Sem dúvida, o método mais popular de extração, transformação e carregamento (ETL) é o uso do Kafka. A configuração do Kafka para ETL, pipelining de dados ou streaming de eventos pode ser um desafio, mas existem ferramentas melhores.
A Confluent oferece a distribuição mais completa do Kafka, aprimorando-o com recursos adicionais da comunidade e comerciais projetados para melhorar a experiência de streaming de operadores e desenvolvedores na produção e em grande escala. O Couchbase, como uma plataforma de dados altamente disponível, distribuída e altamente dimensionável, e o Confluent parecem uma combinação perfeita. Mas como você move os dados para dentro e para fora do Couchbase por meio do Confluent?
O Couchbase oferece suporte a um conector de fonte/sink do Kafka/Confluent que pode ser gerenciado no Confluent Control Panel.
Ativar o conector do Couchbase Sink
A adição do conector do Couchbase pode ser realizada de várias maneiras a partir de uma instalação local do Confluent, bem como do download do Confluent Hub. See o documentação para instalação e configuração dos links de conectores.
Depois que o conector é adicionado no Painel de controle do Confluent, o Conectar deve ter a seguinte aparência:
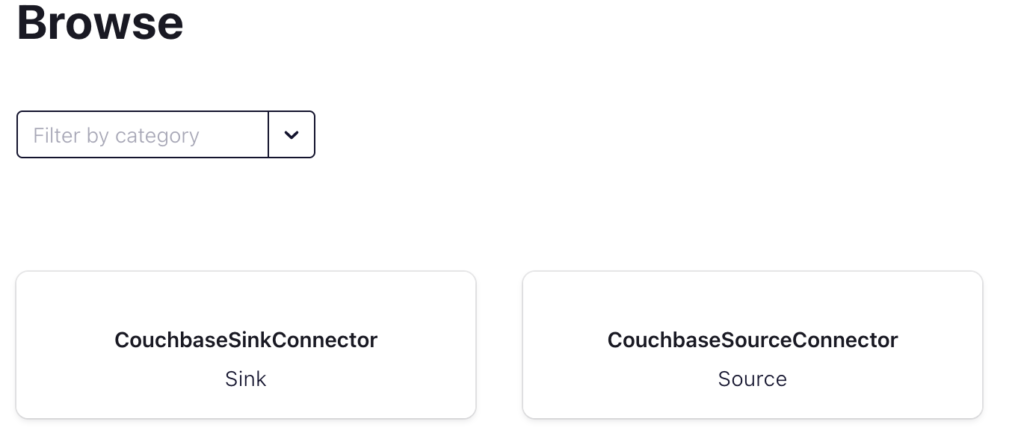
Confluent Connect com o conector de fonte e coletor do Couchbase
Clicando em CouchbaseSinkConnector exibe a seguinte caixa de diálogo:
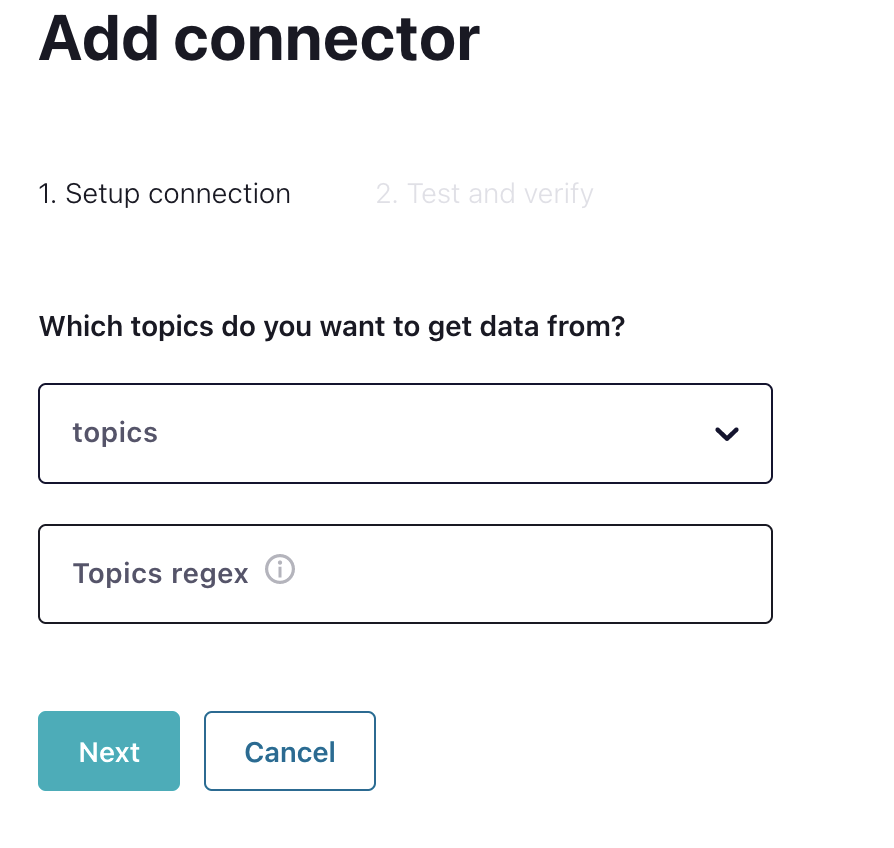
A seleção do tópico configurado no Confluent preencherá todos os campos para configurar o conector. Os campos são específicos do Couchbase para mapear tópicos para o Couchbase. Basicamente, o Couchbase armazena dados em buckets, escopos e coleções.
Definição de tópico para fluxo
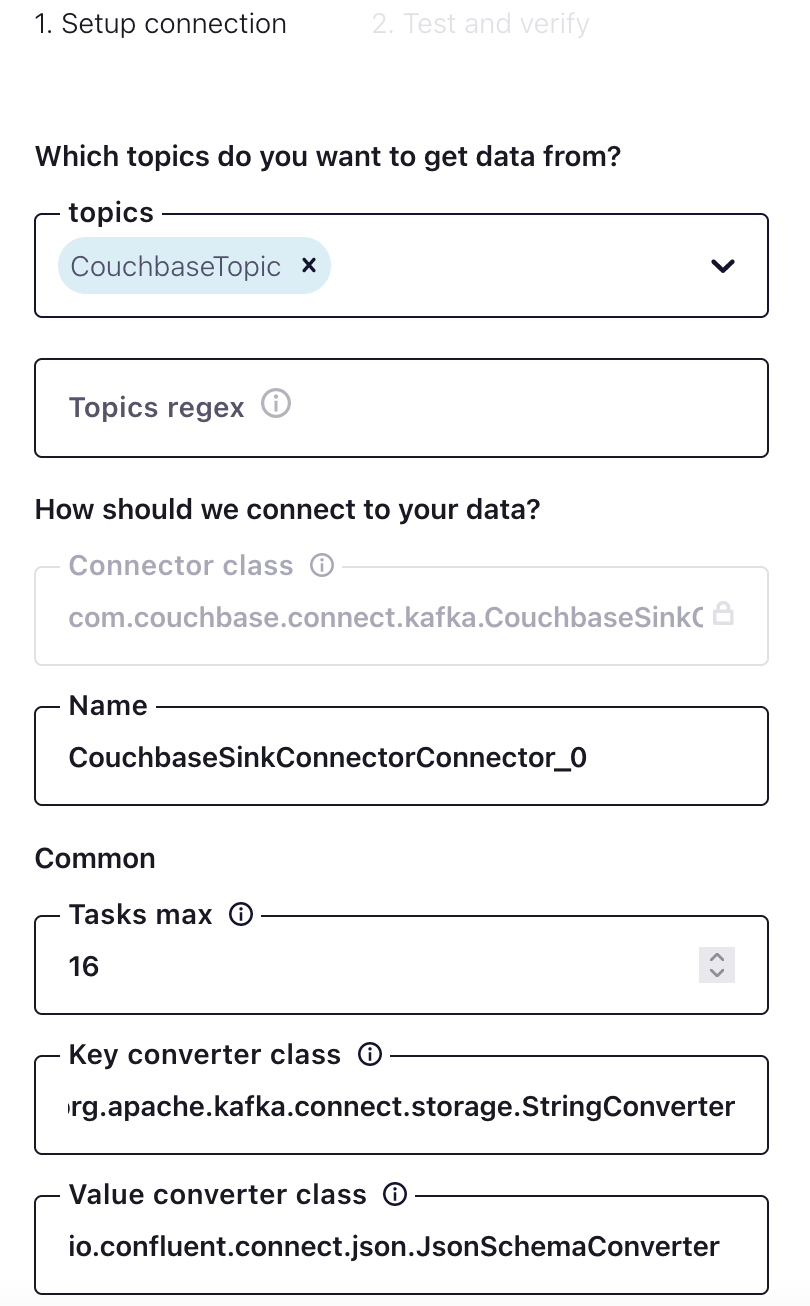
CouchbaseTopic foi criado no Confluent com 16 partições. Na seção Comum seção para Máximo de tarefasSe o conector for um conector, é possível pensar neles como threads para o conector, por exemplo, 16 tarefas. Nesse caso, há um mapeamento de um para um entre as partições e as tarefas para obter alto desempenho. Esse valor não é um requisito, por exemplo, pode haver 16 partições e 32 tarefas, mas tenha em mente os recursos do computador de hospedagem.
Seleção de um bucket do Couchbase como sink
A próxima etapa é a conexão com o Couchbase, que é simples.
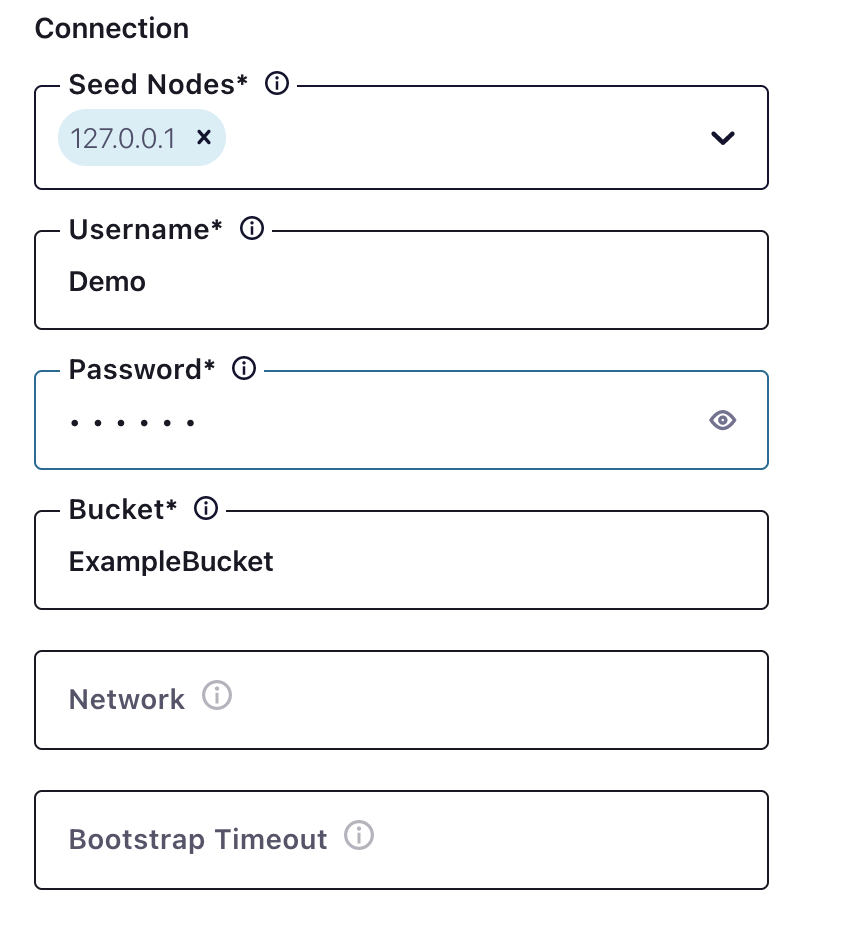
Nesse caso, o nó inicial é localhost, mas pode ser um nome de host ou um IP.
Lembre-se - o usuário do bucket deve ter direitos de acesso no Couchbase para o bucket, os escopos e as coleções!
Depois de configurar a conexão, vamos examinar os escopos e as coleções.
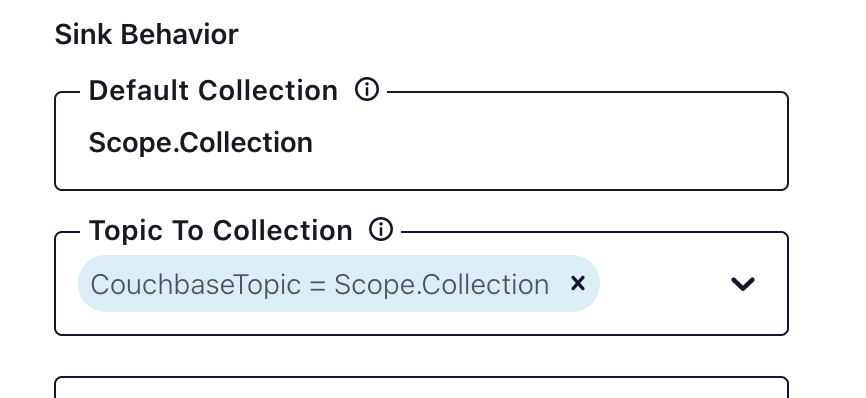
Acima está um exemplo de como configurar escopos e coleções. É importante garantir que o escopo e a coleção existam no Couchbase com as permissões adequadas.
Ao criar os tópicos no Confluent, considere a balde->escopo->coleção mapeamento - cada tópico será mapeado para um escopo/coleção. Se houver mais de um escopo e uma coleção sendo mapeados, será necessário criar tópicos específicos para o mapeamento.
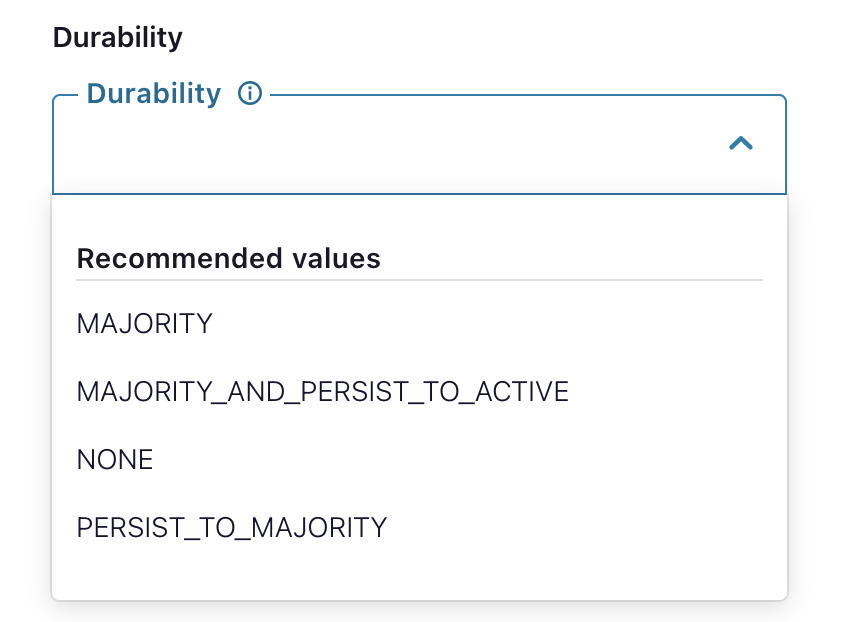
Configurações específicas de durabilidade do Couchbase
As gravações duráveis podem ser configuradas para o conector do Couchbase, conforme descrito abaixo:
O Conector Couchbase pode ser configurado para vários tipos de dados de serialização e desserialização, como JSON simples ou binário AVRO. Vamos dar uma olhada na compactação binária AVRO.
