This post was co-authored by Karen Yuan, a High School Intern.
Data science extracts knowledge from data and applies that knowledge to solve problems. In the next two posts, we will learn how the Couchbase Data Platform can meet various data science needs and simplify and reduce the number of tools needed during the process.
Overview
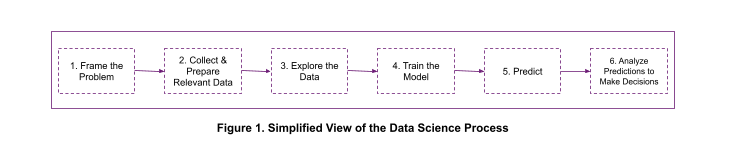
Data science workflows involve several steps, as shown in Figure 1. Data scientists are forced to use different tools for different steps, complicating the process and making it less efficient.
For example, data scientists perform exploratory data analysis to determine which attributes in the training data are important for their use case. To do this, data scientists usually load training data from a database into a different tool, e.g., a Jupyter notebook. But training datasets are huge and consume a lot of memory. Transferring large datasets also consumes network bandwidth and slows the process. Clearly, the best place to analyze data is the database where the data is stored.
The data scientist needs to read only the essential attributes from the database. This simplifies data analysis, reduces training session memory usages and limits the amount of network data transfer. For example, consider training data with millions of JSON documents; each has ten fields. If only 8 of these fields are needed for training, the data scientist can save ~20% of memory by ignoring the rest (assuming all fields are of the same size).
In this and the following article, we will learn:
- How to do exploratory data analysis (EDA) and visualize data science results using the Couchbase Query service. The Query and Analytics services run on the same Couchbase cluster as the training data and predictions. Using these services to analyze the training data and the predictions makes the data science process easy and performant.
- How to efficiently read training data using the Query and Analytics APIs in the Couchbase Python SDK and seamlessly save it to a data structure suitable for machine learning (ML), e.g., a pandas dataframe.
- How Couchbase can meet all data science process storage needs by storing not just the training data and predictions but also ML models (up to 20MB in size).
Frame the problem
The data science process (Figure 1) usually starts with a problem definition. In this article, we will use customer churn prediction as an example.
The sales team at an online streaming service company wants to know whether increasing the monthly subscription cost can lead to higher revenues. However, increasing the monthly cost too high could lead to higher customer churn.
What monthly cost maximizes the revenue while keeping the customer churn in check? To answer this, the data scientist needs to predict the churn scores if the monthly costs are increased by specific amounts, e.g., $1, $2, etc.
Collect and prepare relevant data
After defining the problem, the data scientist will collect the right data needed to solve the problem. This raw data may need to be cleaned and pre-processed, e.g., to handle missing values.
For this article, we will use the online_streaming.csv dataset available here. This is a synthetic dataset created by Couchbase. It simulates 500,000 customer records of a hypothetical online streaming service company.
Load this dataset into your Couchbase cluster using the steps mentioned in the README here.
Explore the data
After collecting and preparing the needed data, the data scientist explores it to gain insight into the data. Exploratory data analysis (EDA) is an approach that often employs visualization techniques to uncover the structure of data and extract important variables.
As mentioned earlier, the best place to do this analysis is in the database where the data is stored.
Data scientists can use Couchbase Query and Analytics services for EDA. These services run on the same Couchbase cluster as the one where the training data is stored. Training data need not be moved elsewhere for analysis. This makes the process simple and efficient.
Couchbase Multi-Dimensional Scaling (MDS), described here, allows these services to be scaled independently. This results in faster queries. The parallel data management capabilities of the Couchbase Analytics service make data analysis even more efficient.
To use the Query features described here, first create a primary index on the online_streaming bucket by running the following command in the Query UI. Select query context from the dropdown menu and enter: CREATE PRIMARY INDEX ON online_streaming
Instead of creating a primary index, you could also use the Index Advisor feature (ADVISE statement in the UI or command line cbq tool) in the Couchbase Query service to find appropriate indexes to create, per query, based on the where clause.
One of the key steps in exploratory data analysis is to understand the attributes in the dataset.
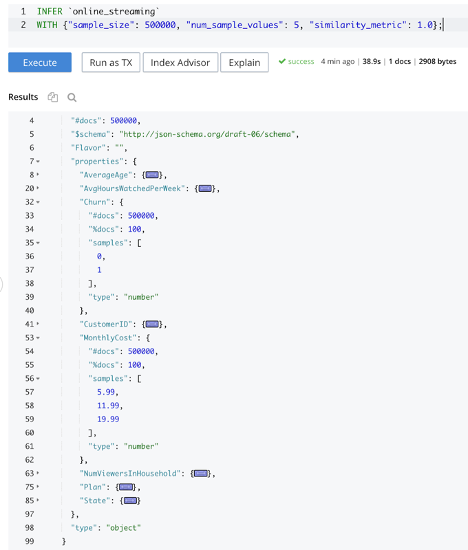
The INFER statement for SQL++ queries can help. It allows users to infer the structure of documents, data types of various attributes, etc. Note that INFER is statistical in nature rather than deterministic, as explained here.
As seen in the query below, executing the INFER statement on the online_streaming bucket shows that there are 500,000 documents in this bucket and the documents contain attributes such as Plan and CustomerID. Expanding on individual attributes gives additional details. E.g., MonthlyCost has three possible values – $5.99, $11.99 and $19.99.
We will use logistic regression, a supervised learning algorithm, to train the churn predictor.
The Churn attribute in the dataset will be used as the label (output; target) for the supervised learning. Churn is set to either 0 or 1; 1 indicates the customer has churned. The training process tries to learn the relationship between the label (churn) and the inputs (other attributes in the dataset).
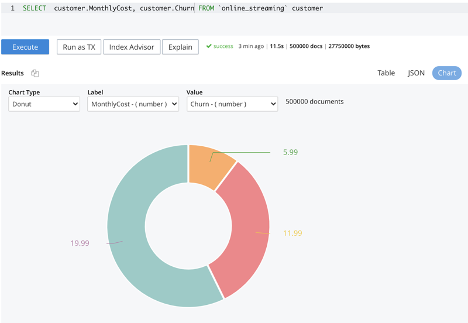
Query and Analytics Charts (in Couchbase Server 7.0.2 and later) can be used to visualize patterns or correlations between the attributes. This can help decide which attributes to include in the training process. The chart below shows that customers with higher monthly costs are more likely to churn. Clearly, monthly cost is an important attribute to include while training the churn predictor.
Couchbase Query and Analytics services also provide many built-in functions such as mean and standard deviation that can be used for statistical analysis. Other Query functions such as date and string can help with data preprocessing.
Train the model
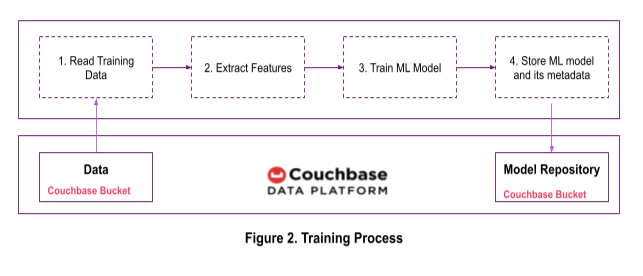
After exploring the data, the data scientist proceeds to train the model. We will train the customer churn predictor using the steps shown in Figure 2. If needed, the features can also be stored in a Couchbase bucket.
Step 1: Efficiently Read Training Data from Couchbase
We have already identified the important attributes during EDA using the Query service. We will fetch only those attributes while reading the training data. This reduces the size of the data read over the network and the amount of memory needed to store it in the training session.
We will use the Query API in Couchbase Python SDK (version 3) to efficiently read the entire training dataset by selecting only the attributes that are relevant to train our churn predictor.
Data read using the query API can be easily stored in a pandas dataframe, as seen in this code.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
import numpy as np import pandas as pd # Connect to Couchbase cluster using the Python SDK from couchbase.cluster import Cluster, ClusterOptions from couchbase.auth import PasswordAuthenticator # Fill-in the hostname or IP address, user_name and password for your cluster. # E.g. Cluster.connect("couchbase://localhost", ClusterOptions(PasswordAuthenticator("Administrator", # "password"))) cluster = Cluster.connect(<host>, ClusterOptions(PasswordAuthenticator(<user_name>, <password>))) # Connect to online_streaming bucket cb = cluster.bucket('online_streaming') # Use the Query API to get all documents from the bucket # Specify only the needed attributes in the SELECT clause query_result = cb.query("SELECT c.AverageAge, c.AvgHoursWatchedPerWeek, c.Churn, c.MonthlyCost, c.NumViewersInHousehold, c.Plan FROM `online_streaming` as c") # Easily store the read data to a Pandas data frame data = pd.DataFrame(list(query_result)) data.head() |
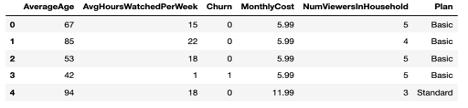
Refer to Couchbase Python SDK documentation for information on using the SDK.
The Analytics API in the Couchbase Python SDK can also read the training data as described in the next article.
Step 2: Extract Features
The data scientist will convert the raw data into suitable features to be passed to the training function. The type of feature engineering techniques depends on the type of data.
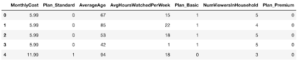
One of the most common feature engineering steps is to convert categorical data to numerical values using one-hot encoding. We will use this Python code to encode categorical data and create the input (X) and label (Y) dataframes.
|
1 2 3 4 5 6 7 |
# Get one-hot encoding for categorical features categoricals = data.select_dtypes(include = object).columns data = pd.get_dummies(data, columns=categoricals) # Drop the 'Churn' column since it is a label and not a feature feature_names = list(set(list(data.columns)) - set(['Churn'])) X = data[feature_names] Y = data['Churn'] |
As seen in the X.head() output below, one-hot encoding has replaced the Plan column, which was set earlier to one of Basic, Standard or Premium, with three numeric columns Plan_Standard, Plan_Basic and Plan_Premium.
Step 3: Train ML Model
Next, the data scientist will proceed with training the ML model relevant to their use case.
We will use the code below to train a churn predictor using the features created in step two.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
from sklearn.model_selection import train_test_split # train_test_split function splits the data into two subsets for training and testing. # The test_size parameter below ensures that the test subset is 20% of the # training data. X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.2, random_state=101, shuffle=False) from sklearn.linear_model import LogisticRegression # We will use Logistic regression to train the churn predictor lm = LogisticRegression(max_iter=200) lm.fit(X_train, Y_train) lm.score(X_train, Y_train) lm.score(X_test, Y_test) |
Step 4: Store ML Model and its Metadata
The data scientist needs to save the trained model to generate predictions later. This step is also important for reproducing the research. Data science is an iterative process and there could be multiple versions of the model.
We will use the code below to store our churn prediction model (version 1) and its metadata in a model_repository bucket on Couchbase. Create this bucket on your Couchbase cluster before proceeding.
The size of our churn predictor model is less than 1KB. Models up to 20MB in size can be stored in Couchbase as JSON or binary formats as described in the article here. The name of features expected by the trained model are stored in the model metadata.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
import pickle from datetime import datetime def store_model_on_couchbase(model, feature_names, model_id): # Store model in Binary format from couchbase_core._libcouchbase import FMT_BYTES bucket = cluster.bucket('model_repository') model_bytes = pickle.dumps(model) bucket.upsert(model_id, model_bytes, format=FMT_BYTES) now = datetime.now() model_metadata = {'model_id': model_id, 'feature_names': list(feature_names), "creation time": now.strftime("%d/%m/%Y %H:%M:%S")} # Store model metadata under a separate key key = model_id + "_metadata" bucket.upsert(key, model_metadata) |
|
1 |
store_model_on_couchbase(lm, feature_names, 'churn_predictor_model_v1') |
Verify that the model and its metadata were successfully stored on Couchbase.

Conclusion
In this article, we learned how Couchbase makes data science easy. Using customer churn prediction as an example, we saw how to perform exploratory analysis using the Query service, how to efficiently read big training datasets using the Python SDK and easily store it in a data structure suitable for ML e.g. pandas data frame. We also saw how to store ML models (up to 20MB in size) and its metadata on Couchbase.
In the next article, we will learn how to make predictions, store them on Couchbase and how to use the Query charts to analyze them.
Next Steps
If you’re interested in learning more about machine learning and Couchbase, here are some great next steps and resources to get you started:
- Start your free trial of Couchbase Cloud – no installation required.
- Couchbase Under the Hood: An Architectural Overview – dive deeper into the technical details with this white paper.
- Explore the Couchbase Query, Full-Text Search, Eventing, and Analytics services.
- Check out these ML blogs:
