Novo cache padrão, semântico e de conversação com integração LangChain
No cenário em rápida evolução do desenvolvimento de aplicativos de IA, a integração de grandes modelos de linguagem (LLMs) com fontes de dados corporativos tornou-se um foco essencial. A capacidade de aproveitar o poder dos LLMs para gerar respostas de alta qualidade e contextualmente relevantes está transformando vários setores. No entanto, as equipes enfrentam desafios significativos para fornecer respostas confiáveis em alta velocidade e, ao mesmo tempo, reduzir os custos, especialmente à medida que o volume de solicitações dos usuários aumenta. Além disso, como a maioria dos LLMs tem memória limitada, existe a oportunidade de armazenar as conversas dos LLMs por um período de tempo prolongado e evitar que os usuários recomecem do zero quando a memória de um LLM se esgotar.
O Couchbase, líder em armazenamento em cache altamente dimensionável e de baixa latência (Leia a história do LinkedIn), enfrenta esses desafios com soluções inovadoras. Novos aprimoramentos em nossa oferta de pesquisa vetorial e cache, bem como um pacote LangChain dedicado para desenvolvedores, facilitam a elevação do desempenho e da confiabilidade dos aplicativos de IA generativa.
Couchbase Vector Search e Retrieval-Augmented Generation (RAG)
A pesquisa vetorial do Couchbase permite que os usuários encontrem objetos semelhantes sem a necessidade de uma correspondência exata. Trata-se de um recurso avançado que permite a busca e a recuperação eficientes de dados com base em incorporações vetoriais, que são representações matemáticas de objetos em um número muito grande de dimensões. Por exemplo, a busca de sapatos "marrom" e "couro" em um catálogo de produtos retornaria esses resultados, bem como sapatos de "camurça", com cores que incluem "mogno, castanho, café, bronze, castanho-avermelhado e cacau".
O Retrieval-Augmented Generation (RAG) combina a pesquisa vetorial, recuperando informações do banco de dados do Couchbase relacionadas ao prompt do usuário, e fornece o prompt e as informações relacionadas relevantes. informações a um modelo generativo para produzir respostas de LLM mais informadas e contextualmente apropriadas. Isso geralmente é mais rápido e menos dispendioso do que treinar um modelo personalizado. O arquitetura na memória altamente dimensionável fornece acesso rápido e eficiente à pesquisa de dados relevantes de incorporação de vetores. Para tornar um aplicativo RAG mais eficiente e com melhor desempenho, os desenvolvedores podem usar recursos de cache semântico e de conversação.
Cache semântico
O armazenamento em cache semântico é uma técnica sofisticada de armazenamento em cache que usa embeddings de vetor para entender o contexto e a intenção por trás das consultas. Ao contrário dos métodos tradicionais de armazenamento em cache que dependem de correspondências exatas, o armazenamento em cache semântico aproveita o significado e a relevância dos dados. Isso significa que perguntas semelhantes, que de outra forma receberiam a mesma resposta de um LLM, não precisam fazer solicitações adicionais ao LLM. Continuando com o exemplo acima, um usuário que pesquisa "Estou procurando sapatos de couro marrom no tamanho 10" obteria os mesmos resultados que outro usuário que solicita "Quero comprar sapatos tamanho 10 em couro na cor marrom".

Os benefícios do cache semântico, especialmente em volumes maiores, incluem:
- Melhoria da eficiência - Tempos de recuperação mais rápidos devido à compreensão do contexto da consulta
- Custos mais baixos - A redução de chamadas para o LLM economiza tempo e dinheiro
Cache de conversação
Enquanto o cache semântico reduz o número de chamadas para um LLM em uma ampla variedade de usuários, um cache de conversação melhora a experiência geral do usuário, ampliando o conhecimento de conversação das interações entre o usuário e o LLM. Ao aproveitar o histórico de perguntas e respostas, o LLM é capaz de fornecer um contexto melhor à medida que novas solicitações são enviadas.
