Com o tempo, o setor de bancos de dados percebeu que a pesquisa de texto completo e o SQL são dois lados da mesma moeda. A pesquisa de texto precisa de mais processamento de consulta e o processamento de consulta precisa de pesquisa de texto para filtrar com eficiência os padrões de texto. Os bancos de dados SQL adicionaram a pesquisa de texto completo a eles, embora para sistemas SMP de nó único.
-
- O SQL Server suporta CONTAINS() para pesquisa de texto
- A Oracle oferece suporte a CONTAINS() para pesquisa de texto
- MySQL adicionado fSuporte a texto completo
- O PostgreSQL tem pesquisa de texto suportada por um longo tempo.
O Couchbase Full-Text Search (FTS) foi criado com três motivações principais:
-
- Pesquisa transparente em vários campos de um documento
- Vá além da correspondência exata de valores, fornecendo stemização baseada no idioma, correspondência difusaetc.
- Fornecer os resultados da pesquisa com base na relevância
O FTS consegue isso com um índice invertido e um rico conjunto de predicados de consultaO sistema oferece suporte à pesquisa de palavras simples, à correspondência de padrões e a predicados de intervalo complexos. Além da pesquisa, ele oferece suporte à agregação por meio de facetas de pesquisa.
No mundo NoSQL, o Lucene é um índice de pesquisa popular, assim como os servidores de pesquisa baseados no Lucene: Solr e Elasticsearch. Seguindo seus primos RDBMS, Elasticsearch, Opendistro para Elasticsearch todos adicionaram SQL em suas pesquisas. O Couchbase introduziu o serviço de texto completo, FTS e deu continuidade ao suporte para pesquisa no N1QL.
-
- FTS com N1QL
- Elasticsearch com SQL
- Opendistro para Elasticsearch com SQL
- E o MongoDB, que entrou recentemente no mercado de pesquisa, adicionou pesquisa para MQL usando o Lucene em sua oferta do Atlas.
As implementações SQL de Elasticsearch com SQL e MQL do MongoDB vem com uma longa lista de limitações.
Elasticsearch com SQL listou suas limitações aqui:
-
- Lista completa: https://www.elastic.co/guide/en/elasticsearch/reference/current/sql-limitations.html
- Além disso, o idioma é compreensivelmente limitado devido à sua implementação incipiente.
- Não há suporte para junções de operações de conjunto, etc., etc.
- Nenhuma função de janela.
MQLs do MongoDB A integração de pesquisa vem com uma longa lista de limitações.
-
- Disponível apenas no serviço de pesquisa do Atlas, não no produto local.
- A pesquisa só pode ser a PRIMEIRA operação dentro do pipeline aggregate().
- Disponível somente no pipeline de agregação (aggregate()) e não em outras operações como find(), insert(), update(), remove().
A integração com sua API aggregate() vem com algumas limitações: Ela só pode ser a primeira operação no pipeline indisponível em seu banco de dados local. Os recursos que discutimos neste artigo estão no Couchbase 6.5 e superior.
Aqui está um exemplo do N1QL:
|
1 2 3 4 5 6 7 8 9 10 11 |
SELECIONAR país, cidade, nome, ROW_NUMBER() SOBRE(ORDER BY país DESC, cidade DESC) rownum DE `viagem-amostra AS t1 ONDE t1.tipo = "hotel" E SEARCH(t1.description, "jardim") E QUALQUER r em revisões satisfaz r.ratings.Service > 3 FIM; |
Isso inclui o seguinte, além de SEARCH():
- Projeção de campos dos documentos: país, cidade, nome
- Geração de número de linha por meio da função de janela ROW_NUMBER()
- Predicado escalar adicional t1.type = "hotel"
- Predicado de matriz sobre revisões (ANY)
Você obtém o benefício COMPLETO do processamento de consultas de primeira classe, além da pesquisa eficiente. E isso não é tudo - o N1QL oferece ainda mais. Os benefícios e eficácia do SQL são bem conhecidos. N1QL é SQL para JSON. O objetivo do N1QL é oferecer aos desenvolvedores e às empresas uma linguagem expressiva, poderosa e completa para consulta, transformação e manipulação de dados JSON.
