Aaron Benton é um arquiteto experiente, especializado em soluções criativas para desenvolver aplicativos móveis inovadores. Ele tem mais de 10 anos de experiência em desenvolvimento de pilha completa, incluindo ColdFusion, SQL, NoSQL, JavaScript, HTML e CSS. Atualmente, Aaron é Arquiteto de Aplicativos da Shop.com em Greensboro, Carolina do Norte, e é um Campeão da comunidade do Couchbase.

FakeIt Série 2 de 5: Dados compartilhados e dependências
Em FakeIt Série 1 de 5: Geração de dados falsos aprendemos que a FakeIt pode gerar uma grande quantidade de dados aleatórios com base em um único arquivo YAML e enviar os resultados para vários formatos e destinos, incluindo o Couchbase Server. Hoje vamos explorar o que torna a FakeIt realmente única e poderosa no mundo da geração de dados.
Há muitos geradores de dados aleatórios disponíveis, um simples Pesquisa do Google lhe darão mais do que o suficiente para escolher. No entanto, quase todos eles têm a mesma falha frustrante, que é o fato de só poderem lidar com um único modelo. Raramente, como desenvolvedores, temos o luxo de lidar com um único modelo; na maioria das vezes, estamos desenvolvendo vários modelos para nossos projetos. É nesse ponto que o FakeIt se destaca: ele permite vários modelos e que esses modelos tenham dependências.
Vamos dar uma olhada nos possíveis modelos que teremos em nosso aplicativo de comércio eletrônico:
- Usuários
- Produtos
- Carrinho
- Pedidos
- Comentários
Usuários, o primeiro modelo que definimos, não tem nenhuma dependência, e o mesmo pode ser dito do modelo Produtos, que definiremos a seguir. No entanto, seria lógico dizer que o nosso modelo Orders dependeria dos modelos Users e Products. Se realmente quisermos dados de teste, os documentos criados pelo nosso modelo Orders deverão ser os dados aleatórios reais gerados pelos modelos Users e Products.
Modelo de produtos
Antes de analisarmos como as dependências de modelo funcionam na FakeIt, vamos definir como será o nosso modelo de produtos.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 |
nome: Produtos tipo: objeto chave: _id propriedades: _id: tipo: string descrição: O documento id dados: post_build: `produto_${este.product_id}` tipo de documento: tipo: string descrição: O documento tipo dados: valor: produto product_id: tipo: string descrição: Único identificador representando a específico produto dados: construir: falsificador.aleatório.uuid() preço: tipo: duplo descrição: O produto preço dados: construir: chance.flutuante({ min: 0, máximo: 150, fixo: 2 }) preço de venda: tipo: duplo descrição: O produto preço dados: post_build: | deixar preço de venda = 0; se (chance.bool({ probabilidade: 30 })) { preço de venda = chance.flutuante({ min: 0, máximo: este.preço * chance.flutuante({ min: 0, máximo: 0.99, fixo: 2 }), fixo: 2 }); } retorno preço de venda; nome_de_exibição: tipo: string descrição: Tela nome de produto. dados: construir: falsificador.comércio.productName() short_description: tipo: string descrição: Descrição de produto. dados: construir: falsificador.lorem.parágrafos(1) long_description: tipo: string descrição: Descrição de produto. dados: construir: falsificador.lorem.parágrafos(5) palavras-chave: tipo: matriz descrição: Um matriz de palavras-chave itens: tipo: string dados: min: 0 máximo: 10 construir: falsificador.aleatório.palavra() disponibilidade: tipo: string descrição: O disponibilidade status de o produto dados: construir: | deixar disponibilidade = 'Em estoque'; se (chance.bool({ probabilidade: 40 })) { disponibilidade = falsificador.aleatório.arrayElement([ 'Pré-encomenda', "Fora de estoque, "Descontinuado ]); } retorno disponibilidade; data_disponibilidade: tipo: inteiro descrição: Um época tempo de quando o produto é disponível dados: construir: falsificador.data.recente() post_build: novo Data(este.data_disponibilidade).getTime() produto_slug: tipo: string descrição: O URL amigável versão de o produto nome dados: post_build: falsificador.ajudantes.slugify(este.nome_de_exibição).toLowerCase() categoria: tipo: string descrição: Categoria para o Produto dados: construir: falsificador.comércio.departamento() categoria_slug: tipo: string descrição: O URL amigável versão de o categoria nome dados: post_build: falsificador.ajudantes.slugify(este.categoria).toLowerCase() imagem: tipo: string descrição: Imagem URL representando o produto. dados: construir: falsificador.imagem.imagem() alternate_images: tipo: matriz descrição: Um matriz de alternativo imagens para o produto itens: tipo: string dados: min: 0 máximo: 4 construir: falsificador.imagem.imagem() |
Esse modelo é um pouco mais complexo do que o modelo anterior de Usuários. Vamos examinar algumas dessas propriedades em mais detalhes:
- _id: Esse valor está sendo definido depois que cada propriedade do documento foi criada e está disponível para a função de pós-compilação. Esse contexto é o do documento atual que está sendo gerado
- preço de venda: Para isso, é necessário definir uma chance de preço de venda e, se houver um preço de venda, garantir que o valor seja menor do que o da propriedade de preço
