Este artículo ha sido escrito por Karen YuanUn interno de secundaria.
La ciencia de datos extrae conocimiento de los datos y aplica ese conocimiento para resolver problemas. En los próximos dos posts, aprenderemos cómo Couchbase Data Platform puede satisfacer varias necesidades de la ciencia de datos y simplificar y reducir el número de herramientas necesarias durante el proceso.
Visión general
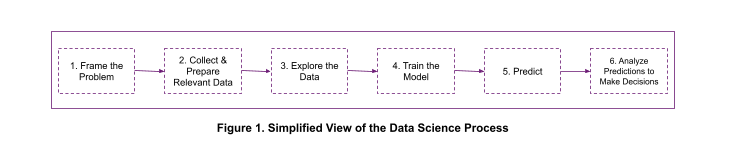
Los flujos de trabajo de la ciencia de datos implican varios pasos, como se muestra en la Figura 1. Los científicos de datos se ven obligados a utilizar diferentes herramientas para los distintos pasos, lo que complica el proceso y lo hace menos eficiente.
Por ejemplo, los científicos de datos realizan análisis exploratorios de datos para determinar qué atributos de los datos de entrenamiento son importantes para su caso de uso. Para ello, los científicos de datos suelen cargar los datos de entrenamiento de una base de datos en una herramienta diferente, por ejemplo, un cuaderno Jupyter. Pero los conjuntos de datos de entrenamiento son enormes y consumen mucha memoria. La transferencia de grandes conjuntos de datos también consume ancho de banda de red y ralentiza el proceso. Está claro que el mejor lugar para analizar los datos es la base de datos donde se almacenan.
El científico de datos sólo necesita leer los atributos esenciales de la base de datos. Esto simplifica el análisis de datos, reduce el uso de memoria de la sesión de entrenamiento y limita la cantidad de transferencia de datos de red. Por ejemplo, considere datos de entrenamiento con millones de documentos JSON; cada uno tiene diez campos. Si sólo se necesitan 8 de estos campos para el entrenamiento, el científico de datos puede ahorrar ~20% de memoria ignorando el resto (suponiendo que todos los campos tengan el mismo tamaño).
En este artículo y en el siguiente aprenderemos:
- Cómo hacer análisis exploratorio de datos (EDA) y visualizar resultados de ciencia de datos usando el servicio Couchbase Query. Los servicios Query y Analytics se ejecutan en el mismo clúster de Couchbase que los datos de entrenamiento y las predicciones. El uso de estos servicios para analizar los datos de entrenamiento y las predicciones hace que el proceso de ciencia de datos sea fácil y eficiente.
- Cómo leer eficientemente datos de entrenamiento usando las APIs de Query y Analytics en el Couchbase Python SDK y guardarlos sin problemas en una estructura de datos adecuada para machine learning (ML), por ejemplo, un pandas dataframe.
- Cómo Couchbase puede satisfacer todas las necesidades de almacenamiento de procesos de ciencia de datos almacenando no sólo los datos de entrenamiento y las predicciones, sino también los modelos ML (hasta 20 MB de tamaño).
Enmarcar el problema
El proceso de la ciencia de datos (Figura 1) suele comenzar con la definición de un problema. En este artículo, utilizaremos como ejemplo la predicción de la pérdida de clientes.
El equipo de ventas de una empresa de servicios de streaming online quiere saber si aumentar el coste mensual de la suscripción puede generar mayores ingresos. Sin embargo, aumentar demasiado el coste mensual podría provocar una mayor fuga de clientes.
¿Qué coste mensual maximiza los ingresos manteniendo a raya la pérdida de clientes? Para responder a esta pregunta, el científico de datos tiene que predecir los resultados de rotación si los costes mensuales aumentan en cantidades específicas, por ejemplo, $1, $2, etc.
Recopilar y preparar los datos pertinentes
Una vez definido el problema, el científico de datos recopilará los datos necesarios para resolverlo. Es posible que haya que limpiar y preprocesar estos datos brutos, por ejemplo, para tratar los valores que faltan.
Para este artículo, utilizaremos el online_streaming.csv conjunto de datos disponible aquí. Se trata de un conjunto de datos sintéticos creado por Couchbase. Simula 500.000 registros de clientes de una hipotética empresa de servicios de streaming online.
Cargue este conjunto de datos en su cluster Couchbase siguiendo los pasos mencionados en el README aquí.
Explorar los datos
Tras recopilar y preparar los datos necesarios, el científico de datos los explora para conocerlos mejor. El análisis exploratorio de datos (AED) es un enfoque que suele emplear técnicas de visualización para descubrir la estructura de los datos y extraer variables importantes.
Como ya se ha mencionado, el mejor lugar para realizar este análisis es la base de datos donde se almacenan los datos.
Los científicos de datos pueden usar los servicios Couchbase Query y Analytics para EDA. Estos servicios se ejecutan en el mismo clúster de Couchbase en el que se almacenan los datos de entrenamiento. No es necesario trasladar los datos de entrenamiento a otro lugar para su análisis. Esto hace que el proceso sea simple y eficiente.
Couchbase Multi-Dimensional Scaling (MDS), descrito aquípermite escalar estos servicios de forma independiente. El resultado son consultas más rápidas. Las capacidades de gestión paralela de datos del servicio Couchbase Analytics hacen que el análisis de datos sea aún más eficiente.
Para utilizar las funciones de consulta descritas aquí, cree primero un índice primario en el bucket online_streaming ejecutando el siguiente comando en la interfaz de usuario de consulta. Seleccione contexto de consulta en el menú desplegable e introdúzcalo: CREAR ÍNDICE PRIMARIO EN streaming_online
En lugar de crear un índice primario, también puede utilizar la función Index Advisor (CONSEJO en la interfaz de usuario o en la línea de comandos cbq tool) en el servicio Couchbase Query para encontrar los índices apropiados a crear, por consulta, basándose en la donde cláusula.
Uno de los pasos clave en el análisis exploratorio de datos es comprender los atributos del conjunto de datos.
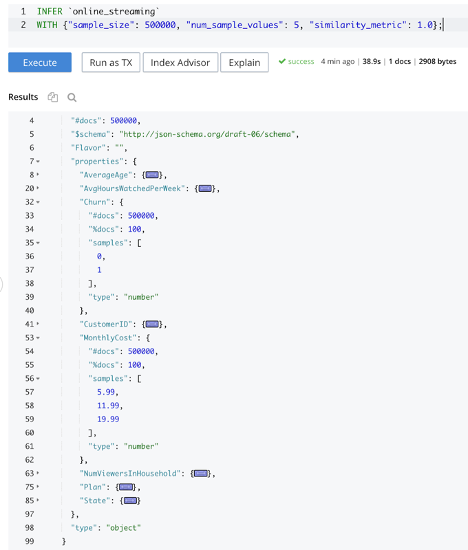
En INFER para consultas SQL++. Permite inferir la estructura de los documentos, los tipos de datos de diversos atributos, etc. Tenga en cuenta que INFER es de naturaleza estadística y no determinista, como se explica aquí.
Como se ve en la siguiente consulta, la ejecución de la función INFER en el bucket online_streaming muestra que hay 500.000 documentos en este bucket y que los documentos contienen atributos como Plan y CustomerID. Si se amplían los atributos individuales, se obtienen detalles adicionales. Por ejemplo, MonthlyCost tiene tres valores posibles: $5.99, $11.99 y $19.99.
Utilizaremos la regresión logística, un algoritmo de aprendizaje supervisado, para entrenar el predictor de bajas.
En Churn del conjunto de datos se utilizará como etiqueta (salida; objetivo) para el aprendizaje supervisado. Churn se establece en 0 ó 1; 1 indica que el cliente ha abandonado. El proceso de entrenamiento trata de aprender la relación entre la etiqueta (abandono) y las entradas (otros atributos del conjunto de datos).
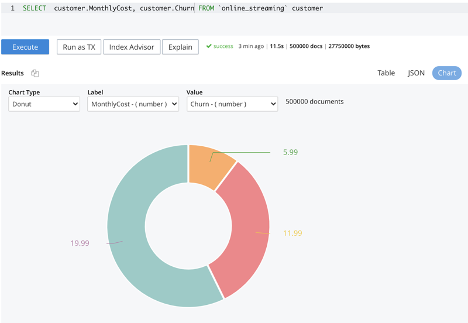
Los gráficos de consultas y análisis (en Couchbase Server 7.0.2 y posteriores) se pueden utilizar para visualizar patrones o correlaciones entre los atributos. Esto puede ayudar a decidir qué atributos incluir en el proceso de formación. El siguiente gráfico muestra que los clientes con costes mensuales más altos son más propensos a la rotación. Claramente, el coste mensual es un atributo importante que debe incluirse en el entrenamiento del predictor de bajas.
Los servicios de Couchbase Query y Analytics también proporcionan muchas funciones integradas como la media y la desviación estándar que se pueden utilizar para el análisis estadístico. Otras funciones de Query como date y string pueden ayudar con el preprocesamiento de datos.
Entrenar el modelo
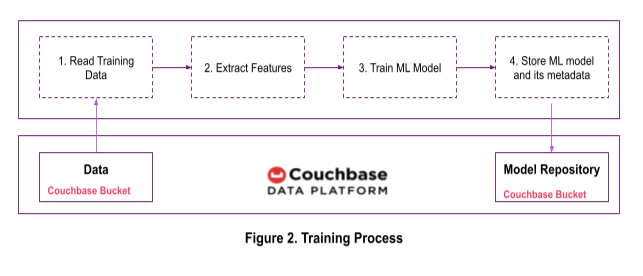
Tras explorar los datos, el científico de datos procede a entrenar el modelo. Entrenaremos el predictor de pérdida de clientes siguiendo los pasos que se muestran en la Figura 2. Si es necesario, las características también se pueden almacenar en un bucket de Couchbase.
Paso 1: Leer eficazmente los datos de entrenamiento de Couchbase
Ya hemos identificado los atributos importantes durante EDA utilizando el servicio de consulta. Sólo recuperaremos esos atributos cuando leamos los datos de entrenamiento. Esto reduce el tamaño de los datos leídos a través de la red y la cantidad de memoria necesaria para almacenarlos en la sesión de entrenamiento.
Utilizaremos la API de consulta en Couchbase Python SDK (versión 3) para eficientemente leer todo el conjunto de datos de entrenamiento mediante seleccionar sólo los atributos que son relevantes para entrenar nuestro predictor de churn.
Los datos leídos mediante la API de consulta se pueden almacenar fácilmente en un marco de datos de pandas, como se ve en este código.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
import numpy as np import pandas as pd # Connect to Couchbase cluster using the Python SDK from couchbase.cluster import Cluster, ClusterOptions from couchbase.auth import PasswordAuthenticator # Fill-in the hostname or IP address, user_name and password for your cluster. # E.g. Cluster.connect("couchbase://localhost", ClusterOptions(PasswordAuthenticator("Administrator", # "password"))) cluster = Cluster.connect(<host>, ClusterOptions(PasswordAuthenticator(<user_name>, <password>))) # Connect to online_streaming bucket cb = cluster.bucket('online_streaming') # Use the Query API to get all documents from the bucket # Specify only the needed attributes in the SELECT clause query_result = cb.query("SELECT c.AverageAge, c.AvgHoursWatchedPerWeek, c.Churn, c.MonthlyCost, c.NumViewersInHousehold, c.Plan FROM `online_streaming` as c") # Easily store the read data to a Pandas data frame data = pd.DataFrame(list(query_result)) data.head() |
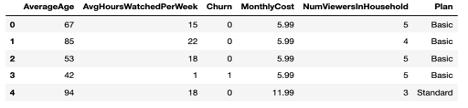
Consulte Documentación de Couchbase Python SDK para obtener información sobre el uso del SDK.
La Analytics API en el Couchbase Python SDK también puede leer los datos de entrenamiento como se describe en el siguiente artículo.
Paso 2: Extraer características
El científico de datos convertirá los datos brutos en características adecuadas que se pasarán a la función de entrenamiento. El tipo de técnicas de ingeniería de características depende del tipo de datos.
