Enquanto eu estava no JDays Em Gotemburgo, assisti a uma apresentação sobre Apache Zeppelin. É um notebook baseado na Web que permite a análise interativa de dados. Ele já oferece suporte a vários interpretadores, como Spark, Markdown, Angular, Elastic e outros. Ele é realmente bem integrado ao Spark. E o Couchbase tem um Conector de faísca. E como as pessoas por trás do Zeppelin sabiam que os usuários do Spark gostariam de usar suas próprias dependências, eles tornaram isso muito fácil. Fácil no sentido de que você não precisa escrever um plug-in. Mas você precisa ter a versão mais recente.
Compilar o Apache Zeppelin
Versão mais recente, ou seja, criada a partir dos códigos-fonte mais recentes (admito que não é "tão" fácil...). No entanto, é bastante simples de criar, basta clonar o arquivo repoCertifique-se de que você tenha as dependências corretas (git, jdk, npm, libfontconfig, maven) e, em seguida, dentro do repositório, digite mvn clean package -DskipTests -Pbuild-distr. Agora seria um bom momento para tomar um café (ou talvez brincar com o novo pesquisa de texto completo no Couchbase 4.5, se você ainda não o fez).
No final, você deverá ter a distribuição criada a partir do código-fonte em ./zeppelin-distribution/target/zeppelin-0.6.0-incubating-SNAPSHOT/zeppelin-0.6.0-incubating-SNAPSHOT/. Agora, para executá-lo, basta digitar ./zeppelin-distribution/target/zeppelin-0.6.0-incubating-SNAPSHOT/zeppelin-0.6.0-incubating-SNAPSHOT/bin/zeppelin-daemon.sh start. Se você acessar https://localhost:8080/, verá algo parecido com isto:
Adição da dependência do conector do Couchbase Spark
Agora, o objetivo é adicionar a dependência correta ao interpretador do Spark. Um interpretador é o trecho de código que transforma o conteúdo de um bloco em outra coisa. Portanto, examine o Intérprete tab. Aqui você verá a lista de interpretadores disponíveis. Você poderá editar o interpretador do Spark simplesmente clicando em editar.
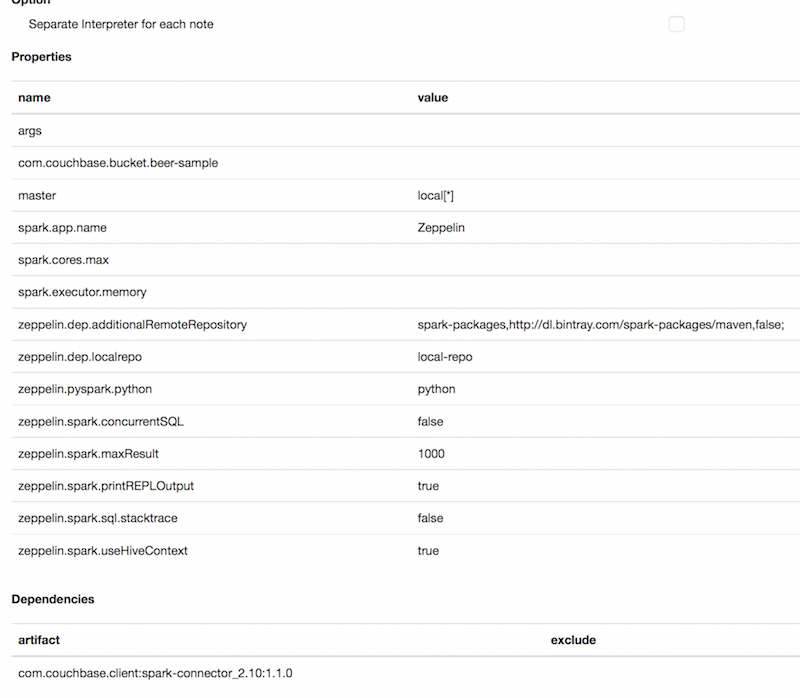
Neste ponto, há duas coisas a fazer. A primeira etapa obrigatória é adicionar a dependência ao conector do Couchbase Spark. A segunda é adicionar uma propriedade para acessar o bucket beer-sample.
Em Propriedades, adicione com.couchbase.bucket.beer-sample como nome e algo como valor. Parece que há um bug no momento que o proíbe de adicionar uma nova propriedade vazia. Você pode edmais tarde.
Em Dependencies (Dependências), adicione com.couchbase.client:spark-connector_2.10:1.1.0 em artefato. Não se esqueça de clicar nos botões +.
Comece a escrever Spark Pads
Estamos em um estado em que podemos começar a ler ou gravar dados do Couchbase. Por algum motivo, sempre importo a amostra de cerveja. Então, o que podemos fazer é começar a ler a partir daí. Podemos criar facilmente um DataFrame para todos os documentos de cerveja. Por padrão, o método read.couchbase lerá do bucket padrão. Portanto, para garantir a leitura da amostra de cerveja, criamos um Map de opção simples contendo o par k/v bucket/beer-sample. Além disso, para ter certeza de que obteremos apenas Beer (cerveja) e não brewery (cervejaria), podemos adicionar um filtro no campo type (tipo). Essas são as duas primeiras linhas que você precisa escrever no bloco para obter um DataFrame contendo todos os documentos sobre cerveja. Depois, se você quiser usá-lo com o Spark SQL, tudo o que precisa fazer é criar uma tempTable a partir desse DataFrame.
Para fazer isso, clique em Caderno de anotações e Criar nova nota. Em seguida, você verá um bloco vazio no qual poderá começar a escrever algum código Scala. Você também pode copiar/colar o seguinte (mas lembre-se de que copiar/colar é ruim).
|
1 2 3 4 5 6 7 |
import org.apache.spark.sql.sources.EqualTo import com.couchbase.spark.sql._ val options = Map("bucket" -> "beer-sample") val dataFrame = sqlc.read.couchbase(schemaFilter = EqualTo("type", "beer"), options) dataFrame.registerTempTable("beer") |
Se você executar esse parágrafo, ele adicionará outro bloco para acompanhamento. Por padrão, o interpretador é %spark. Se você quiser usar outro interpretador, inicie o bloco com o nome dele. Aqui, quero executar consultas Spark SQL. Portanto, iniciarei o bloco com %sql. Em vez de interpretar o código Scala Spark como antes, ele interpreta consultas Spark SQL diretas.
|
1 2 3 4 5 6 7 |
%sql select abv, count(1) value from beer group by abv order by abv |
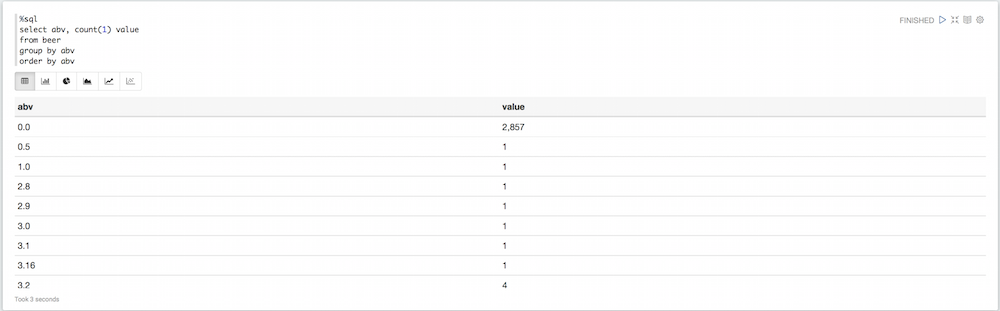
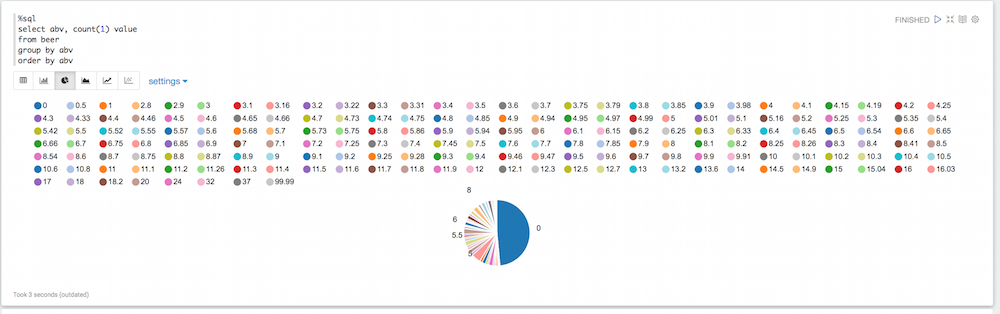
Se você observar o gráfico de pizza, verá que há muitos valores aqui que não são necessariamente úteis. Algumas cervejas têm um valor padrão de 0 para o abv, outras têm um abv ridiculamente alto. Podemos filtrar tudo isso:
|
1 2 3 4 5 6 7 |
%sql select abv, count(1) value from beer where abv > 0 and abv < 15 group by abv order by abv |
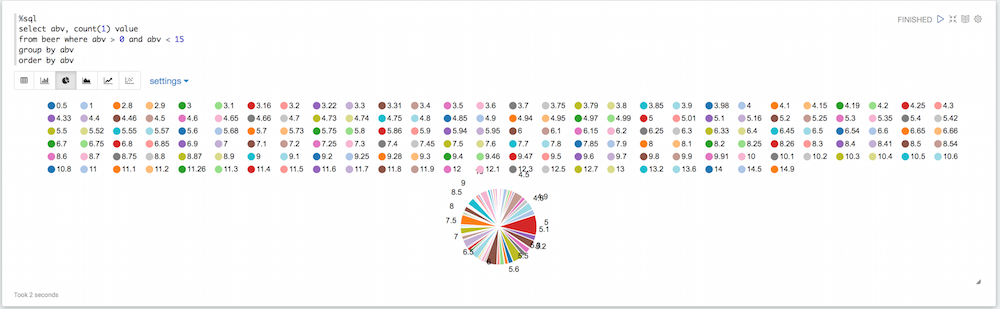
Um pouco melhor, mas ainda temos muitos valores de abv diferentes, então podemos arredondar assim:
|
1 2 3 4 5 6 7 |
%sql select round(abv,0) roundABV, count(1) value from beer where abv > 0 and abv < 15 group by abv order by abv |
Isso está começando a ficar mais fácil de ler. Vamos agrupá-los por categoria e remover as categorias vazias ao mesmo tempo:
|
1 2 3 4 5 6 7 |
%sql select category, round(abv,0) roundABV, count(1) value from beer where abv > 0 and abv < 15 and category != "" group by abv, category order by abv |
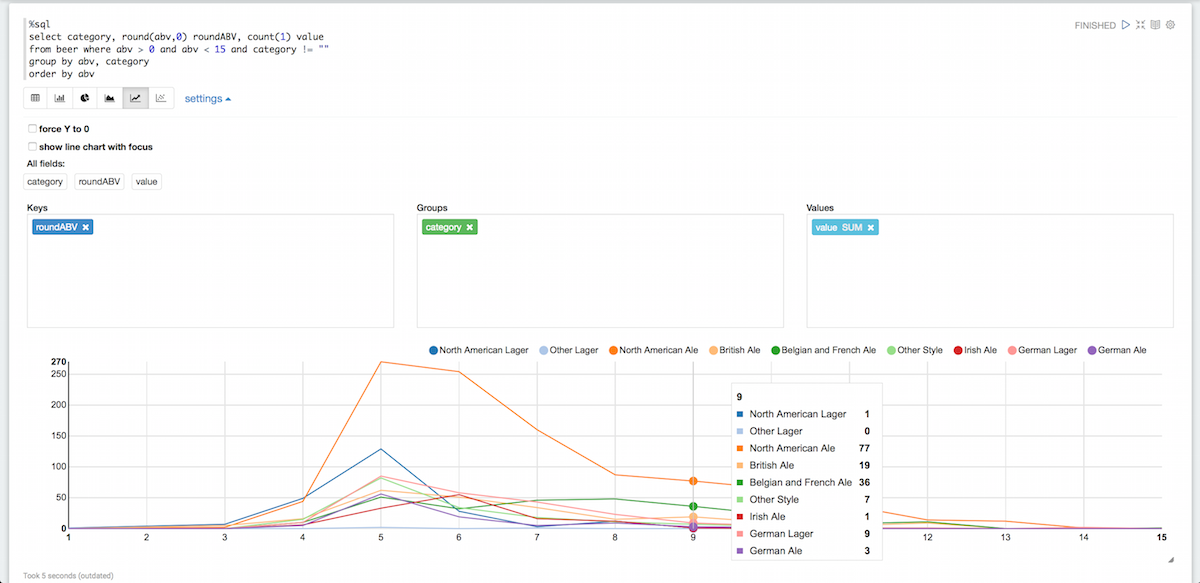
É claro que há muitas outras coisas que você pode fazer com o Zeppelin, mas isso deve ser suficiente para você começar a usar o Couchabse. Se quiser saber mais sobre o Zeppelin, consulte a documentação dele aquiEles também têm alguns bons vídeos.