- palavras-chave: É uma matriz. Definido de forma semelhante ao Swagger, definimos nossos itens de matriz e como queremos que eles sejam construídos usando as funções build / post_build. Além disso, podemos definir os valores mínimo e máximo, e o FakeIt gerará um número aleatório de elementos de matriz entre esses valores. Há também uma propriedade fixa que pode ser usada para gerar um número definido de elementos de matriz.
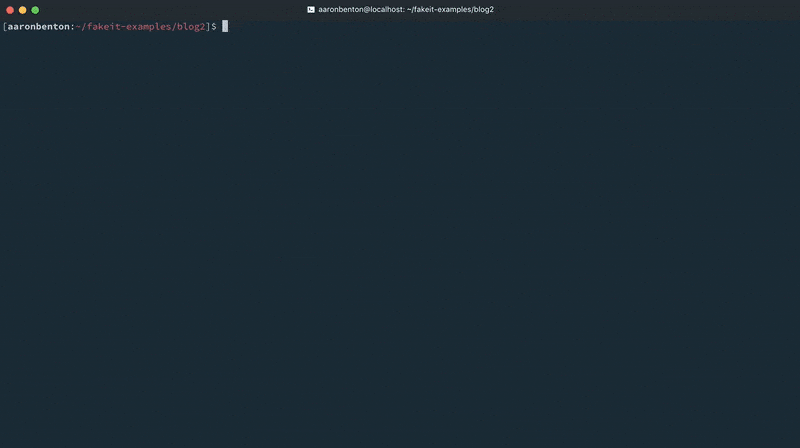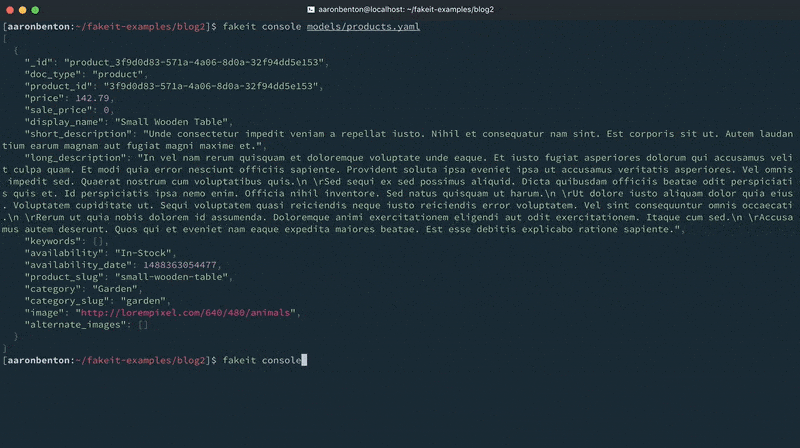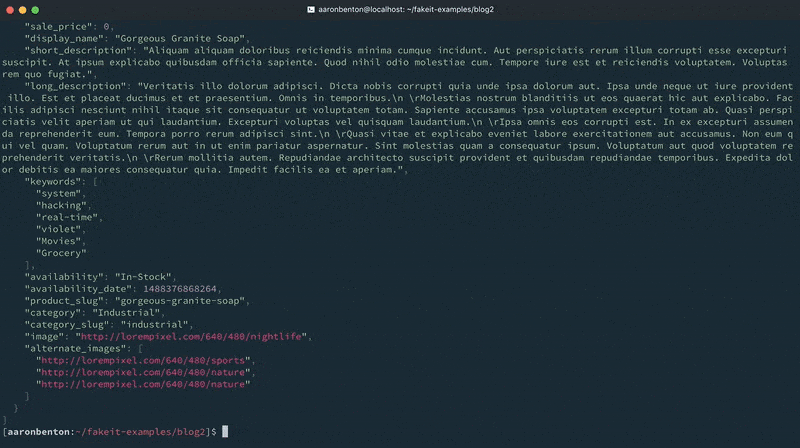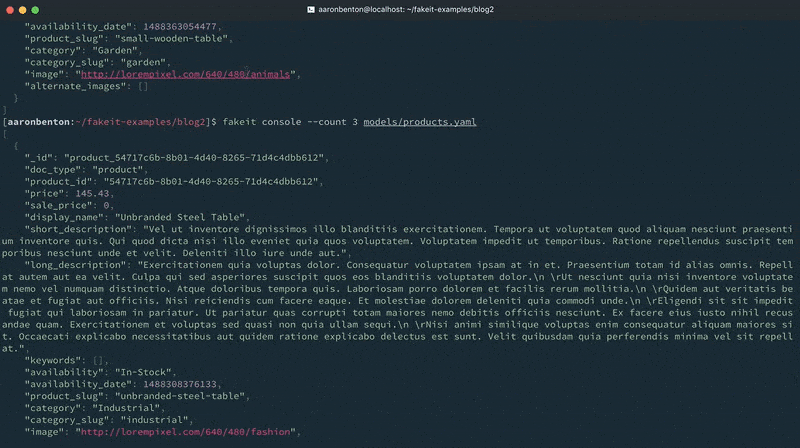
Agora que construímos nosso modelo de produtos, vamos gerar alguns dados aleatórios e enviá-los ao console para ver como eles se parecem usando o comando:
|
1 |
falso console modelos/produtos.yaml |
Modelo de pedidos
Para nosso projeto, já definimos os seguintes modelos:
- users.yaml
- produtos.yaml
Vamos começar definindo o modelo Orders sem nenhuma propriedade e especificando suas dependências:
|
1 2 3 4 5 6 7 8 |
nome: Pedidos tipo: objeto chave: _id dados: dependências: - produtos.yaml - usuários.yaml propriedades: |
Definimos duas dependências para o nosso modelo Orders e as referenciamos pelo nome do arquivo. Como todos os nossos modelos são armazenados no mesmo diretório, não há motivo para especificar o caminho completo. No tempo de execução, a FakeIt analisará primeiro todos os modelos antes de tentar gerar documentos e determinará uma ordem de execução com base em cada uma das dependências dos modelos (se houver).
Cada uma das funções de compilação em um modelo FakeIt é um corpo de função, com os seguintes argumentos passados a ele.
|
1 2 3 |
função (documentos, globais, insumos, falsificador, chance, índice_documento, exigir) { retorno falsificador.Internet.nome de usuário(); } |
Depois que a ordem de execução é estabelecida, cada uma das dependências é salva na memória e disponibilizada para o modelo dependente por meio do argumento documents. Esse argumento é um objeto que contém uma chave para cada modelo, cujo valor é uma matriz de cada documento que foi gerado. Para o nosso exemplo da propriedade documents, a aparência será semelhante a esta:
|
1 2 3 4 5 6 7 8 |
{ "Usuários": [ ... ], "Produtos": [ ... ] } |
Podemos tirar proveito disso para recuperar documentos aleatórios de produtos e usuários, atribuindo suas propriedades às propriedades do nosso modelo Orders. Por exemplo, podemos recuperar um user_id aleatório dos documentos gerados pelo modelo Users e atribuí-lo ao user_id do modelo Orders por meio de uma função de compilação
|
1 2 3 4 5 |
user_id: tipo: inteiro descrição: O user_id que colocado o ordem dados: construir: falsificador.aleatório.arrayElement(documentos.Usuários).user_id; |
Vamos definir como será o restante do nosso modelo de Orders:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 |
nome: Pedidos tipo: objeto chave: _id dados: dependências: - produtos.yaml - usuários.yaml propriedades: _id: tipo: string descrição: O documento id dados: post_build: `ordem_${este.order_id}` tipo de documento: tipo: string descrição: O documento tipo dados: valor: "ordem" order_id: tipo: inteiro descrição: O ordem_id dados: construir: índice_documento + 1 user_id: tipo: inteiro descrição: O user_id que colocado o ordem dados: construir: falsificador.aleatório.arrayElement(documentos.Usuários).user_id; data_do_pedido: tipo: inteiro descrição: Um época tempo de quando o ordem foi colocado dados: construir: novo Data(falsificador.data.passado()).getTime() status do pedido: tipo: string descrição: O status de o ordem dados: construir: falsificador.aleatório.arrayElement([ "Pendente, "Processamento, "Cancelado, 'Enviado' ]) nome_do_faturamento: tipo: string descrição: O nome de o pessoa o ordem é para ser faturado para dados: construir: `${falsificador.nome.firstName()} ${falsificador.nome.lastName()}` billing_phone: tipo: string descrição: O faturamento telefone dados: construir: falsificador.telefone.número de telefone().substituir(/x[0-9]+$/, '') billing_email: tipo: string descrição: O faturamento e-mail dados: construir: falsificador.Internet.e-mail() endereço_de_faturamento_1: tipo: string descrição: O faturamento endereço 1 dados: construir: `${falsificador.endereço.streetAddress()} ${falsificador.endereço.streetSuffix()}` endereço_de_faturamento_2: tipo: string descrição: O faturamento endereço 2 dados: construir: chance.bool({ probabilidade: 50 }) ? falsificador.endereço.secondaryAddress() : nulo billing_locality: tipo: string descrição: O faturamento cidade dados: construir: falsificador.endereço.cidade() billing_region: tipo: string descrição: O faturamento região, cidade, província dados: construir: falsificador.endereço.stateAbbr() billing_postal_code: tipo: string descrição: O faturamento zíper código / postal código dados: construir: falsificador.endereço.código postal() país_de_faturamento: tipo: string descrição: O faturamento região, cidade, província dados: valor: EUA nome_da_empresa: tipo: string descrição: O nome de o pessoa o ordem é para ser faturado para dados: construir: `${falsificador.nome.firstName()} ${falsificador.nome.lastName()}` endereço_de_envio_1: tipo: string descrição: O transporte endereço 1 dados: construir: `${falsificador.endereço.streetAddress()} ${falsificador.endereço.streetSuffix()}` endereço_de_envio_2: tipo: string descrição: O transporte endereço 2 dados: construir: chance.bool({ probabilidade: 50 }) ? falsificador.endereço.secondaryAddress() : nulo shipping_locality: tipo: string descrição: O transporte cidade dados: construir: falsificador.endereço.cidade() shipping_region: tipo: string descrição: O transporte região, cidade, província dados: construir: falsificador.endereço.stateAbbr() shipping_postal_code: tipo: string descrição: O transporte zíper código / postal código dados: construir: falsificador.endereço.código postal() país_de_envio: tipo: string descrição: O transporte região, cidade, província dados: valor: EUA shipping_method: tipo: string descrição: O transporte método dados: construir: falsificador.aleatório.arrayElement([ 'USPS', 'Padrão UPS', 'UPS Ground', 'UPS 2nd Day Air', 'UPS Next Day Air', FedEx Ground, 'FedEx 2Day Air', 'FedEx Standard Overnight' ]); shipping_total: tipo: duplo descrição: O transporte total dados: construir: chance.dólar({ min: 10, máximo: 50 }).fatia(1) imposto: tipo: duplo descrição: O imposto total dados: construir: chance.dólar({ min: 2, máximo: 10 }).fatia(1) itens_linha: tipo: matriz descrição: O produtos que foram encomendado itens: tipo: string dados: min: 1 máximo: 5 construir: | const aleatório = falsificador.aleatório.arrayElement(documentos.Produtos); const produto = { product_id: aleatório.product_id, nome_de_exibição: aleatório.nome_de_exibição, short_description: aleatório.short_description, imagem: aleatório.imagem, preço: aleatório.preço de venda || aleatório.preço, quantidade: falsificador.aleatório.número({ min: 1, máximo: 5 }), }; produto.sub_total = produto.quantidade * produto.preço; retorno produto; grand_total: tipo: duplo descrição: O grande total de o ordem dados: post_build: | deixar total = este.imposto + este.shipping_total; para (deixar i = 0; i < este.itens_linha.comprimento; i++) { total += este.itens_linha[i].sub_total; } retorno chance.dólar({ min: total, máximo: total }).fatia(1); |
E envie-o para o console usando o comando:
|
1 |
falso console modelos/pedidos.yaml |
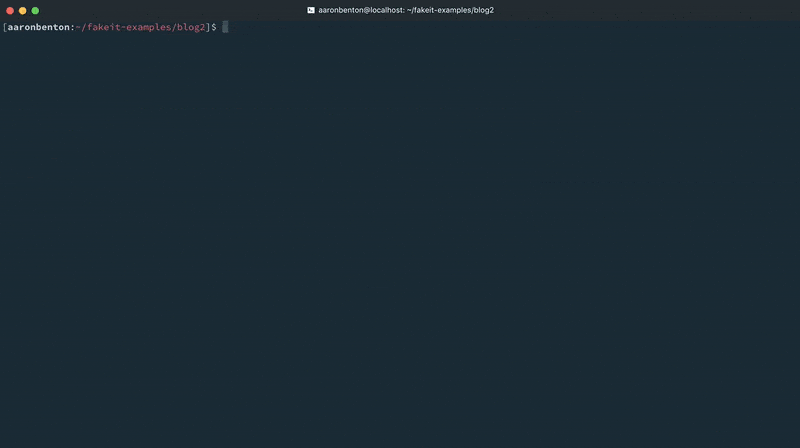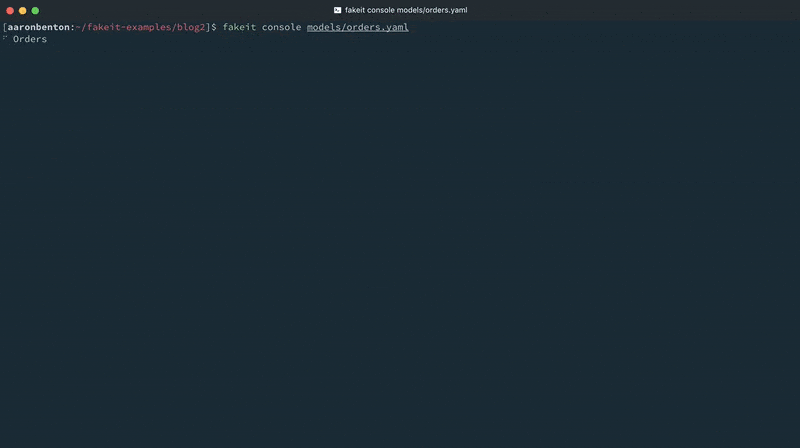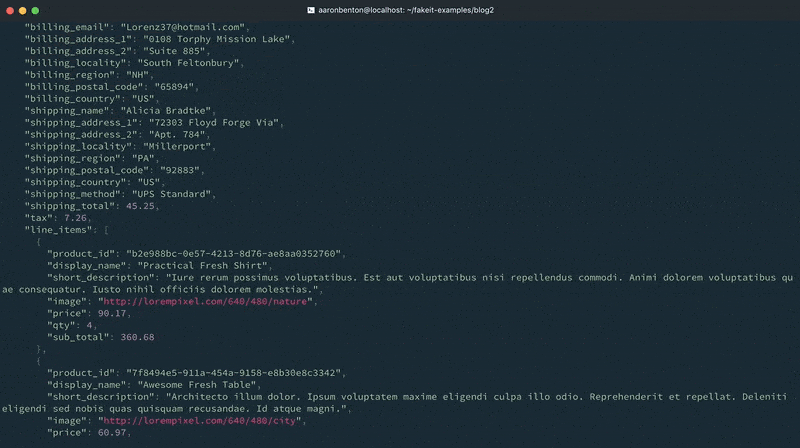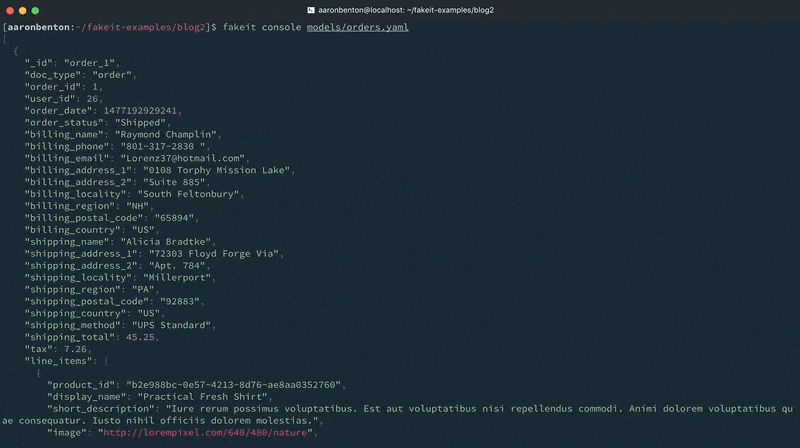
Como você pode ver na saída do console, os documentos foram gerados para os modelos Usuários e Produtos, e esses documentos foram disponibilizados para o modelo Pedidos. No entanto, eles foram excluídos da saída porque tudo o que foi solicitado para saída foi o modelo Orders.