Os benefícios de usar N1QL com a pesquisa são os seguintes:
- Predicados:
- O FTS é excelente para pesquisas com base na relevância. O SQL é excelente com processamento adicional de consultas complexas: predicados complexos, predicados de matriz, escalar adicional
- Operadores e funções:
- Processamento de predicados (processamento de filtros)
- Predicados adicionais de escalar e matriz
- Funções escalares e de matriz também podem ser usadas nos predicados
- Subconsultas
- Subconsultas correlacionadas
- Subconsultas não correlacionadas
- Agregados
- Funções da janela
- Processamento de predicados (processamento de filtros)
- Processamento de JOIN
- O N1QL pode fazer INNER JOIN, LEFT OUTER JOIN, RIGHT OUTER JOIN (limitado), NEST, UNNEST
- JOINS entre compartimentos, coleções e resultados de subconsultas.
- Operações SET
- UNIÃO
- UNION ALL
- EXCETO
- EXCETO TODOS
- INTERSECÇÃO
- INTERSECTAR TUDO
- CTE (Expressão de tabela comum) e Cláusula LET para melhorar a redação de consultas
- Mais do que SEARCH()
- Além do SELECT, você pode usar o predicado SEARCH() nas cláusulas WHERE dos comandos INSERT, UPDATE, DELETE e MERGE.
- Você pode PREPARAR essas declarações e EXECUTÁ-LAS repetida e eficientemente.
- Você obtém a segurança usual por meio das funções RBAC via GRANT & REVOKE.
- Produtividade do desenvolvedor: Escreva a consulta em SQL, a linguagem que eles já conhecem.
