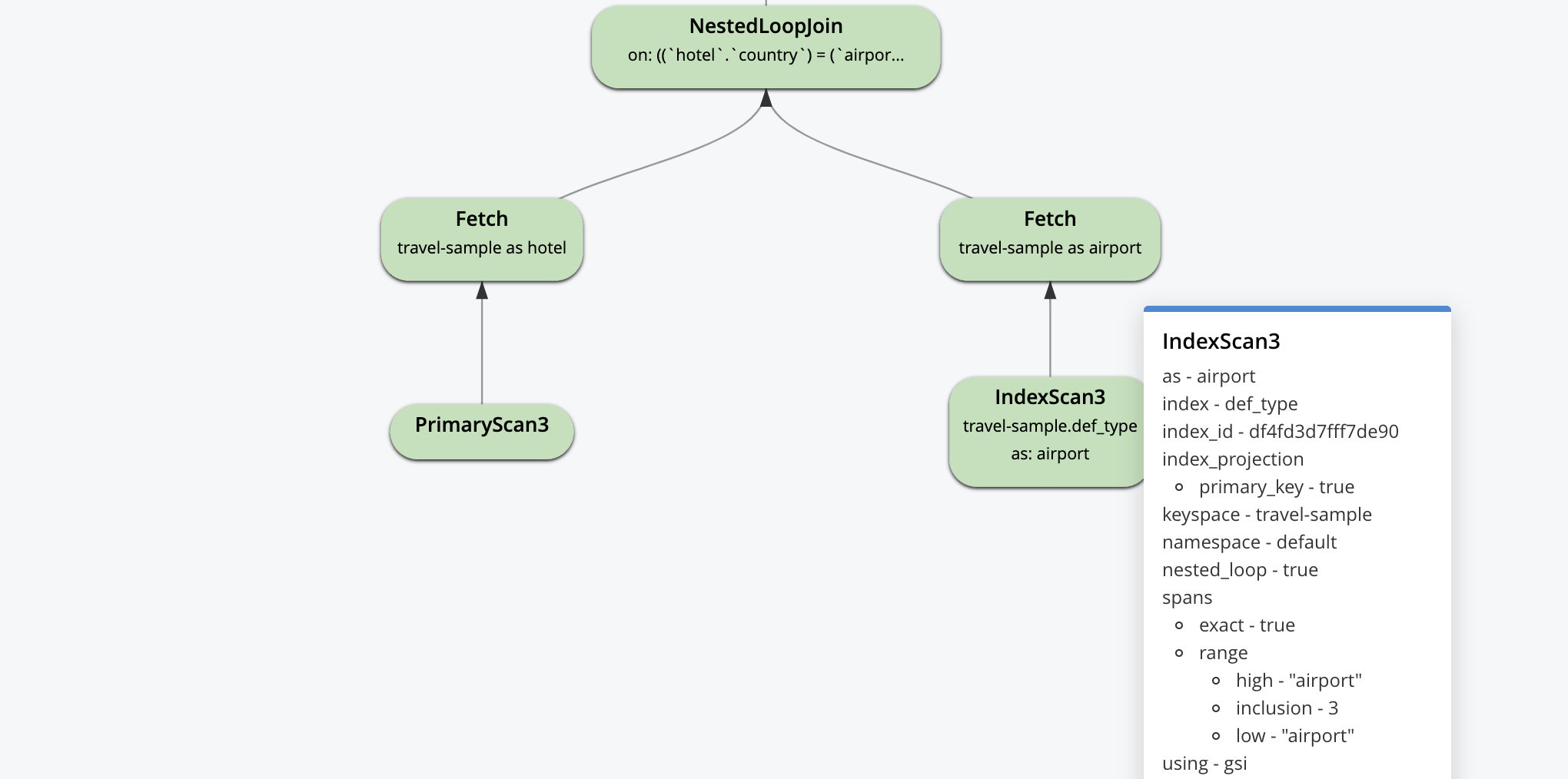
O plano de consulta começa com isso, logicamente. Todas as otimizações que se seguem a isso são pensadas por pessoas/ferramentas e selecionadas pelo otimizador para construir uma máquina de fluxo de dados para cada consulta. O objetivo do otimizador é criar máquinas que façam o mínimo de trabalho possível e ainda forneçam os resultados corretos.