Uno de los pasos más comunes de la ingeniería de características es convertir datos categóricos en valores numéricos utilizando la codificación one-hot. Utilizaremos este código Python para codificar datos categóricos y crear los marcos de datos de entrada (X) y etiqueta (Y).
|
1 2 3 4 5 6 7 |
# Get one-hot encoding for categorical features categoricals = data.select_dtypes(include = object).columns data = pd.get_dummies(data, columns=categoricals) # Drop the 'Churn' column since it is a label and not a feature feature_names = list(set(list(data.columns)) - set(['Churn'])) X = data[feature_names] Y = data['Churn'] |
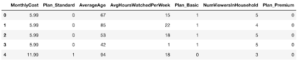
Como se ve en el X.head() a continuación, la codificación one-hot ha sustituido a la columna Plan, que antes se establecía en uno de los siguientes valores Básico, Estándar o Premiumcon tres columnas numéricas Plan_Standard, Plan_Basic y Plan_Premium.
Paso 3: Entrenar el modelo ML
A continuación, el científico de datos procederá a entrenar el modelo ML pertinente para su caso de uso.
Utilizaremos el código siguiente para entrenar un predictor de bajas utilizando las características creadas en el paso dos.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
from sklearn.model_selection import train_test_split # train_test_split function splits the data into two subsets for training and testing. # The test_size parameter below ensures that the test subset is 20% of the # training data. X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.2, random_state=101, shuffle=False) from sklearn.linear_model import LogisticRegression # We will use Logistic regression to train the churn predictor lm = LogisticRegression(max_iter=200) lm.fit(X_train, Y_train) lm.score(X_train, Y_train) lm.score(X_test, Y_test) |
Paso 4: Almacenar el modelo ML y sus metadatos
El científico de datos necesita guardar el modelo entrenado para generar predicciones más adelante. Este paso también es importante para reproducir la investigación. La ciencia de datos es un proceso iterativo y podría haber múltiples versiones del modelo.
Utilizaremos el siguiente código para almacenar nuestro modelo de predicción de bajas (versión 1) y sus metadatos en un archivo depósito_de_modelos en Couchbase. Cree este bucket en su clúster de Couchbase antes de continuar.
El tamaño de nuestro modelo predictor de churn es inferior a 1 KB. Los modelos de hasta 20MB de tamaño se pueden almacenar en Couchbase en formato JSON o binario como se describe en el artículo aquí. El nombre de las características esperadas por el modelo entrenado se almacenan en los metadatos del modelo.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
import pickle from datetime import datetime def store_model_on_couchbase(model, feature_names, model_id): # Store model in Binary format from couchbase_core._libcouchbase import FMT_BYTES bucket = cluster.bucket('model_repository') model_bytes = pickle.dumps(model) bucket.upsert(model_id, model_bytes, format=FMT_BYTES) now = datetime.now() model_metadata = {'model_id': model_id, 'feature_names': list(feature_names), "creation time": now.strftime("%d/%m/%Y %H:%M:%S")} # Store model metadata under a separate key key = model_id + "_metadata" bucket.upsert(key, model_metadata) |
|
1 |
store_model_on_couchbase(lm, feature_names, 'churn_predictor_model_v1') |
Comprueba que el modelo y sus metadatos se han almacenado correctamente en Couchbase.

Conclusión
En este artículo, aprendimos cómo Couchbase facilita la ciencia de datos. Usando la predicción de pérdida de clientes como ejemplo, vimos cómo realizar análisis exploratorios usando el servicio Query, cómo leer eficientemente grandes conjuntos de datos de entrenamiento usando el SDK de Python y almacenarlos fácilmente en una estructura de datos adecuada para ML, por ejemplo, pandas data frame. También vimos cómo almacenar modelos ML (hasta 20MB de tamaño) y sus metadatos en Couchbase.
En el próximo artículo, aprenderemos cómo hacer predicciones, almacenarlas en Couchbase y cómo utilizar los gráficos Query para analizarlas.
Próximos pasos
Si estás interesado en aprender más sobre machine learning y Couchbase, aquí tienes algunos pasos a seguir y recursos para empezar:
- Comience su prueba gratuita de Couchbase Cloud - no requiere instalación.
- Couchbase bajo el capó: una visión general de la arquitectura - profundice en los detalles técnicos con este libro blanco.
- Explorar Couchbase Consulta, Búsqueda de texto completo, Eventosy Analítica servicios.
- Consulte estos blogs de ML:
