Para que o servidor Couchbase seja executado em seu PC ou Mac, são necessárias algumas etapas simples para fazer o download do software e criar um cluster com todos os serviços do Couchbase de que você precisa (https://docs.couchbase.com/server/6.0/getting-started/start-here.html). Os baldes de amostra estão disponíveis com o software para que você comece a usar o produto em questão de minutos.
Se você precisar migrar seu banco de dados relacional para o Couchbase, há conectores disponíveis (https://docs.couchbase.com/server/6.0/connectors/intro.html) que permitiria que você atingisse o objetivo. No entanto, se você estiver familiarizado com as ferramentas de banco de dados RDBMS e Couchbase, poderá aproveitar a ferramenta de exportação de dados do seu banco de dados e usar o Couchbase cbimport para carregar os dados em um bucket do Couchbase.
Com qualquer uma das abordagens, você ainda precisará tomar algumas decisões, devido às diferenças entre os bancos de dados:
- Tabelas RDBMS vs. buckets do Couchbase.
- Chaves primárias de banco de dados e chaves de documento de bucket.
- Por último, mas não menos importante, como transformar seu esquema de banco de dados relacional em um banco de dados de documentos JSON do Couchbase.
Neste blog, discutirei essas diferenças e descreverei as diferentes estratégias que você pode considerar para transformar o esquema do seu banco de dados relacional no banco de dados NoSQL do Couchbase. Embora a técnica de migração possa ser generalizada para muitos RDBMS, o processo real de consulta ao banco de dados de origem utiliza suas APIs REST específicas. Por esse motivo, usarei o Oracle e seu esquema de RH de amostra como dados de origem e aproveitarei seus serviços de dados REST para a extração de dados.
De quais ferramentas você precisa
As técnicas de migração deste blog aproveitam os serviços básicos do banco de dados Oracle e a linguagem de consulta N1QL do Couchbase. Você não precisa de mais nada.
Como usar essas técnicas de migração
Os scripts N1QL fornecidos abordam os dois primeiros problemas de tipo de documento e chave de documento. Para a transformação do esquema relacional no banco de dados JSON do Couchbase, os scripts abrangem esses três cenários:
- Mapeamento direto da tabela para o tipo de documento. Nenhuma transformação está envolvida.
- Desnormalização do objeto pai em objeto filho.
- Desnormalização de objetos filhos no pai como um campo de matriz.
Os cenários acima, com as soluções de tipo de documento e chave de documento, devem abranger a maioria dos casos de uso para transformar um esquema relacional em um banco de dados de documentos JSON.
Os pré-requisitos
- Acesso a um servidor de banco de dados Oracle com o esquema de amostra HR.
- Acesso a um banco de dados Couchbase, onde você precisa criar um bucket cbhr como o destino da migração do esquema Oracle HR.
As etapas
- Habilite seu esquema Oracle para acesso aos serviços de dados REST.
- Configure um servidor Couchbase e configure o bucket para receber os dados do Oracle HR.
- Decida sobre as técnicas de transformação do modelo de dados para seus requisitos de migração.
- Edite e execute o script N1QL para migrar os dados.
Banco de dados Oracle com o esquema de RH
O esquema Oracle HR está disponível em sua instalação Oracle. Siga a documentação da Oracle para implementar o esquema. https://docs.oracle.com/cd/E11882_01/server.112/e10831/installation.htm#COMSC001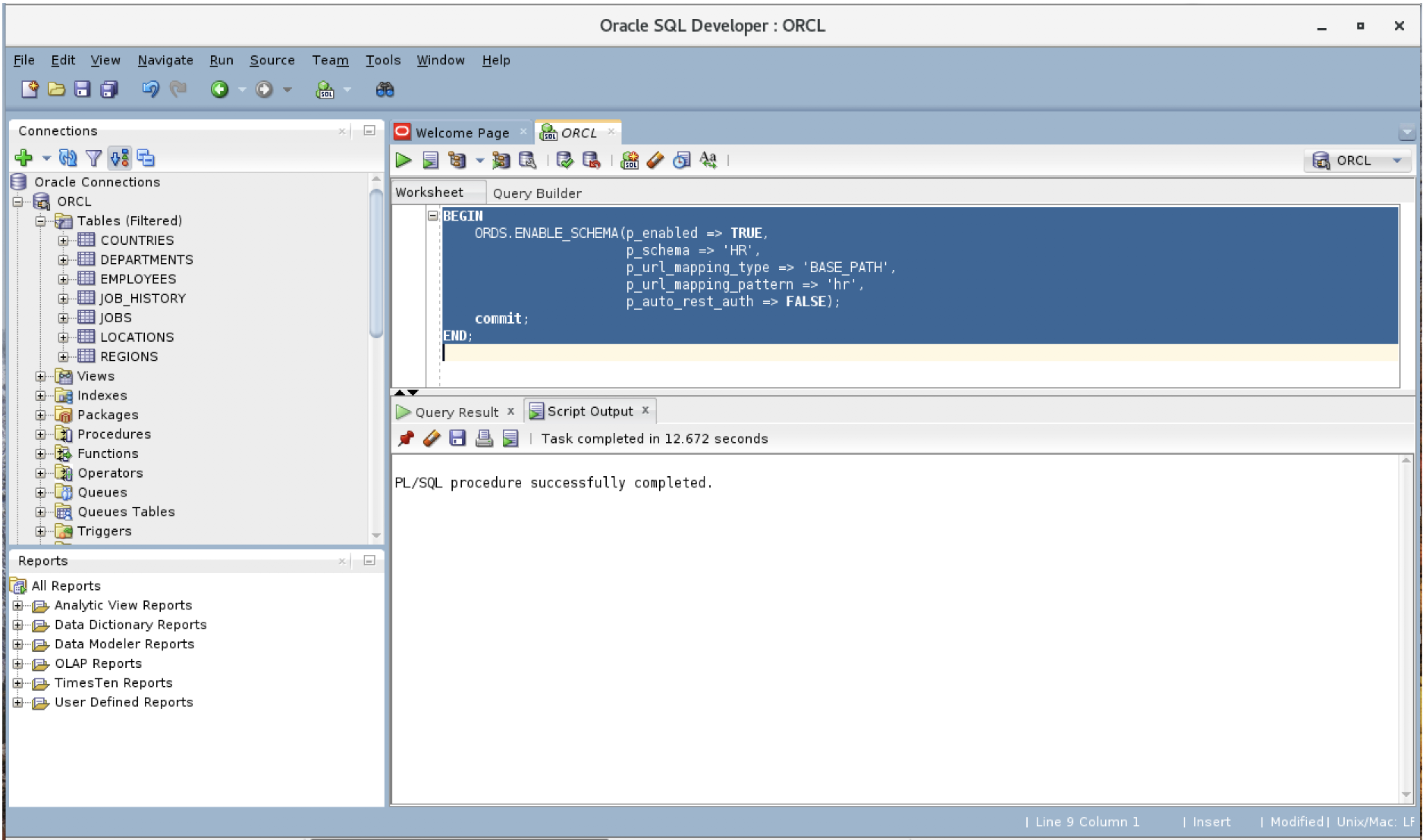
Habilitar o esquema Oracle para serviços REST
Por padrão, o serviço de dados Oracle REST não está ativado no esquema. Você precisará ativá-lo para o esquema HR.
Faça login como o usuário que emitirá as chamadas REST. Para este exemplo, faça login como hre execute o script a seguir.
|
1 2 3 4 5 6 7 8 |
BEGIN ORDS.ENABLE_SCHEMA( p_enabled => TRUE , p_schema => 'HR' , p_url_mapping_type => 'BASE_PATH' , p_url_mapping_pattern => 'hr' , p_auto_rest_auth => FALSE); commit; END; |
Referência: https://blogs.oracle.com/oraclemagazine/get-your-rest-post-your-sql
Verifique se você pode consultar seu Oracle com uma chamada REST. https://:8080/ords/hrrest/employees/
Observação: Por padrão, o serviço Oracle REST Enabled SQL está desativado. Para definir as configurações do serviço REST Enabled SQL, consulte Configuração das definições do serviço SQL habilitado para REST.
Prepare seu servidor Couchbase
Há duas etapas que você precisa concluir na configuração do servidor Couchbase.
- Criar um bucket com o nome
cbhr. O tamanho do bucket dependerá do volume dos dados que você planeja migrar. - Verifique se você ativou o acesso à função CURL() na configuração do servidor Couchbase.

3. Você também precisará criar um índice primário no cbhr para permitir que o N1QL consulte o bucket como parte da migração.
|
1 |
CREATE PRIMARY INDEX `#primary` ON `cbhr` |
Transformação do modelo de dados
A migração do banco de dados relacional para o NoSQL é um grande passo, e este blog não aborda os prós e os contras de cada um desses bancos de dados. No entanto, devido às diferenças na forma como os dados são armazenados, você precisará tomar uma decisão sobre como deseja gerenciar essas alterações. Os scripts N1QL deste blog transformarão o esquema Oracle HR no seguinte modelo de dados JSON do Couchbase, usando as seguintes estratégias:
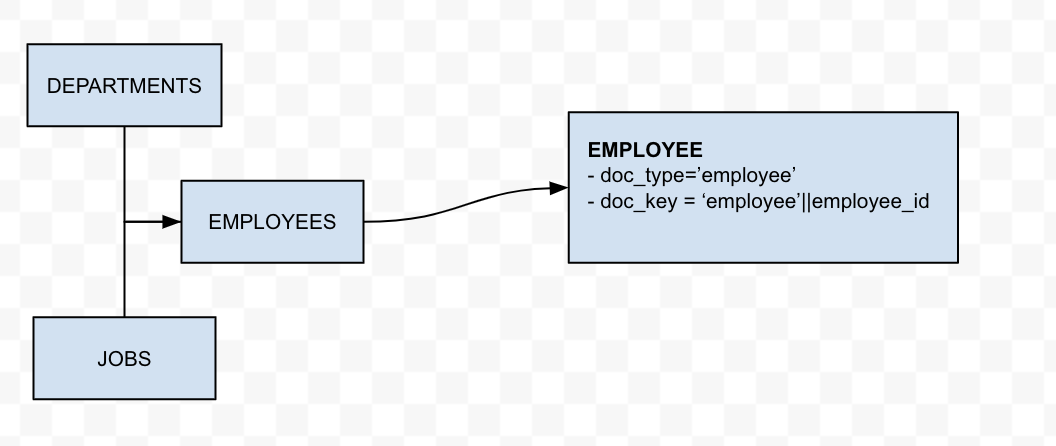
- Regiões, países, locais são entidades pai diretas e indiretas de departamentos. Portanto, poderíamos desnormalizar o pai/avô/bisavô na entidade Department. Isso reduzirá a necessidade de JOINs quando essas informações forem necessárias na consulta. Além disso, outras entidades associadas, como Employees e Job_History, têm apenas uma referência ao department_id. Por esse motivo, faria sentido desnormalizar as informações sobre a região, o país e a localização de um departamento em um objeto "department" no modelo JSON do Couchbase.
- A entidade Jobs inclui as informações sobre a escala de pagamento. Esses dados podem ser confidenciais. Por esse motivo, usaremos uma migração direta desse objeto sem nenhuma transformação.
- A entidade Employees inclui outras informações associadas, como job_id e department_id, que são atributos importantes para um funcionário. Faria sentido desnormalizar o título do cargo e o nome do departamento no objeto "employee".
- A entidade Job_History é, na verdade, um objeto filho da entidade Employees. Portanto, faria sentido incluir o histórico de trabalho do funcionário no objeto 'employee'.
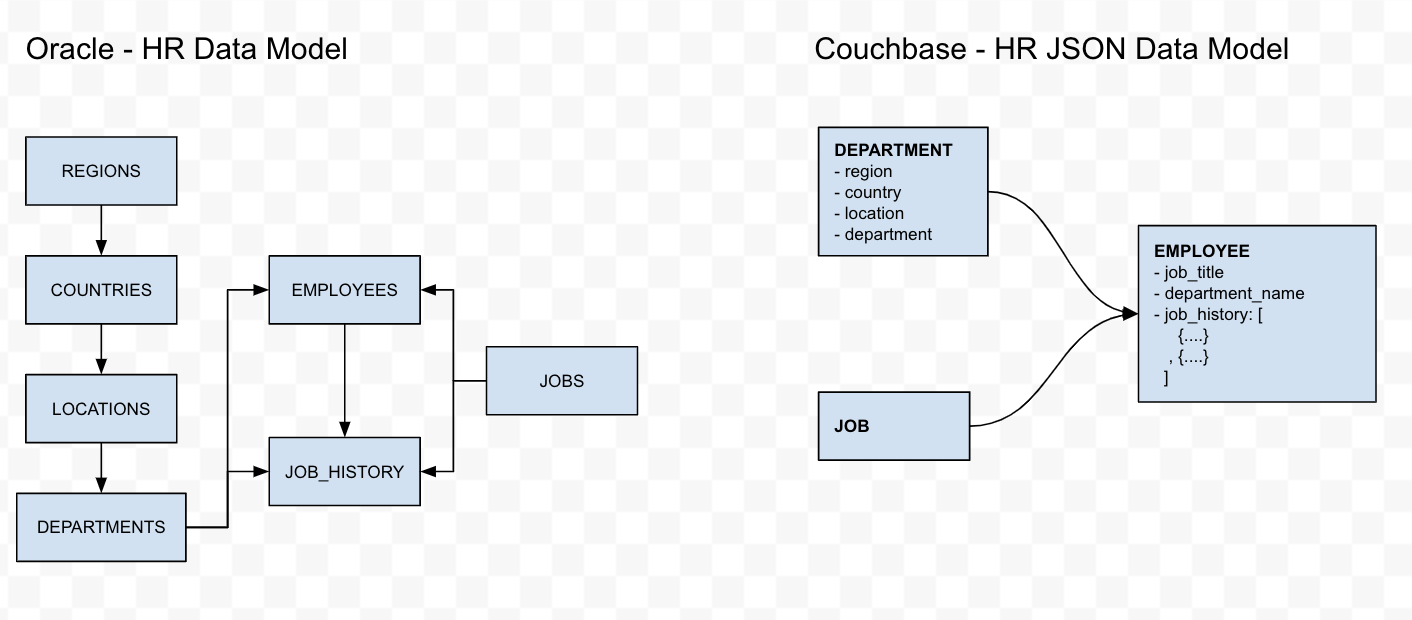
Tabela versus tipo de documento
No Couchbase, o conceito de tabela não se aplica. Todos os documentos podem ser armazenados em um único bucket com o uso de um tipo para diferenciar o tipo de documento. Isso é possível porque não há restrição de esquema entre documentos diferentes no banco de dados NoSQL do Couchbase.
O script incluído cuida disso ao incluir um tipo de documento com o valor do nome da tabela de origem.
|
1 |
SELECT 'employee' doc_type ... FROM hr.employees... |
Mapeamento da chave primária
Uma tabela Oracle normalmente tem uma chave primária, e você pode ver isso no esquema de RH. Os documentos do Couchbase também precisam de uma chave primária. No entanto, como todos os dados da tabela Oracle residirão em um único bucket do Couchbase, precisamos de uma maneira de diferenciar os valores-chave desses tipos de documentos no Couchbase.
O script incluído cuida disso construindo o chave_documento usando o nome da tabela Oracle HR e seu valor de chave primária.
|
1 |
SELECT 'employee:' ||e.employee_id doc_key FROM hr.employees ... |
Documento JSON relacional para o Couchbase
Não existe uma regra rígida e rápida sobre como você deve transformar seu esquema relacional em NoSQL. Você poderia migrar todas as tabelas para um bucket do Couchbase, cada uma com seu próprio tipo de documento campo.
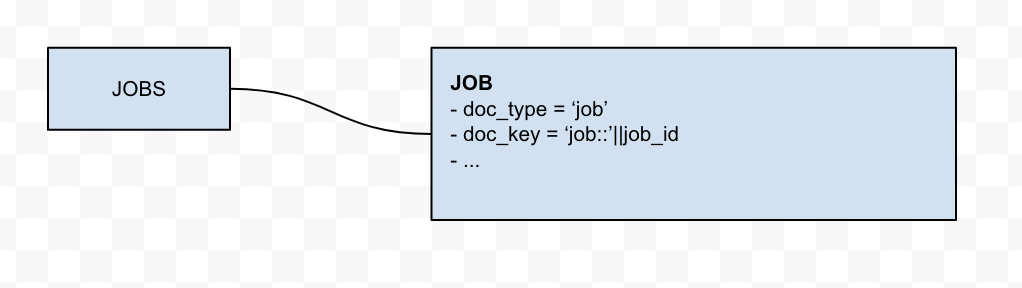
Tabela direta para o documento
Esse é o caso mais simples, em que apenas o tipo de documento e chave_documento são adicionados ao documento do Couchbase. O objeto relacional não requer nenhuma transformação durante o processo de migração.
|
1 2 3 4 5 6 7 8 9 |
UPSERT INTO cbhr (key ndoc.doc_key,value ndoc) SELECT ndoc.doc_key, ndoc FROM CURL("https://<your_server_ip>:8080/ords/hr/_/sql", { "request":"POST","header":"Content-Type: application/sql" , "data":"SELECT 'job' doc_type, 'job:'||j.job_id doc_key, j.* FROM jobs j" , "user":'HR:oracle'} ) r UNNEST r.items[0].resultSet.items as ndoc |
Observações:
- O UPSERT é usado para que a consulta possa ser executada novamente sem afetar o resultado no bucket do Couchbase.
- O comando N1QL CURL chama um ponto de extremidade REST no Oracle Rest Data Services, com uma consulta a ser processada pelo servidor Oracle.
- O N1QL CURL retorna um documento JSON com o resultado da consulta definido no campo de matriz r.items[0].resultSet.items.
- A consulta N1QL usa o comando UNNEST para achatar o r.items[0].resultSet.items retornando cada registro Oracle como um documento JSON separado.
- O N1QL UPSERT insere cada documento no Couchbase cbhr balde.
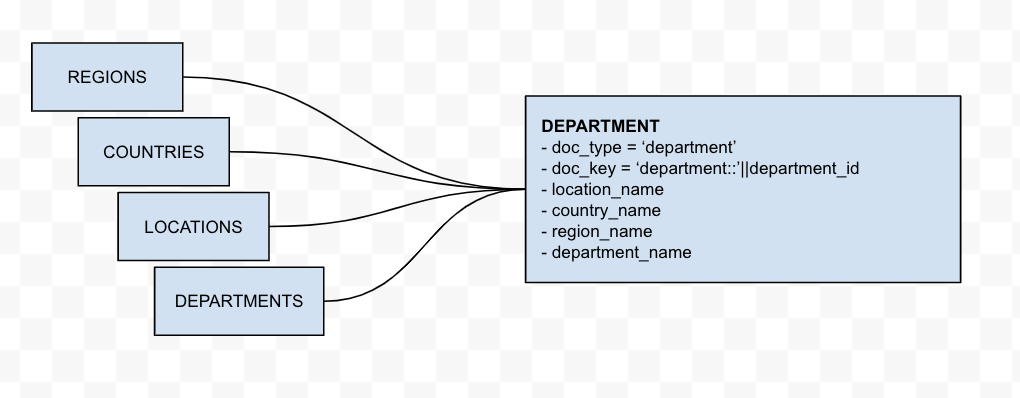
Desnormalização
Essa transformação combina várias tabelas Oracle em um único objeto. Neste exemplo, as tabelas Regions (Regiões), Countries (Países) e Locations (Localizações) têm um relacionamento direto pai-filho, o que permite que os campos pai sejam adicionados ao objeto filho. O resultado final é um único objeto Department que inclui sua localização, país e região. Essa transformação é um processo de etapa única.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
UPSERT INTO cbhr (KEY doc_key, VALUE ndoc) SELECT ndoc.doc_key , ndoc FROM CURL( "<your_database_server_ip>:8080/ords/hr/_/sql" , { "request":"POST","header":"Content-Type: application/sql" , "data": "SELECT 'department' doc_type, 'department:' ||d.department_id doc_key, d.department_id, d.department_name, d.manager_id , l.* , c.country_name, r.* FROM departments d INNER JOIN locations l ON d.location_id=l.location_id INNER JOIN countries c ON l.country_id = c.country_id INNER JOIN REGIONS r ON c.region_id = r.region_id" ,"user":'HR:oracle'} ) res UNNEST res.items[0].resultSet.items as ndoc |
Observações:
- O UPSERT é usado para que a consulta possa ser executada novamente sem afetar o resultado no bucket do Couchbase.
- O comando N1QL CURL chama um ponto de extremidade REST no Oracle Rest Data Services, com uma consulta a ser processada pelo servidor Oracle.
- O N1QL CURL retorna um documento JSON com o resultado da consulta definido no campo de matriz r.items[0].resultSet.items.
- A consulta N1QL usa o comando UNNEST para achatar o r.items[0].resultSet.items retornando cada registro Oracle como um documento JSON separado.
- O N1QL UPSERT insere cada documento no Couchbase cbhr balde.
Desnormalização - Adicionar registros filhos como um campo de matriz ao objeto pai
Um dos principais recursos de um banco de dados NoSQL é o uso de matrizes. O banco de dados NoSQL do Couchbase armazena documentos no formato JSON, no qual um campo pode ser uma matriz. Para este exercício, adicionaremos a tabela JOB_HISTORY à tabela principal EMPLOYEES. Isso adiciona efetivamente uma nova tabela histórico de trabalho para o documento EMPLOYEE.
Essa transformação é uma processo em duas etapas. A primeira etapa é a migração dos dados dos funcionários. A segunda etapa mescla os funcionário que já estão no Couchbase cbhr com a consulta Oracle de histórico de trabalho.
O documento pai
|
1 2 3 4 5 6 7 8 9 10 11 |
UPSERT INTO cbhr (key ndoc.doc_key,value ndoc) SELECT ndoc.doc_key, ndoc FROM CURL("https://192.168.1.117:8080/ords/hr/_/sql", { "request":"POST","header":"Content-Type: application/sql" , "data":"SELECT 'employee' doc_type, 'employee:' ||e.employee_id doc_key, e.* , j.job_title, d.department_name FROM employees e INNER JOIN jobs j ON e.job_id = j.job_id INNER JOIN departments d ON e.department_id = d.department_id" , "user":'HR:oracle' }) r UNNEST r.items[0].resultSet.items as ndoc |
Os registros filhos como um campo de matriz no documento pai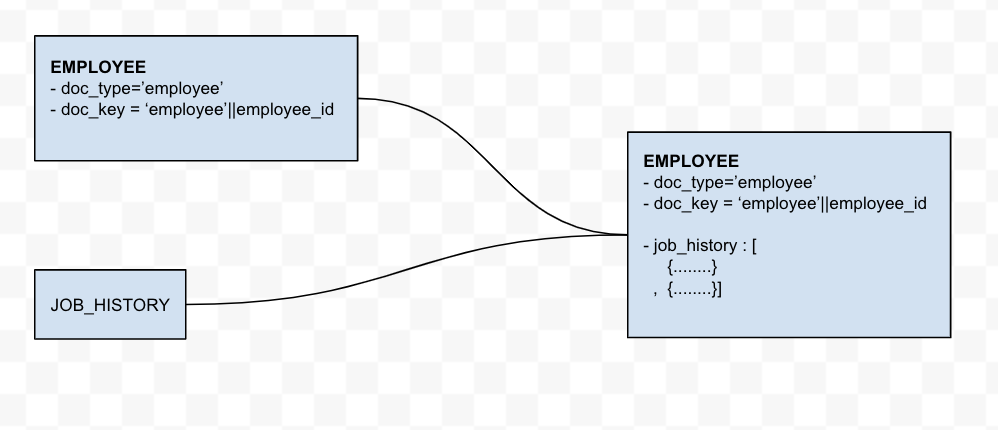
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
MERGE INTO cbhr e USING ( SELECT ndoc.employee_id, ARRAY_AGG(ndoc) all_jobs FROM CURL( "https://<your_database_server>:8080/ords/hr/_/sql" , {"request":"POST","header":"Content-Type: application/sql" , "data": "SELECT h.employee_id, h.start_date,h.end_date, h.job_id, j.job_title, h.department_id FROM job_history h INNER JOIN jobs j ON h.job_id=j.job_id" , "user":'HR:oracle' } ) res UNNEST res.items[0].resultSet.items as ndoc GROUP BY ndoc.employee_id ) source ON KEY 'employee:'||to_string(source.employee_id) WHEN MATCHED THEN UPDATE SET e.job_history = source.all_jobs |
Observações:
- A consulta N1QL usa o comando MERGE para combinar documentos do cbhr balde cujo tipo de documento é funcionário com o resultado do SELECT da leitura CURL REST do Oracle histórico de trabalho.
- A consulta usa o N1QL ARRAY_AGG para agrupar todos os trabalhos por ID do funcionário.
- O MERGE usa 'employee:'||to_string(source.employee_id) como a chave para combinar os dois conjuntos de resultados.
Limitações
Observe que há uma limitação da quantidade de dados que o N1QL CURL() pode recuperar. Atualmente, o tamanho máximo está definido em 64 MB, que não pode ser modificado. Isso não é muito se você planeja migrar grandes tabelas Oracle. Dito isso, o Oracle tem suporte para OFFSET e FETCH NEXT, o que permitiria dividir o processo de migração em partes menores.
Além disso, os principais motivos deste blog são destacar o que você precisa considerar ao migrar um esquema relacional para um banco de dados de documentos JSON do Couchbase e como o N1QL pode ajudar a transformar seu esquema relacional diretamente no processo de migração.
Se tiver dúvidas ou comentários, deixe um comentário abaixo.
Olá, Binh, isso é bom e muito útil, mas, conhecendo as limitações do CURL em termos de dimensionamento, eu gostaria de saber como lidar com um grande volume de tarefas de migração de dados como carregamento em lote do Oracle para o Couchbase quando existem 10 junções diferentes no modelo OLAP. Por favor, compartilhe suas ideias sobre isso. Estou tentando replicar o processo de uso do Oracle ORDS, mas com OFFSET e FETCH, mas não tenho certeza de como lidar com isso.
agradecimentos
Debashis,
Obrigado por seu interesse no blog. Para aproveitar a cláusula Oracle "OFFSET and FETCH {FIRST |NEXT} ...", você deve usar uma linguagem de script, ou seja, Python e o Couchbase SDK. Aqui, você iterará pelo conjunto de registros do Oracle. Consulte esta postagem no fórum https://www.couchbase.com/forums/t/oracle-to-couchbase/22044 para obter sugestões sobre como isso poderia ser feito de forma programática.
Obrigado,
-binh