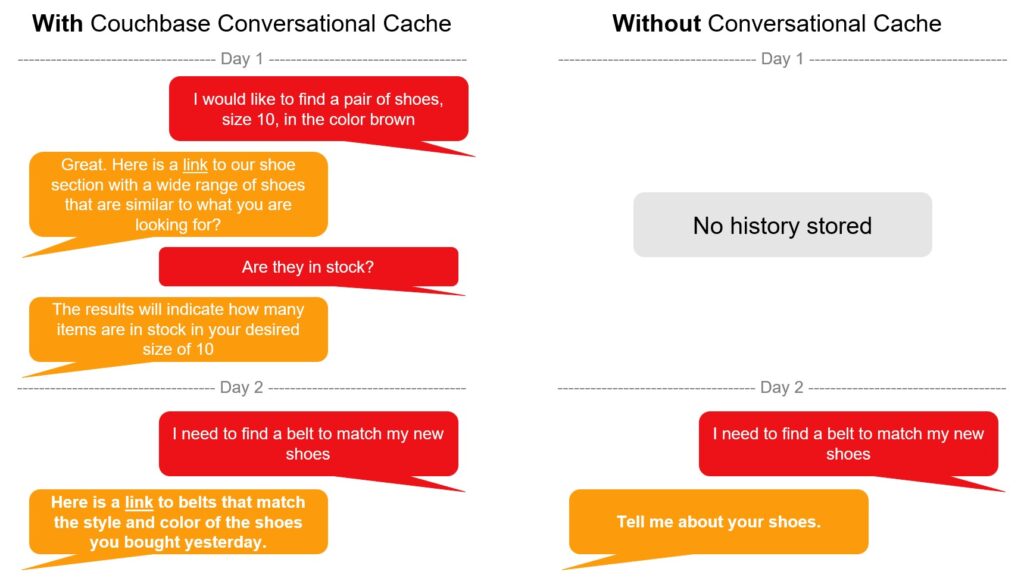
Além disso, o cache de conversação pode ser usado para ajudar a aplicar o raciocínio aos fluxos de trabalho dos agentes de IA. Um usuário pode perguntar: "Este item funcionará bem com meus produtos comprados anteriormente?" Primeiro, isso exige a resolução da referência "este item", seguida do raciocínio de como determinar se ele funcionará bem com as compras anteriores."
Pacotes dedicados de LangChain-Couchbase
A Couchbase apresentou recentemente os módulos LangChain projetados para desenvolvedores Python. Esse pacote simplifica a integração dos recursos avançados do Couchbase em aplicativos de IA generativa via LangChain, facilitando para os desenvolvedores a implementação de recursos poderosos, como pesquisa vetorial e cache semântico.
O pacote LangChain-Couchbase integra perfeitamente os recursos de pesquisa vetorial, cache semântico e cache de conversação do Couchbase em fluxos de trabalho de IA generativa. Essa integração permite que os desenvolvedores criem aplicativos mais inteligentes e sensíveis ao contexto com o mínimo de esforço.
Ao fornecer um pacote dedicado, o Couchbase garante que os desenvolvedores possam acessar e implementar facilmente recursos avançados sem lidar com configurações complexas. O pacote foi projetado para ser amigável ao desenvolvedor, permitindo uma integração rápida e eficiente.
Principais recursos
O pacote LangChain-Couchbase oferece vários recursos importantes, incluindo:
-
- Pesquisa vetorial - Recuperação eficiente de dados com base em embeddings de vetores
- Cache padrão - Para obter correspondências exatas mais rápidas
- Cache semântico - Cache com reconhecimento de contexto para melhorar a relevância da resposta
- Cache de conversação - Gerenciamento do contexto da conversa para aprimorar as interações do usuário
Casos de uso e exemplos
Os novos aprimoramentos do Couchbase podem ser aplicados em vários cenários, como:
-
- Chatbots de comércio eletrônico - Fornecimento de recomendações de compras personalizadas com base nas preferências do usuário
- Suporte ao cliente - Fornecer respostas precisas e contextualmente relevantes às consultas dos clientes
Trechos de código ou tutoriais
Os desenvolvedores podem encontrar trechos de código e tutoriais para implementar o cache semântico e o pacote LangChain-Couchbase em Site da LangChain. Há também exemplos de código de pesquisa vetorial no site do Couchbase Repositório do GitHub. Esses recursos fornecem orientação para ajudar os desenvolvedores a começar rapidamente.
Benefícios
Os aprimoramentos do Couchbase nas ofertas de pesquisa vetorial e armazenamento em cache para aplicativos baseados em LLM proporcionam vários benefícios, incluindo maior eficiência, relevância e personalização das respostas. Esses recursos foram projetados para enfrentar os desafios de criar aplicativos de IA geradores confiáveis, dimensionáveis e econômicos.
O Couchbase está comprometido com a inovação contínua, garantindo que nossa plataforma permaneça na vanguarda do desenvolvimento de aplicativos de IA. Os aprimoramentos futuros expandirão ainda mais os recursos do Couchbase, permitindo que os desenvolvedores criem aplicativos ainda mais avançados e inteligentes.
Recursos adicionais
-
- Blog: Uma visão geral do RAG
- Documentos: Instalar a integração Langchain-Couchbase
- Documentos: Couchbase como armazenamento vetorial com LangChain
- Vídeo: Pesquisa vetorial e híbrida
- Vídeo: Vector Search para aplicativos móveis
- Documentos: Pesquisa de vetores no Capella DBaaS
- Modelos suportados pelo LangChain e pelo Couchbase