Vamos dar uma olhada em como o mecanismo N1QL executa isso. Abhinav Dangeti, da engenharia de FTS do Couchbase, já escreveu um ótimo blog que detalha a tomada de decisões e os exemplos. Este artigo pretende explicar isso visualmente com exemplos adicionais nas categorias mencionadas acima.
1. ARQUITETURA para EXECUÇÃO DE CONSULTAS
Adicionamos três etapas importantes à execução da consulta: a consulta usa SEARCH():
- O planejador considera o índice de pesquisa do FTS um dos caminhos de acesso válidos se o predicado search() existir na consulta.
- Se o índice de pesquisa for selecionado, ele criará o plano empurrando o predicado de pesquisa para o índice FTS.
- Quando o índice de pesquisa é selecionado, o executor emite a solicitação de pesquisa para um dos nós FTS (em vez da solicitação de varredura para o serviço de índice)
- Antes que os resultados da pesquisa sejam finalizados, o serviço de consulta verifica novamente a qualificação da pesquisa do documento para os dados.
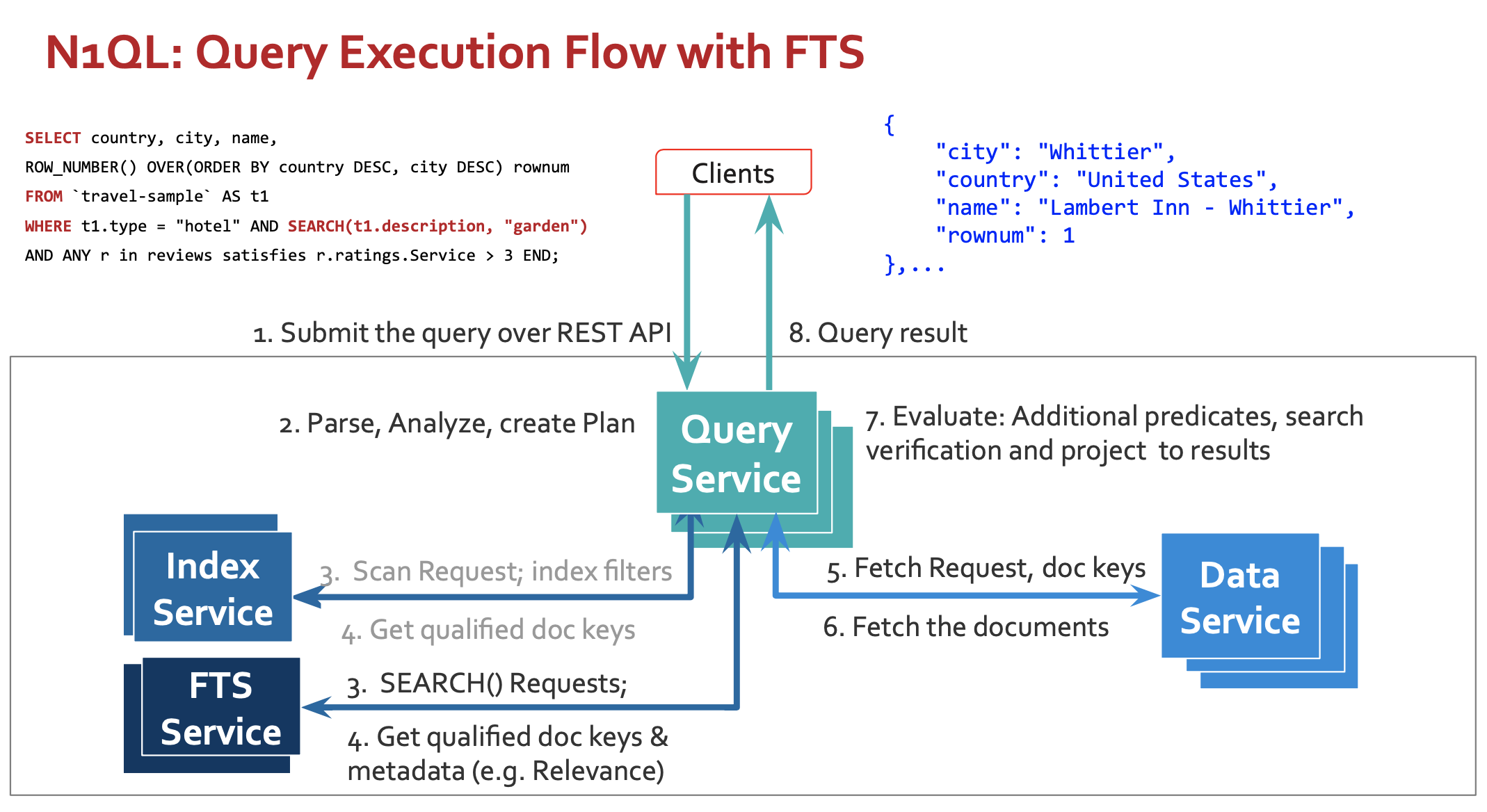
Execução de consultas N1QL com FTS
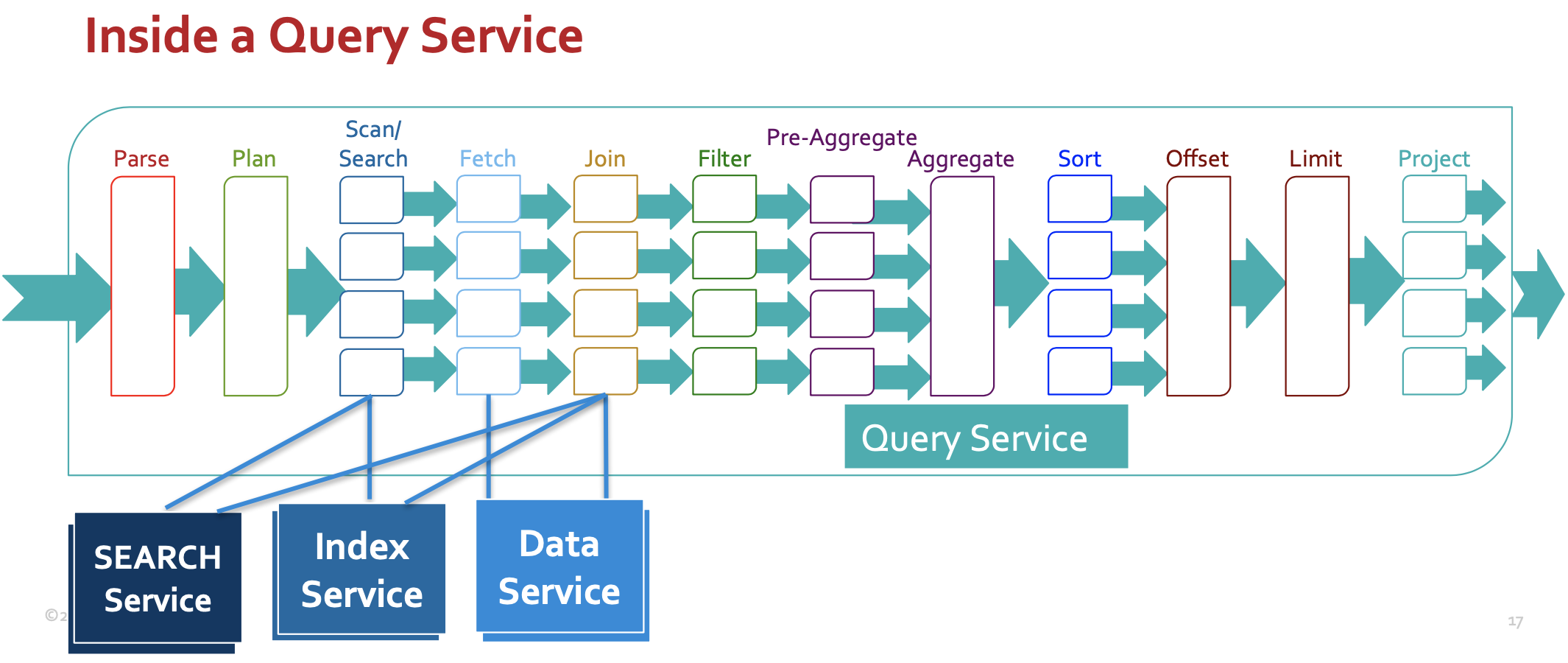
Dentro de um serviço de consulta
2. PROCESSAMENTO DE PREDICADOS
Na consulta a seguir, o predicado SEARCH() (predicado-2) é enviado para a solicitação de pesquisa do FTS. Todos os outros predicados são processados pelo mecanismo de consulta após a pesquisa na fase "Filtro", conforme mostrado na figura "Dentro de um serviço de consulta" acima. Esta é uma exceção a isso. Quando o índice FTS tiver criado um índice com Campo de tipo JSON (doc_config.type_field