Agora que definimos três modelos com dependências (Usuários, Produtos e Pedidos), precisamos ser capazes de gerar vários documentos para cada um deles e enviá-los ao Couchbase Server. Até este ponto, especificamos o número de documentos a serem gerados por meio do argumento de linha de comando -count. Podemos especificar o número de documentos ou um intervalo de documentos usando a propriedade data: na raiz do modelo.
|
1 2 3 4 5 6 7 8 |
usuários.yaml nome: Usuários tipo: objeto chave: _id dados: min: 1000 máximo: 2000 |
|
1 2 3 4 5 6 7 8 |
produtos.yaml nome: Produtos tipo: objeto chave: _id dados: min: 4000 máximo: 5000 |
|
1 2 3 4 5 6 7 8 9 10 11 |
pedidos.yaml nome: Pedidos tipo: objeto chave: _id dados: dependências: - produtos.yaml - usuários.yaml min: 5000 máximo: 6000 |
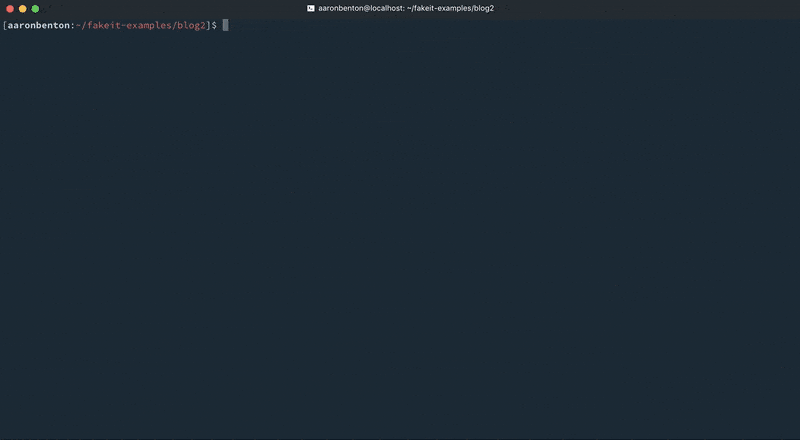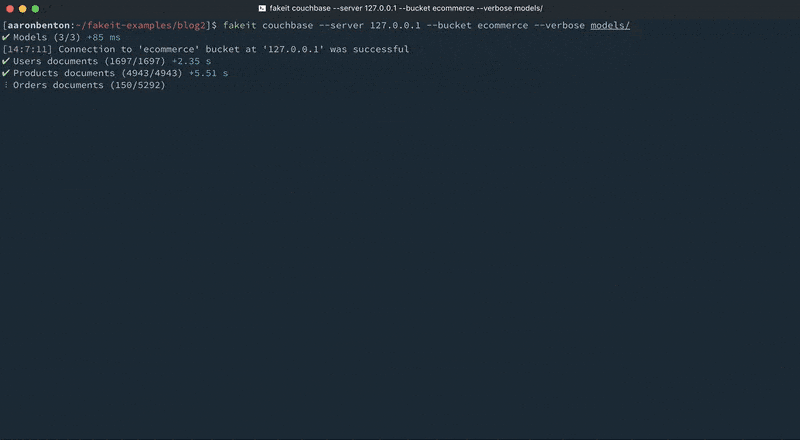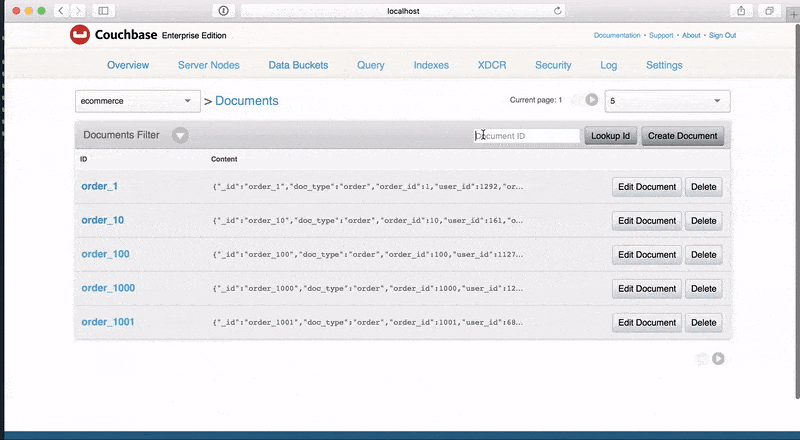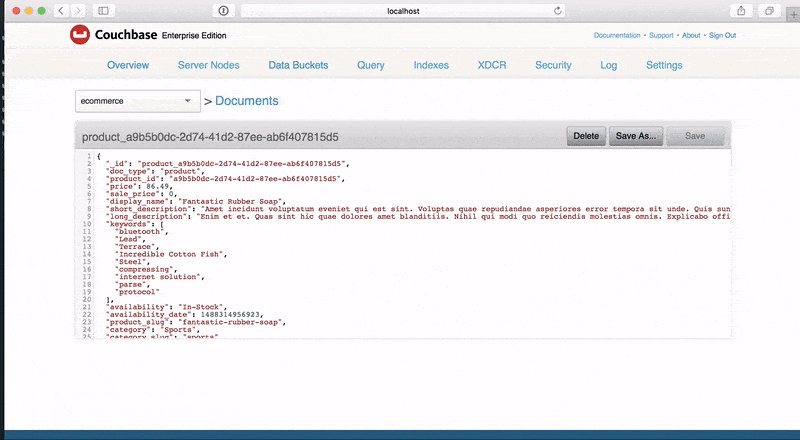
Agora podemos gerar conjuntos aleatórios de modelos de documentos relacionados e enviar esses documentos diretamente para o Couchbase Server usando o comando:
|
1 |
falso couchbase --servidor 127.0.0.1 --balde comércio eletrônico --detalhado modelos/ |
Conclusão
Vimos, por meio de três modelos simples do FakeIt YAML, como podemos criar dependências de modelos, permitindo que dados gerados aleatoriamente sejam relacionados entre modelos e transmitidos para o Couchbase Server. Também vimos como podemos especificar o número de documentos a serem gerados por modelo usando a propriedade data: na raiz de um modelo.
Esses modelos podem ser armazenados no repositório de projetos, ocupando muito pouco espaço e permitindo que os desenvolvedores gerem as mesmas estruturas de dados com dados completamente diferentes. Outra vantagem de poder gerar documentos por meio de relacionamentos de vários modelos é explorar diferentes modelos de documentos e ver o desempenho deles com várias consultas N1QL.
Próximo
- Série FakeIt 3 de 5: Modelos Lean por meio de definições
- FakeIt Série 4 de 5: Trabalhando com dados existentes
- FakeIt Series 5 de 5: Desenvolvimento móvel rápido com o Sync-Gateway
Anterior
- FakeIt Série 1 de 5: Geração de dados falsos
 Esta postagem faz parte do Programa de Redação da Comunidade Couchbase
Esta postagem faz parte do Programa de Redação da Comunidade Couchbase
[...] em nosso post anterior FakeIt Series 2 of 5: Shared Data and Dependencies, vimos como criar dependências de vários modelos com o FakeIt. Hoje, [...]
[...] até agora, em nossa série FakeIt, vimos como podemos gerar dados falsos, compartilhar dados e dependências e usar definições para modelos menores. Hoje vamos dar uma olhada no último recurso importante do [...]