Esta postagem teve a coautoria de Karen Yuan, um estagiário de ensino médio.
A ciência de dados extrai conhecimento dos dados e aplica esse conhecimento para resolver problemas. Nas próximas duas postagens, aprenderemos como a Couchbase Data Platform pode atender a várias necessidades da ciência de dados e simplificar e reduzir o número de ferramentas necessárias durante o processo.
Visão geral
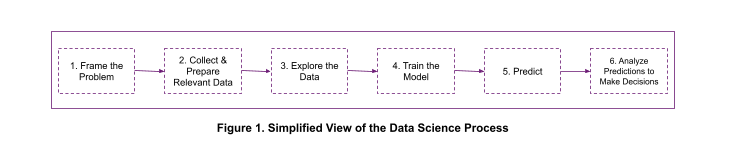
Os fluxos de trabalho da ciência de dados envolvem várias etapas, conforme mostrado na Figura 1. Os cientistas de dados são forçados a usar diferentes ferramentas para diferentes etapas, complicando o processo e tornando-o menos eficiente.
Por exemplo, os cientistas de dados realizam análise exploratória de dados para determinar quais atributos nos dados de treinamento são importantes para seu caso de uso. Para fazer isso, os cientistas de dados geralmente carregam os dados de treinamento de um banco de dados em uma ferramenta diferente, por exemplo, um notebook Jupyter. Mas os conjuntos de dados de treinamento são enormes e consomem muita memória. A transferência de grandes conjuntos de dados também consome largura de banda da rede e torna o processo mais lento. Claramente, o melhor lugar para analisar os dados é o banco de dados onde eles estão armazenados.
O cientista de dados precisa ler apenas os atributos essenciais do banco de dados. Isso simplifica a análise de dados, reduz o uso da memória da sessão de treinamento e limita a quantidade de transferência de dados da rede. Por exemplo, considere dados de treinamento com milhões de documentos JSON, cada um com dez campos. Se apenas 8 desses campos forem necessários para o treinamento, o cientista de dados poderá economizar ~20% de memória ignorando o restante (supondo que todos os campos sejam do mesmo tamanho).
Neste e no próximo artigo, aprenderemos:
- Como fazer análise exploratória de dados (EDA) e visualizar os resultados da ciência de dados usando o serviço Couchbase Query. Os serviços Query e Analytics são executados no mesmo cluster do Couchbase que os dados de treinamento e as previsões. O uso desses serviços para analisar os dados de treinamento e as previsões torna o processo de ciência de dados fácil e eficiente.
- Como ler com eficiência os dados de treinamento usando as APIs de consulta e análise no SDK do Couchbase Python e salvá-los perfeitamente em uma estrutura de dados adequada para aprendizado de máquina (ML), por exemplo, um dataframe do pandas.
- Como o Couchbase pode atender a todas as necessidades de armazenamento do processo de ciência de dados, armazenando não apenas os dados de treinamento e as previsões, mas também os modelos de ML (até 20 MB de tamanho).
Enquadre o problema
O processo de ciência de dados (Figura 1) geralmente começa com a definição do problema. Neste artigo, usaremos a previsão de rotatividade de clientes como exemplo.
A equipe de vendas de uma empresa de serviços de streaming on-line quer saber se o aumento do custo da assinatura mensal pode levar a maiores receitas. No entanto, um aumento muito alto do custo mensal poderia levar a uma maior rotatividade de clientes.
Qual custo mensal maximiza a receita e, ao mesmo tempo, mantém a rotatividade de clientes sob controle? Para responder a isso, o cientista de dados precisa prever as pontuações de rotatividade se os custos mensais forem aumentados em valores específicos, por exemplo, $1, $2 etc.
Coletar e preparar dados relevantes
Após definir o problema, o cientista de dados coletará os dados corretos necessários para solucioná-lo. Esses dados brutos podem precisar ser limpos e pré-processados, por exemplo, para lidar com valores ausentes. Esses dados brutos podem precisar ser limpos e pré-processados, por exemplo, para lidar com valores ausentes.
Para este artigo, usaremos o online_streaming.csv conjunto de dados disponível aqui. Esse é um conjunto de dados sintético criado pelo Couchbase. Ele simula 500.000 registros de clientes de uma empresa hipotética de serviços de streaming on-line.
Carregue esse conjunto de dados em seu cluster do Couchbase usando as etapas mencionadas no LEIAME aqui.
Explore os dados
Depois de coletar e preparar os dados necessários, o cientista de dados os explora para obter insights sobre os dados. A análise exploratória de dados (EDA) é uma abordagem que geralmente emprega técnicas de visualização para descobrir a estrutura dos dados e extrair variáveis importantes.
Conforme mencionado anteriormente, o melhor lugar para fazer essa análise é no banco de dados em que os dados estão armazenados.
Os cientistas de dados podem usar os serviços do Couchbase Query and Analytics para a EDA. Esses serviços são executados no mesmo cluster do Couchbase em que os dados de treinamento estão armazenados. Os dados de treinamento não precisam ser movidos para outro local para análise. Isso torna o processo simples e eficiente.
Escalonamento multidimensional (MDS) do Couchbase, descrito aquiO sistema de escalonamento de serviços, que permite que esses serviços sejam dimensionados de forma independente. Isso resulta em consultas mais rápidas. Os recursos de gerenciamento de dados paralelos do serviço Couchbase Analytics tornam a análise de dados ainda mais eficiente.
Para usar os recursos de consulta descritos aqui, primeiro crie um índice primário no bucket online_streaming executando o seguinte comando na interface do usuário de consulta. Selecione contexto de consulta no menu suspenso e digite: CRIAR ÍNDICE PRIMÁRIO EM streaming on-line
Em vez de criar um índice primário, você também pode usar o recurso Index Advisor (CONSELHO na interface do usuário ou na linha de comando cbq ) no serviço Couchbase Query para encontrar os índices apropriados a serem criados, por consulta, com base no onde cláusula.
Uma das principais etapas da análise exploratória de dados é entender os atributos do conjunto de dados.
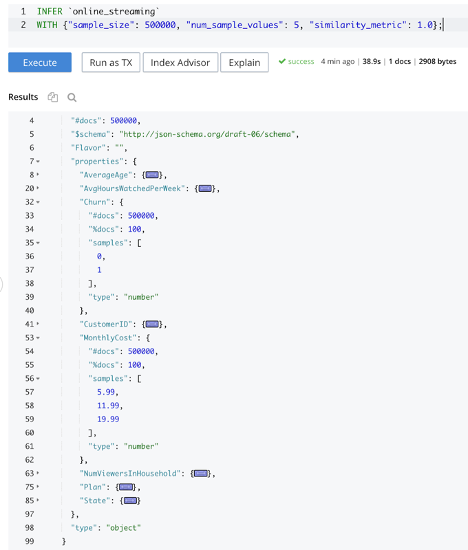
O INFER para consultas SQL++ pode ajudar. Ela permite aos usuários inferir a estrutura dos documentos, os tipos de dados de vários atributos, etc. Observe que INFER é de natureza estatística e não determinística, conforme explicado aqui.
Como visto na consulta abaixo, a execução do INFER no bucket online_streaming mostra que há 500.000 documentos nesse bucket e que os documentos contêm atributos como Plan e CustomerID. A expansão de atributos individuais fornece detalhes adicionais. Por exemplo, MonthlyCost tem três valores possíveis - $5.99, $11.99 e $19.99.
Usaremos a regressão logística, um algoritmo de aprendizado supervisionado, para treinar o preditor de rotatividade.
O Agitação no conjunto de dados será usado como o rótulo (saída; destino) para o aprendizado supervisionado. Agitação é definido como 0 ou 1; 1 indica que o cliente cancelou. O processo de treinamento tenta aprender a relação entre o rótulo (rotatividade) e as entradas (outros atributos no conjunto de dados).
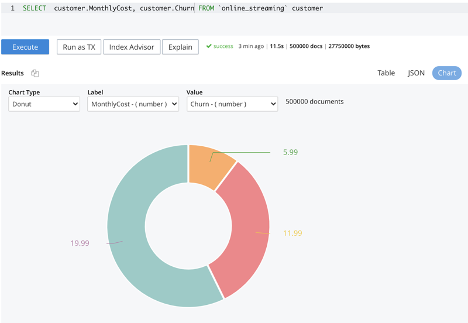
Os gráficos de consulta e análise (no Couchbase Server 7.0.2 e posterior) podem ser usados para visualizar padrões ou correlações entre os atributos. Isso pode ajudar a decidir quais atributos devem ser incluídos no processo de treinamento. O gráfico abaixo mostra que os clientes com custos mensais mais altos têm maior probabilidade de cancelar a assinatura. Claramente, o custo mensal é um atributo importante a ser incluído no treinamento do preditor de rotatividade.
Os serviços Couchbase Query e Analytics também oferecem muitas funções internas, como média e desvio padrão, que podem ser usadas para análise estatística. Outras funções de consulta, como data e string, podem ajudar no pré-processamento de dados.
Treinar o modelo
Depois de explorar os dados, o cientista de dados passa a treinar o modelo. Treinaremos o preditor de rotatividade de clientes usando as etapas mostradas na Figura 2. Se necessário, os recursos também podem ser armazenados em um bucket do Couchbase.
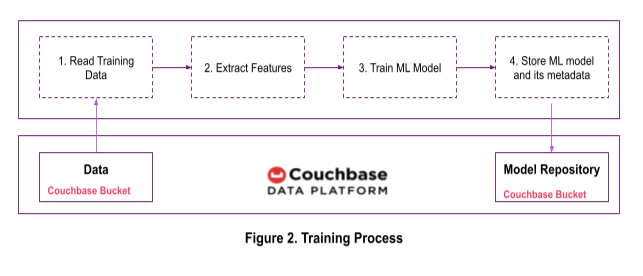
Etapa 1: Leia com eficiência os dados de treinamento do Couchbase
Já identificamos os atributos importantes durante a EDA usando o serviço de consulta. Buscaremos apenas esses atributos durante a leitura dos dados de treinamento. Isso reduz o tamanho dos dados lidos na rede e a quantidade de memória necessária para armazená-los na sessão de treinamento.
Usaremos a API de consulta no Couchbase Python SDK (versão 3) para com eficiência ler todo o conjunto de dados de treinamento por selecionando apenas os atributos que são relevantes para treinar nosso preditor de rotatividade.
Os dados lidos usando a API de consulta podem ser facilmente armazenados em um dataframe do pandas, como visto neste código.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
import numpy as np import pandas as pd # Connect to Couchbase cluster using the Python SDK from couchbase.cluster import Cluster, ClusterOptions from couchbase.auth import PasswordAuthenticator # Fill-in the hostname or IP address, user_name and password for your cluster. # E.g. Cluster.connect("couchbase://localhost", ClusterOptions(PasswordAuthenticator("Administrator", # "password"))) cluster = Cluster.connect(<host>, ClusterOptions(PasswordAuthenticator(<user_name>, <password>))) # Connect to online_streaming bucket cb = cluster.bucket('online_streaming') # Use the Query API to get all documents from the bucket # Specify only the needed attributes in the SELECT clause query_result = cb.query("SELECT c.AverageAge, c.AvgHoursWatchedPerWeek, c.Churn, c.MonthlyCost, c.NumViewersInHousehold, c.Plan FROM `online_streaming` as c") # Easily store the read data to a Pandas data frame data = pd.DataFrame(list(query_result)) data.head() |
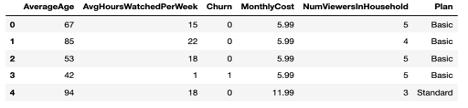
Consulte Documentação do SDK do Couchbase Python para obter informações sobre como usar o SDK.
A Analytics API no Couchbase Python SDK também pode ler os dados de treinamento, conforme descrito no próximo artigo.
Etapa 2: Extrair recursos
O cientista de dados converterá os dados brutos em recursos adequados a serem passados para a função de treinamento. O tipo de técnicas de engenharia de recursos depende do tipo de dados.