no documento de definição do índice) é definido (neste caso, tipo = "hotel") para criar o índice no subconjunto do documento, tanto a seleção do índice quanto o pushdown da pesquisa exploram esse predicado. Mesmo nesse caso, o predicado é reaplicado após a busca do documento.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
SELECIONAR país, cidade, nome, ROW_NUMBER() SOBRE(ORDER BY país DESC, cidade DESC) rownum DE `viagem-amostra AS t1 ONDE t1.tipo = "hotel" /* predicado-1 */ E SEARCH(t1.description, "jardim") /* predicado-2 */ E QUALQUER r em revisões satisfaz r.ratings.Service > 3 FIM; /* predicado-2 */ |
3. OPERADORES e FUNÇÕES
Aqui está um exemplo de uma consulta que explora os operadores e as funções.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
SELECIONAR INFERIOR(país), /* função escalar */ cidade, sobrenome || " " || primeiro nome AS Nome completo /* operador de string */ ROW_NUMBER() SOBRE(ORDER BY país DESC, cidade DESC) rownum /* função de janela */ DE `viagem-amostra AS t1 ONDE INFERIOR(t1.tipo) = "hotel" /* função escalar */ E SEARCH(t1.description, "jardim") E ARRAY_CONTAINS(public_likes, "Joe Black") /* Função de matriz */ |
Aqui está o plano de consulta para essa consulta. O IndexSearch faz a solicitação de pesquisa do FTS e isso é colocado em camadas no pipeline de execução da consulta. Assim, a consulta obtém o benefício de todos os outros recursos do N1QL. Isso reflete os estágios do pipeline na figura acima.
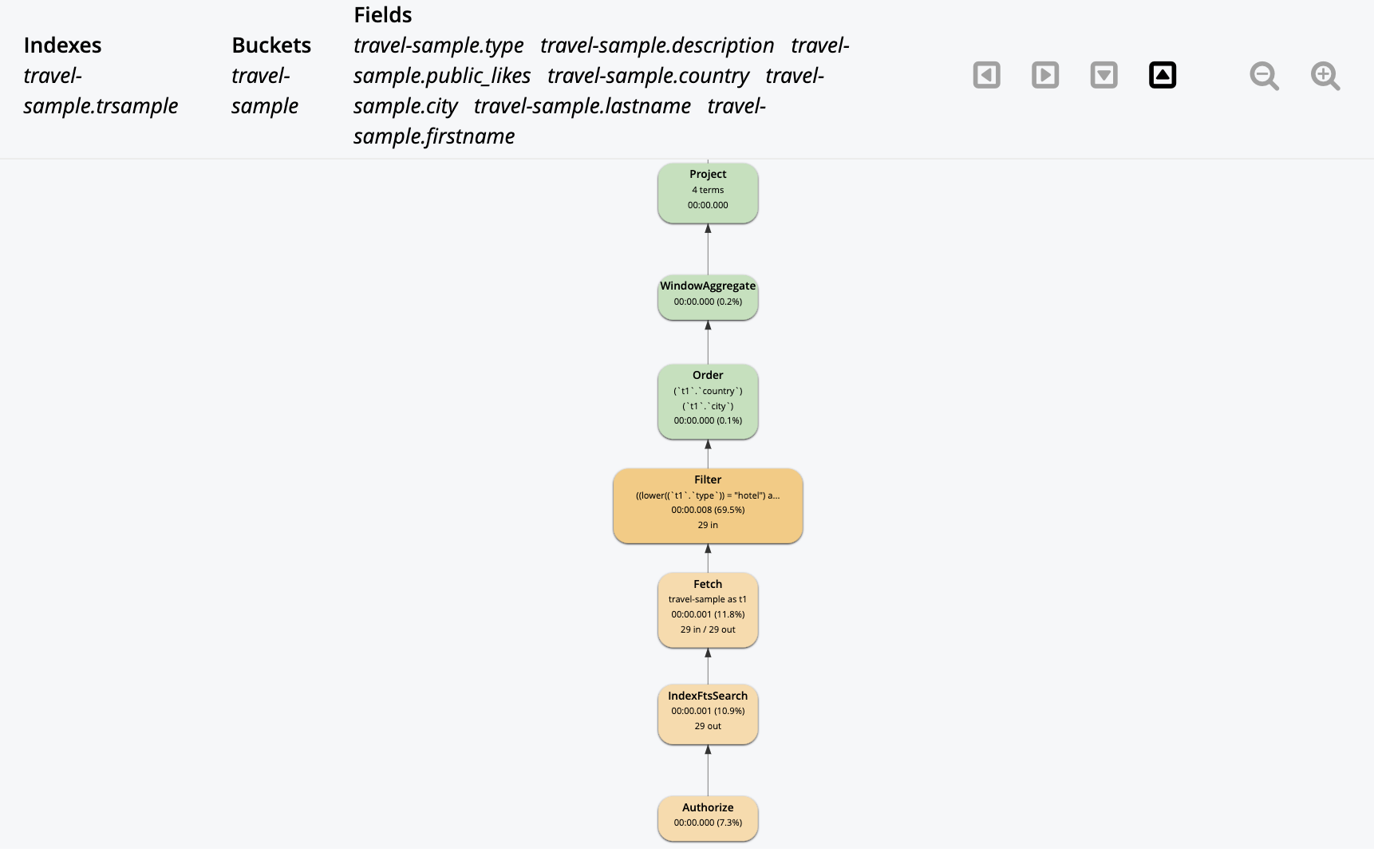
Plano de consulta com SEARCH()
4. Processamento de JOIN
O SEARCH() também pode ser usado como parte do processamento de união. Nesse caso, o FTS é usado para localizar todas as cidades que têm hotéis com jardins e, em seguida, unir-se aos aeroportos.
|
1 2 3 4 5 6 7 8 9 10 11 |
SELECIONAR hotel.name hname, aeroporto.cidade DE `viagem-amostra hotel UNIÃO EXTERNA ESQUERDA `viagem-amostra aeroporto ON hotel.city = aeroporto.cidade ONDE hotel.tipo = 'hotel' E SEARCH(hotel.description, "jardim") E aeroporto.tipo = "aeroporto ; |
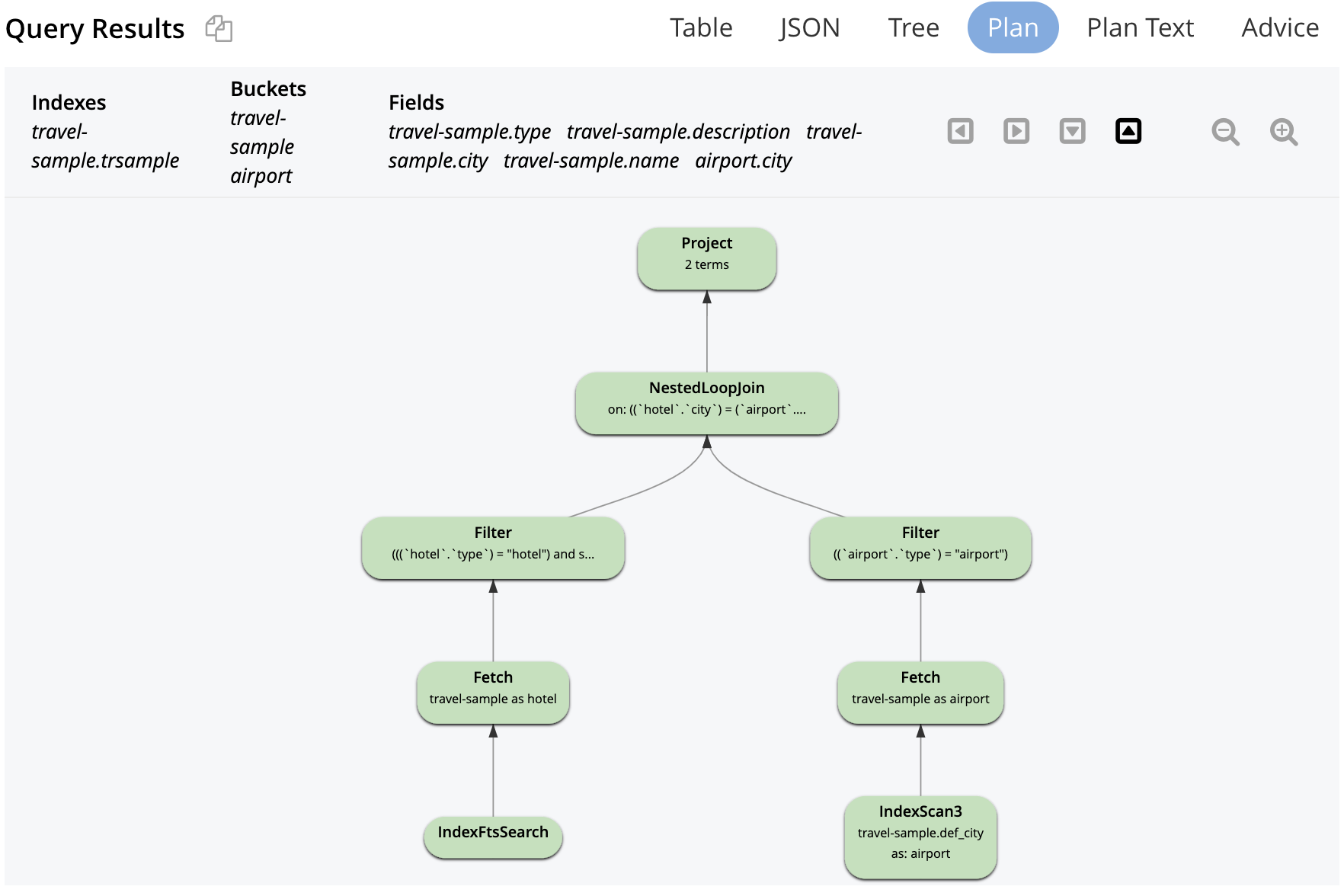
JOIN com SEARCH
5. Expressões de tabela comuns (CTEs).
O N1QL no serviço de consulta suporta CTEs não recursivos. Você pode usar SEARCH() em cada expressão. A tabela derivada dessa expressão (hotel e aeroporto) é usada como espaço-chave na consulta.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
COM hotel AS ( SELECIONAR nome, cidade DE `viagem-amostra ONDE tipo = 'hotel' E search(description, "jardim")), aeroporto AS ( SELECIONAR nome, cidade DE `viagem-amostra ONDE tipo = "aeroporto E SEARCH(city, "angeles")) SELECIONAR hotel.name hname, aeroporto.cidade DE hotel INNER JOIN aeroporto ON hotel.city = aeroporto.cidade ORDER BY aeroporto.cidade, hotel.name; |
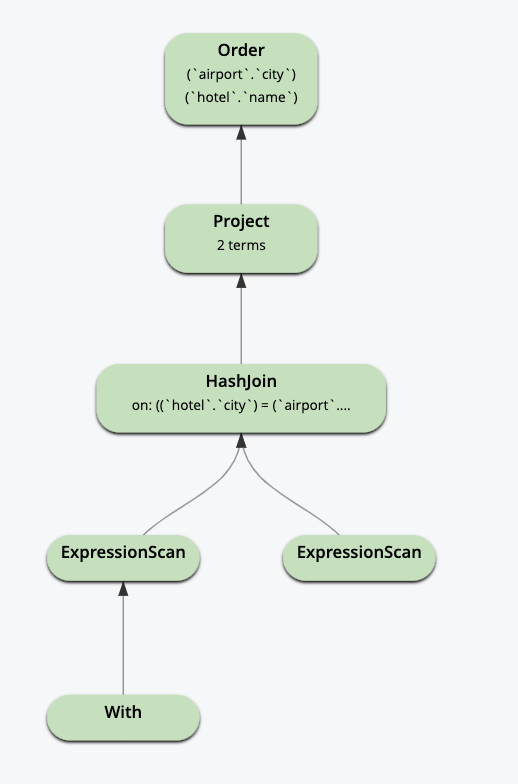
5. Uso em UPDATEs
SEARCH() pode ser usado em qualquer lugar onde um predicado é permitido em outras instruções DML.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
/* INSERIR EM... Declaração SELECT. */ INSERIR PARA meu cesto (CHAVE id, VALORES v) SELECIONAR meta().id id, v DE `viagem-amostra v ONDE SEARCH(v, "+tipo:hotel +descrição:limpo"); /* Declaração DELETE */ DELETE DE `viagem-amostra ONDE SEARCH(v, "+tipo:hotel +descrição:limpo"); /* Declaração UPDATE */ ATUALIZAÇÃO `viagem-amostra CONJUNTO novo_campo = "Pesquisar e atualizar!" ONDE SEARCH(v, "+tipo:hotel +descrição:limpo"); |
Os exemplos podem fluir por muito tempo. Mostrei exemplos comuns. Você usa isso em várias instruções SQL (DMLs)
Conclusão:
O Couchbase FTS fornece um mecanismo de pesquisa de texto distribuído e dimensionável. Nós o incorporamos perfeitamente ao N1QL no serviço Couchbase Query para que você tenha todo o poder das consultas com todo o poder da pesquisa. Há mais inovações sobre isso em andamento. Fique ligado!