A compactação AVRO é uma compactação binária que pode ser desserializada em JSON usando um esquema. Esse esquema mapeia o binário para uma estrutura JSON. O conector do Couchbase pode desserializar com um esquema que está configurado no Confluent. O Confluent fará a serialização e a desserialização e, em seguida, o tópico será preenchido com a saída da serialização. O Confluent pode suportar um esquema nativamente por meio do Control Center. Se houver várias etapas na serialização, será necessário criar um registro de esquema para armazenar os esquemas e as etapas ordenadas nas quais os esquemas devem ser usados.
Por fim, o conector é configurado.
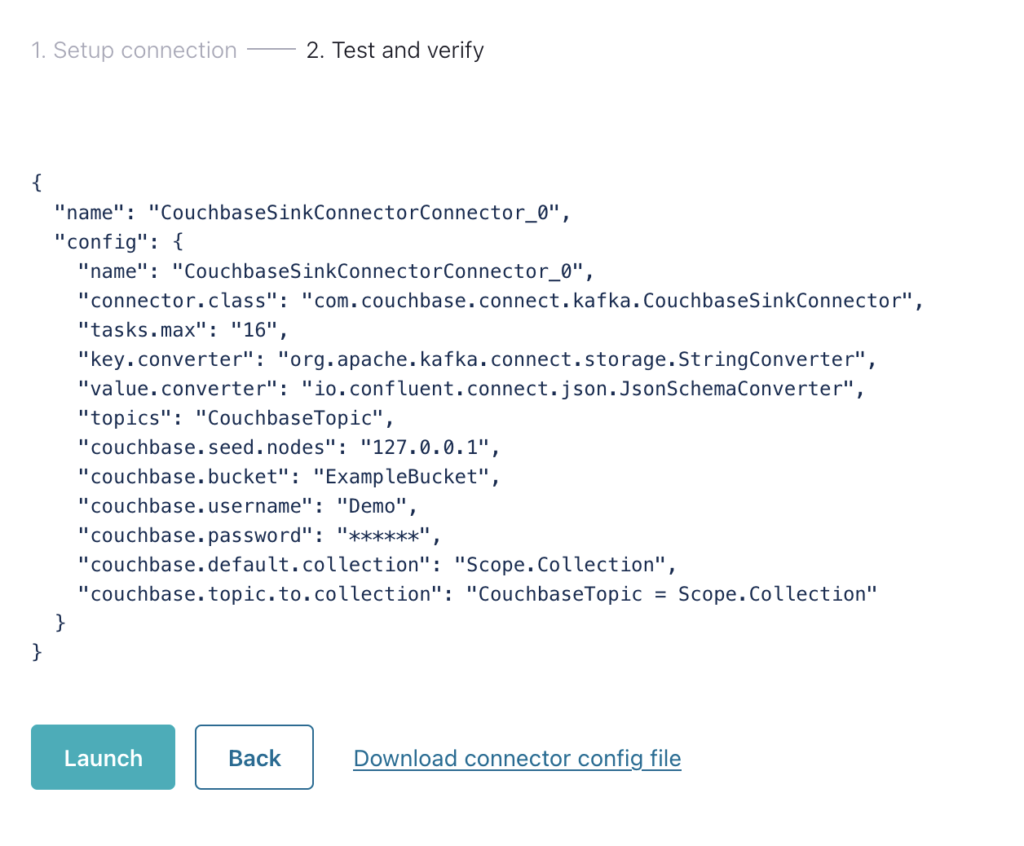
Se vários conectores precisarem ser configurados (como tópicos diferentes para escopos e coleções diferentes), o arquivo de configuração poderá ser baixado e adicionado ao cluster predefinido.
O conector Kafka do Couchbase com o Confluent é um caminho fácil para ETL e streaming de dados de e para o Couchbase. O conector de origem é mais fácil de configurar, pois é apenas a mesma configuração de conexão, mas um mapeamento de bucket -> escopo -> coleção para um tópico do Kafka.
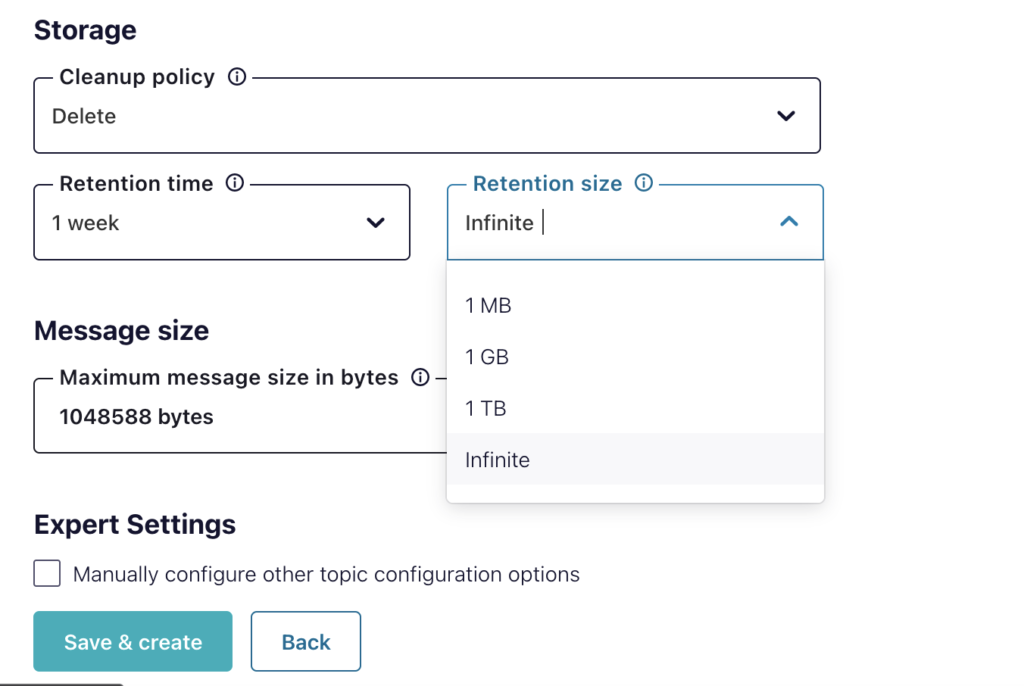
Depois que o conector estiver em funcionamento, ele coletará as mensagens na fila de tópicos e as migrará automaticamente para o Couchbase à medida que forem chegando. Cada tarefa pegará a mensagem mais recente na fila e a removerá dela; não há necessidade de gerenciar a fila além do tempo em que as mensagens são salvas na fila, conforme mostrado abaixo:
Próximas etapas e recursos
-
- Início rápido do conector Kafka do Couchbase
- Repositório GIT de exemplos do Kafka/Couchbasecom mergulhos profundos na integração do SQL++, bem como em personalizações.
- Conector Confluent Couchbasechbase/kafka-connect-couchbase
- Integração de dados do Couchbase Capella com o Confluent Cloud (Vídeo abaixo)