Uma das etapas mais comuns da engenharia de recursos é converter dados categóricos em valores numéricos usando a codificação one-hot. Usaremos esse código Python para codificar dados categóricos e criar os quadros de dados de entrada (X) e de rótulo (Y).
|
1 2 3 4 5 6 7 |
# Get one-hot encoding for categorical features categoricals = data.select_dtypes(include = object).columns data = pd.get_dummies(data, columns=categoricals) # Drop the 'Churn' column since it is a label and not a feature feature_names = list(set(list(data.columns)) - set(['Churn'])) X = data[feature_names] Y = data['Churn'] |
Como visto no X.head() abaixo, a codificação one-hot substituiu a coluna Plan, que foi definida anteriormente como uma das Básico, Padrão ou Premiumcom três colunas numéricas Plan_Standard, Plan_Basic e Plan_Premium.
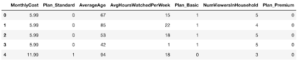
Etapa 3: Treinar o modelo de ML
Em seguida, o cientista de dados prosseguirá com o treinamento do modelo de ML relevante para seu caso de uso.
Usaremos o código abaixo para treinar um preditor de rotatividade usando os recursos criados na etapa dois.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
from sklearn.model_selection import train_test_split # train_test_split function splits the data into two subsets for training and testing. # The test_size parameter below ensures that the test subset is 20% of the # training data. X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.2, random_state=101, shuffle=False) from sklearn.linear_model import LogisticRegression # We will use Logistic regression to train the churn predictor lm = LogisticRegression(max_iter=200) lm.fit(X_train, Y_train) lm.score(X_train, Y_train) lm.score(X_test, Y_test) |
Etapa 4: armazenar o modelo de ML e seus metadados
O cientista de dados precisa salvar o modelo treinado para gerar previsões posteriormente. Essa etapa também é importante para reproduzir a pesquisa. A ciência de dados é um processo iterativo e pode haver várias versões do modelo.
Usaremos o código abaixo para armazenar nosso modelo de previsão de rotatividade (versão 1) e seus metadados em um arquivo repositório_modelo no Couchbase. Crie esse bucket em seu cluster do Couchbase antes de continuar.
O tamanho do nosso modelo de previsão de rotatividade é inferior a 1 KB. Modelos de até 20 MB podem ser armazenados no Couchbase como JSON ou formatos binários, conforme descrito no artigo aqui. O nome dos recursos esperados pelo modelo treinado é armazenado nos metadados do modelo.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
import pickle from datetime import datetime def store_model_on_couchbase(model, feature_names, model_id): # Store model in Binary format from couchbase_core._libcouchbase import FMT_BYTES bucket = cluster.bucket('model_repository') model_bytes = pickle.dumps(model) bucket.upsert(model_id, model_bytes, format=FMT_BYTES) now = datetime.now() model_metadata = {'model_id': model_id, 'feature_names': list(feature_names), "creation time": now.strftime("%d/%m/%Y %H:%M:%S")} # Store model metadata under a separate key key = model_id + "_metadata" bucket.upsert(key, model_metadata) |
|
1 |
store_model_on_couchbase(lm, feature_names, 'churn_predictor_model_v1') |
Verifique se o modelo e seus metadados foram armazenados com êxito no Couchbase.

Conclusão
Neste artigo, aprendemos como o Couchbase facilita a ciência de dados. Usando a previsão de rotatividade de clientes como exemplo, vimos como realizar uma análise exploratória usando o serviço Query, como ler com eficiência grandes conjuntos de dados de treinamento usando o Python SDK e armazená-los facilmente em uma estrutura de dados adequada para ML, por exemplo, quadro de dados pandas. Também vimos como armazenar modelos de ML (até 20 MB de tamanho) e seus metadados no Couchbase.
No próximo artigo, aprenderemos como fazer previsões, armazená-las no Couchbase e como usar os gráficos de consulta para analisá-las.
Próximas etapas
Se você estiver interessado em aprender mais sobre aprendizado de máquina e Couchbase, aqui estão algumas etapas e recursos excelentes para você começar:
- Inicie sua avaliação gratuita do Couchbase Cloud - Não é necessária instalação.
- Couchbase Under the Hood: uma visão geral da arquitetura - Aprofunde-se nos detalhes técnicos com este white paper.
- Explore o Couchbase Consulta, Pesquisa de texto completo, Eventose Análises serviços.
- Dê uma olhada nesses blogs do ML:
