
Daniel Ancuta é um engenheiro de software com vários anos de experiência no uso de diferentes tecnologias. Ele é um grande fã de "The Zen of Python", que tenta aplicar não apenas em seu código, mas também em sua vida pessoal. Você pode encontrá-lo no Twitter: @daniel_ancuta
Consultas geoespaciais: Usando Python para pesquisar cidades
As informações de geolocalização são usadas todos os dias em quase todos os aspectos de nossa interação com os computadores. Seja em um site que deseja nos enviar notificações personalizadas com base na localização, em mapas que nos mostram a rota mais curta possível ou apenas em tarefas executadas em segundo plano que verificam os lugares que visitamos.
Hoje, gostaria de apresentar a você consultas geoespaciais que são usados no Couchbase. Consultas geoespaciais permitem que você pesquise documentos com base em sua localização geográfica.
Juntos, escreveremos uma ferramenta em Python que usa consultas geoespaciais com API REST do Couchbase e Pesquisa de texto completo do Couchbaseque nos ajudará a pesquisar um banco de dados de cidades.
Pré-requisitos
Dependências
Neste artigo, usei Couchbase Enterprise Edition 5.1.0 build 5552 e Python 3.6.4.
Para executar os snippets deste artigo, você deve instalar o Couchbase 2.3 (estou usando o 2.3.4) via pip.
Couchbase
- Criar um bucket de cidades
- Crie uma pesquisa de cidades com o campo geográfico do tipo geopoint. Você pode ler sobre isso na seção Inserção de um campo filho parte da documentação.
Ele deve se parecer com a imagem abaixo:
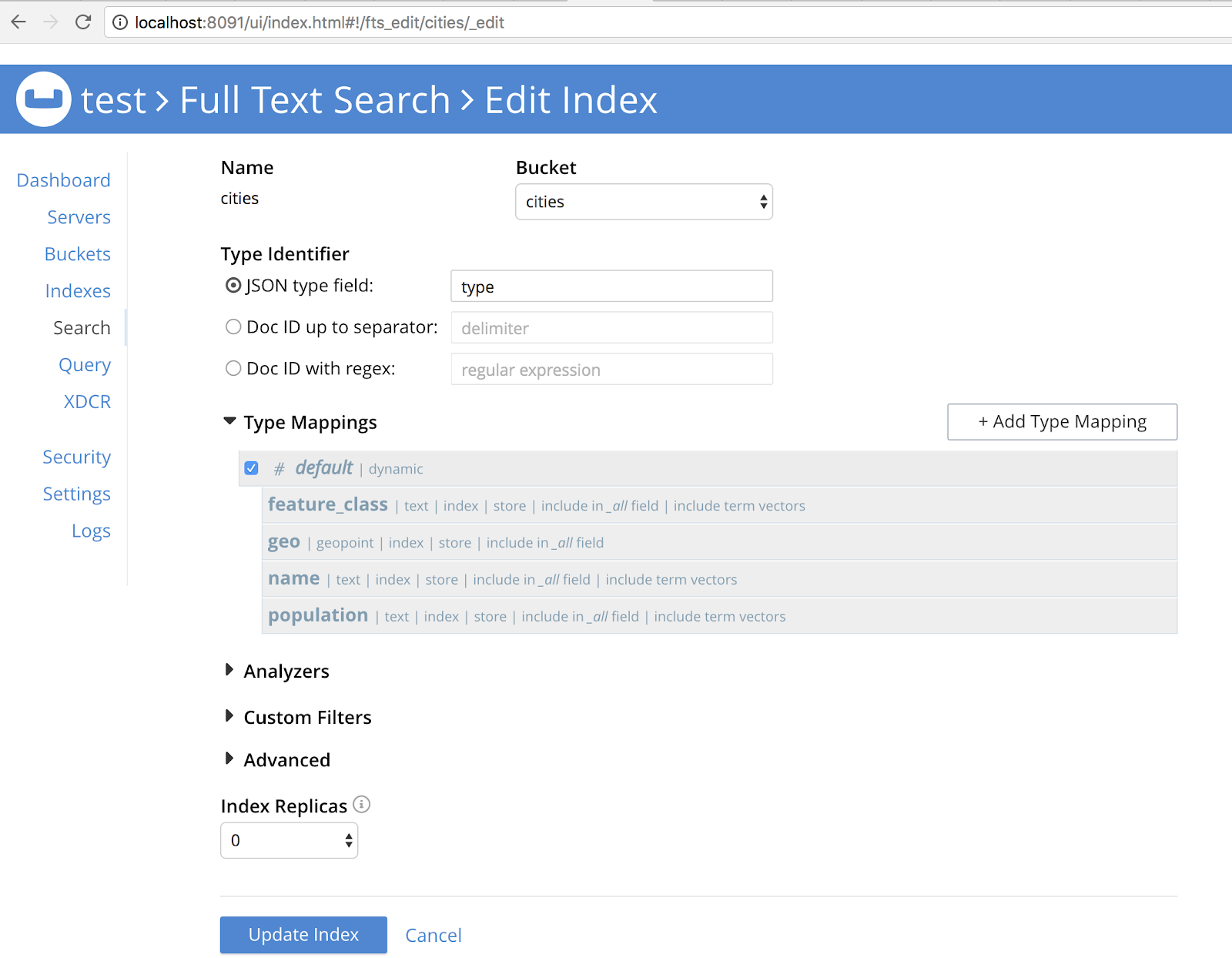
Preenchimento do Couchbase com dados
Antes de mais nada, precisamos ter dados para nosso exercício. Para isso, usaremos um banco de dados de cidades de geonames.org.
O GeoNames contém dois bancos de dados principais: lista de cidades e lista de códigos postais.
Todos estão agrupados por país com as informações correspondentes, como nome, coordenadas, população, fuso horário, código do país e assim por diante. Ambos estão no formato CSV.
Para fins deste exercício, usaremos a lista de cidades. Eu usei PL.zip mas sinta-se à vontade para escolher o que preferir da lista lista de cidades.
Modelo de dados
A classe City será nossa representação de uma única cidade que usaremos em todo o aplicativo. Ao encapsulá-la em um modelo, unificamos a API e não precisamos depender de fontes de dados de terceiros (por exemplo, arquivo CSV) que podem mudar.
A maioria dos nossos snippets está localizada (até que seja dito o contrário) no arquivo core.py. Portanto, lembre-se apenas de atualizá-lo (especialmente ao adicionar novas importações) e não substituir todo o conteúdo.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# core.py classe Cidade: def __init__(autônomo, geonameídeo, feature_class, nome, população, lat, solitário): autônomo.geonameídeo = geonameídeo autônomo.feature_class = feature_class autônomo.nome = nome autônomo.população = população autônomo.lat = lat autônomo.solitário = solitário @método de classe def from_csv_row(cls, fila): retorno cls(fila[0], fila[7], fila[1], fila[12], fila[4], fila[5]) |
Iterador de CSV para processar cidades
Como temos uma classe de modelo, é hora de preparar um iterador que nos ajudará a ler as cidades do arquivo CSV.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
# core.py importação csv de coleções importação Iterador classe CidadesCsvIterador(Iterador): def __init__(autônomo, caminho): autônomo._caminho = caminho autônomo._fp = Nenhum autônomo._csv_reader = Nenhum def __enter__(autônomo): autônomo._fp = aberto(autônomo._caminho, 'r') autônomo._csv_reader = csv.leitor(autônomo._fp, delimitador='\t') retorno autônomo def __exit__(autônomo, exc_type, exc_val, exc_tb): autônomo._fp.próximo() def __próximo__(autônomo): retorno Cidade.from_csv_row(próxima(autônomo._csv_reader)) |
Inserir cidades no bucket do Couchbase
Unificamos a maneira de representar uma cidade e temos um iterador que lê essas informações do arquivo csv.
É hora de colocar esses dados em nossa fonte de dados principal, Couchbase.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
# core.py importação registro importação sistema de couchbase.agrupamento importação Aglomerado, PasswordAuthenticator registrador = registro.getLogger() registrador.setLevel(registro.DEBUG) registrador.addHandler(registro.Gerenciador de fluxo(sistema.saída)) def get_bucket(nome de usuário, senha, connection_string='couchbase://localhost'): agrupamento = Aglomerado(connection_string) autenticador = PasswordAuthenticator(nome de usuário, senha) agrupamento.autenticar(autenticador) retorno agrupamento.open_bucket('cidades') classe CidadesServiço: def __init__(autônomo, balde): autônomo._bucket = balde def load_from_csv(autônomo, caminho): com CidadesCsvIterador(caminho) como iterador de cidades: para cidade em iterador de cidades: se cidade.feature_class não em ("PPL, 'PPLA', "PPLA2, "PPLA3, 'PPLA4', "PPLC): continuar registrador.informações(f'Inserindo {city.geonameid}') autônomo._bucket.upsert( cidade.geonameídeo, { "nome: cidade.nome, 'feature_class': cidade.feature_class, "população: cidade.população, 'geo': {'lat': flutuante(cidade.lat), 'lon': flutuante(cidade.solitário)} } ) |
Para verificar se tudo o que escrevemos até agora está funcionando, vamos carregar o conteúdo CSV no Couchbase.
|
1 2 3 4 5 |
# core.py balde = get_bucket('admin', 'test123456') cidades_serviço = CidadesServiço(balde) cidades_serviço.load_from_csv('~/diretório-com-cidades/PL/PL.txt', balde) |
Nesse ponto, você deverá ter cidades carregadas no seu bucket do Couchbase. O tempo que isso leva depende do país que você escolheu.
Pesquisar cidades
Temos nosso bucket pronto com dados, então é hora de voltar ao CitiesService e preparar alguns métodos que nos ajudariam a pesquisar cidades.
Mas antes de começarmos, precisamos modificar um pouco a classe City, adicionando o seguinte método:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# core.py @método de classe def from_couchbase_dict(cls, fila): campos = fila['campos'] retorno cls(fila['id'], campos['feature_class'], campos["nome], campos["população], campos['geo'][1], campos['geo'][0]) |
Essa é uma lista de métodos que implementaremos no CitiesService:
- get_by_name(name, limit=10), retorna cidades por seus nomes
- get_by_coordinates(lat, lon), retorna a cidade por coordenadas
- get_nearest_to_city(city, distance='10', unit='km', limit=10), retorna a cidade mais próxima
get_by_name
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# core.py de couchbase.texto completo importação TermQuery ÍNDICE_NOME = 'cidades' def get_by_name(autônomo, nome, limite=10): resultado = autônomo._bucket.pesquisa(autônomo.INDEX_NAME, TermQuery(nome.inferior(), campo="nome), limite=limite, campos='*') para c_cidade em resultado: rendimento Cidade.from_couchbase_dict(c_cidade) |
get_by_coordinates
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# core.py de couchbase.texto completo importação Consulta de distância geográfica ÍNDICE_NOME = 'cidades' def get_by_coordinates(autônomo, lat, solitário): resultado = autônomo._bucket.pesquisa(autônomo.INDEX_NAME, Consulta de distância geográfica('1km', (solitário, lat)), campos='*') para c_cidade em resultado: rendimento Cidade.from_couchbase_dict(c_cidade) |
get_nearest_to_city
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
# core.py de couchbase.texto completo importação RawQuery, SortRaw ÍNDICE_NOME = 'cidades' def get_nearest_to_city(autônomo, cidade, distância='10', unidade='km', limite=10): consulta = RawQuery({ 'localização': { 'lon': cidade.solitário, 'lat': cidade.lat }, "distância: str(distância) + unidade, 'campo': 'geo' }) classificar = SortRaw([{ "por: 'geo_distance' (distância geográfica), 'campo': 'geo', "unidade: unidade, 'localização': { 'lon': cidade.solitário, 'lat': cidade.lat } }]) resultado = autônomo._bucket.pesquisa(autônomo.INDEX_NAME, consulta, classificar=classificar, campos='*', limite=limite) para c_cidade em resultado: rendimento Cidade.from_couchbase_dict(c_cidade) |
Como você pode notar neste exemplo, usamos as classes RawQuery e SortRaw. Infelizmente, a API couchbase-python-client não funciona corretamente com o Couchbase e as pesquisas geográficas mais recentes.
Métodos de chamada
Como agora temos todos os métodos prontos, podemos chamá-lo!
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
# core.py balde = get_bucket('admin', 'test123456') cidades_serviço = CidadesServiço(balde) # cities_service.load_from_csv('/my-path/PL/PL.txt') impressão('get_by_name') cidades = cidades_serviço.get_by_name("Poznań) para cidade em cidades: impressão(cidade.__dict__) impressão('get_by_coordinates') cidades = cidades_serviço.get_by_coordinates(52.40691997632544, 16.929929926276657) para cidade em cidades: impressão(cidade.__dict__) impressão('get_nearest_to_city') cidades = cidades_serviço.get_nearest_to_city(cidade) para cidade em cidades: impressão(cidade.__dict__) |
O que fazer daqui para frente?
Acredito que essa introdução permitirá que você trabalhe em algo mais avançado.
Há algumas coisas que você pode fazer:
- Talvez usar uma ferramenta CLI ou uma API REST para fornecer esses dados... Melhorar a forma como carregamos os dados, pois pode não ser muito eficiente se quisermos carregar TODAS as cidades de TODOS os países.
Você pode encontrar o código completo do core.py em github gist.
Se você tiver alguma dúvida, não hesite em me enviar um tweet @daniel_ancuta.
Esta postagem faz parte do Programa de redação comunitária