Esta semana nosso Blog de redação comunitária A postagem vem de Nick Cadenhead

Nick Originalmente treinado como engenheiro de software, ele passou os últimos 15 anos usando seu conhecimento técnico para prestar serviços de consultoria especializada em contas importantes. Atualmente, é consultor sênior da 9ª Consultoria BITO Nick é responsável por dar suporte à equipe de vendas no desenvolvimento de novas contas e na promoção dos clientes e parceiros atuais, fornecendo suporte pré e pós-venda, incluindo serviços profissionais
As áreas de especialização de Nick são Integração de Middleware, Gerenciamento de Regras de Negócios e Business Intelligence (BI), especificamente centradas em apresentações e demonstrações, fornecimento de provas de conceitos e pilotos, além de suporte técnico. Ele gosta de construir relacionamentos estratégicos e usa seu amplo conhecimento técnico para ajudar os clientes a obter o máximo de seus investimentos. Há algum tempo, venho trabalhando com o Couchbase Banco de dados NoSQL e tem sido uma jornada interessante até agora.
Historicamente, não sou um cara de banco de dados, portanto, não trabalhei muito com bancos de dados em termos de projeto, criação e manutenção como um trabalho em tempo integral. No entanto, sei o básico. Esse cargo me permitiu entrar na "mentalidade" de Banco de dados NoSQL conceitos como ausência de estruturas, ausência de transações, desnormalização de dados e muito mais, sem ter muitas situações conflitantes com os paradigmas do mundo estruturado do SQL e dos bancos de dados relacionais.
Durante minhas atividades de engenharia de vendas, apoiando Couchbase (POC), sempre há um requisito para ingerir dados em um Balde do Couchbase (pense em um bucket como um banco de dados relacional) para demonstrar e destacar os recursos e as capacidades do Couchbase. Normalmente, a ingestão de dados exige que algum código seja escrito para ingerir dados no Couchbase. O Couchbase fornece alguns SDKs (Java, .Net, Node JS e outros) para que os desenvolvedores habilitem seus aplicativos a usar o Couchbase.
Então, isso me fez pensar. Por que não pode haver uma maneira ou ferramenta padrão para ingerir dados no Couchbase em vez de escrever código o tempo todo? Não me entenda mal. Não há nada de errado em escrever código!
Foi então que me deparei com o Streamsets.
Conjuntos de fluxo é uma plataforma de código aberto para a ingestão de dados de fluxo contínuo e em lote em armazenamentos de Big Data. Ela apresenta um console gráfico baseado na Web para configurar "pipes" de dados para lidar com fluxos de dados de origens a destinos, monitorar métricas de fluxo de dados em tempo de execução e automatizar o tratamento de desvios de dados.
Os pipes de dados são construídos no console baseado na Web por meio de um processo de arrastar e soltar. Os pipes se conectam às origens (fontes) e ingerem dados nos destinos (alvos). Entre as origens e os destinos estão as etapas do processador, que são essencialmente etapas de transformação de dados para mascarar campos, avaliar campos, procurar dados em um banco de dados ou em serviços de nuvem externos, como o Salesforce.com, fazer expressões em campos para rotear dados, avaliar/manipular dados usando JavaScript, Groovy e muito mais.
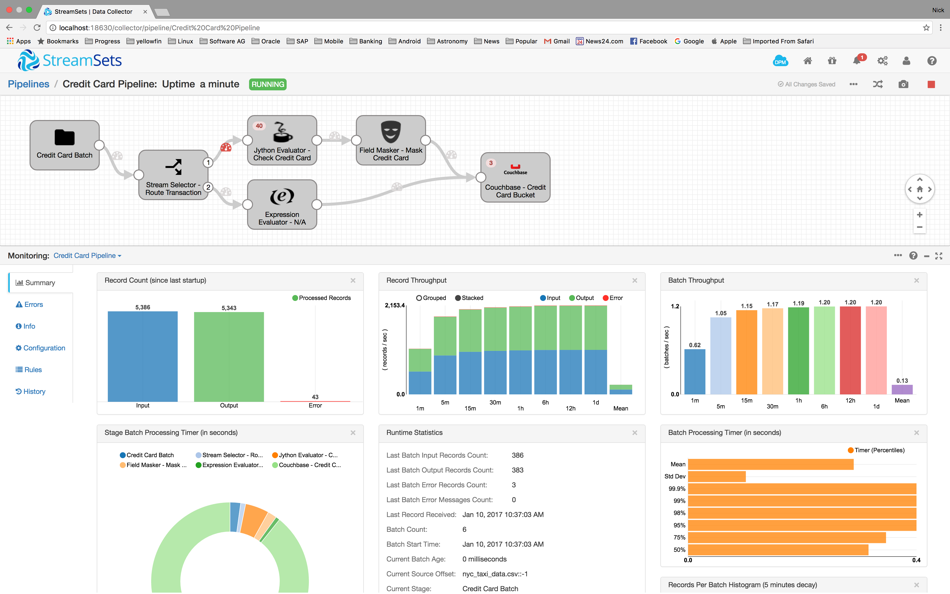
Figura 1: Um pipeline do Streamset ingerindo dados em um Bucket do Couchbase
Portanto, o Streamsets é uma ótima opção para minhas necessidades de ingestão de dados. Ele é de código aberto e está disponível para download imediato. Há um grande número de tecnologias compatíveis com a ingestão de dados, desde bancos de dados até arquivos simples, logs, serviços HTTP e plataformas de Big Data, como Hadoop, MongoDB e plataformas de nuvem, como Salesforce.com. Mas havia um problema. O Couchbase não está na lista de conectores de dados de tecnologia disponíveis para o Streamsets. Sem problemas! Decidi escrever meu próprio conector de dados para o Couchbase.
Aproveitando a API baseada em Java do Data Connector disponível para a comunidade aberta para ampliar os recursos de integração do Streamsets, juntamente com a documentação e os guias on-line, consegui implementar um conector de dados muito rapidamente para o Couchbase. A construção inicial do conector é muito simples; basta ingerir dados JSON em um Couchbase bucket. Com o tempo, o conector será expandido para consultar um bucket do Couchbase, com melhores recursos de ingestão e muito mais. Por enquanto, ele atende às minhas necessidades.
Um dos benefícios adicionais do Streamsets é a análise do pipeline de dados. Os recursos de análise no console do Streamsets oferecem aos usuários uma visão de como os dados estão fluindo das origens para os destinos. As visualizações padrão no console do Streamsets fornecem análises detalhadas sobre o desempenho do pipeline de dados. A análise do pipeline me mostrou rapidamente como meus dados estavam sendo ingeridos nos Buckets do Couchbase e destacou todos os erros que ocorreram ao longo dos estágios do pipeline de dados. Portanto, ao usar pipelines de dados no Streamsets, eles me permitem ingerir dados muito rapidamente no Couchbase sem escrever muito ou nenhum código.
O conector de dados está aberto e pode ser encontrado no seguinte endereço Link do Git Hub: