O que são modelos de incorporação?
Os modelos de incorporação são um tipo de modelo de aprendizado de máquina projetado para representar dados (como texto, imagens ou outras formas de informação) em um espaço vetorial contínuo e de baixa dimensão. Esses incorporações capturam semelhanças semânticas ou contextuais entre partes de dados, permitindo que as máquinas executem tarefas como comparação, agrupamento ou classificação de forma mais eficaz.
Imagine que você queira descrever diferentes frutas. Em vez de descrições longas, você usa números para características como doçura, tamanho e cor. Por exemplo, uma maçã pode ser [8, 5, 7], enquanto uma banana é [9, 7, 4]. Esses números facilitam a comparação ou o agrupamento de frutas semelhantes.
O que um modelo de incorporação faz?
Um modelo de incorporação converte texto, imagens e áudio em números significativos e os compara para encontrar padrões ou conexões. Esse processo é semelhante ao modo como uma biblioteca organiza os livros por gênero ou tópico, permitindo que os usuários encontrem mais rapidamente o que estão procurando.
Aqui estão alguns exemplos de casos de uso diário para modelos de incorporação:
Pesquisa de texto
Imagine digitar "melhor comida grega" em um mecanismo de busca. Um modelo de incorporação converterá sua consulta em números e recuperará documentos com incorporação semelhante. O modelo mostrará resultados que se aproximam de sua consulta.
Recomendar filmes
Se você gostou de um filme, o sistema usa um modelo de incorporação para representá-lo (por exemplo, gênero, elenco, humor) como números. Ele compara esses números com outros filmes incorporados e recomenda outros semelhantes.
Combine imagens e legendas
Um modelo de incorporação pode combinar uma imagem de um pôr do sol sobre o oceano com a legenda "Um pôr do sol sereno sobre as ondas calmas do oceano", convertendo a imagem e as possíveis legendas em representações numéricas (incorporações). O modelo identifica a legenda com um embedding mais próximo do embedding da imagem, garantindo uma correspondência precisa. Essa técnica potencializa ferramentas como pesquisa de imagens e marcação de fotos.
Agrupar itens semelhantes
Um site de compras usa embeddings para agrupar produtos semelhantes. Por exemplo, "tênis vermelho" pode estar próximo de "tênis azul" no espaço de incorporação, portanto, eles são mostrados como relacionados.
Tipos de modelos de embeddings
Há vários modelos de incorporação, cada um projetado para diferentes tipos de dados e tarefas. Aqui estão os principais tipos:
Modelos de incorporação de palavras
Esses modelos convertem palavras em vetores numéricos que capturam significados semânticos e relações entre palavras. Os exemplos incluem:
-
- Word2vec: Aprende a incorporação de palavras prevendo uma palavra com base em seu contexto (skip-gram) ou prevendo o contexto com base em uma palavra (CBOW).
- GloVe (Vetores Globais para Representação de Palavras): Um modelo que usa estatísticas de co-ocorrência de palavras de um grande corpus para criar embeddings.
- fastText: Semelhante ao Word2vec, mas considera informações de subpalavras, o que o torna mais eficaz para idiomas morfologicamente ricos.
Modelos de incorporação de palavras contextualizadas
Esses modelos geram embeddings dinâmicos de palavras com base no contexto em que uma palavra aparece. Ao contrário dos embeddings estáticos, o significado de uma palavra pode mudar dependendo de seu uso.
-
- BERT (Bidirectional Encoder Representations from Transformers): Gera palavra embeddings com base no contexto das palavras ao redor, o que o torna altamente eficaz para tarefas como resposta a perguntas e análise de sentimentos.
- GPT (Generative Pre-trained Transformer): Gera embeddings contextualizados para geração de texto e outras tarefas de linguagem.
- ELMo (Embeddings from Language Models): Fornece incorporação de palavras com base em todo o contexto da frase, o que permite capturar significados mais profundos.
Modelos de incorporação de frases ou documentos
Esses modelos criam embeddings que representam frases ou documentos inteiros em vez de apenas palavras individuais.
-
- Doc2vec: Uma extensão do Word2vec que gera embeddings para documentos inteiros, considerando o contexto das palavras no documento.
- InferSent: Um codificador de sentenças que aprende a mapear sentenças em embeddings para tarefas como similaridade e classificação de sentenças.
Modelos de incorporação de imagens
Esses modelos representam imagens como vetores, permitindo tarefas como reconhecimento e recuperação de imagens.
-
- Redes neurais convolucionais (CNNs): Modelos como o ResNet e o VGG extraem recursos de imagens e geram classificação de imagens e embeddings de reconhecimento.
- CLIP (Pré-treinamento Contrastivo de Linguagem-Imagem): Um modelo que conecta imagens e descrições textuais, gerando embeddings para ambos e alinhando-os no mesmo espaço vetorial para tarefas como pesquisa de texto e imagem.
Modelos de incorporação de áudio e fala
Esses modelos convertem dados de áudio ou fala em embeddings, que são úteis para tarefas como reconhecimento de fala e detecção de emoções.
-
- VGGish: Um modelo de incorporação para áudio, especialmente música e fala, baseado em CNNs.
- Wav2vec: Um modelo da Meta AI que gera embeddings para áudio de fala bruta, o que é eficaz para tarefas de fala para texto.
Cada modelo é projetado para lidar com tipos específicos de dados e tarefas, ajudando a capturar e representar relacionamentos úteis para aplicativos de aprendizado de máquina.
Como os modelos de incorporação são treinados?
Os modelos de incorporação são treinados usando grandes conjuntos de dados e objetivos de aprendizado específicos que os orientam a criar representações de dados numéricos significativos. O processo de treinamento envolve as seguintes etapas:
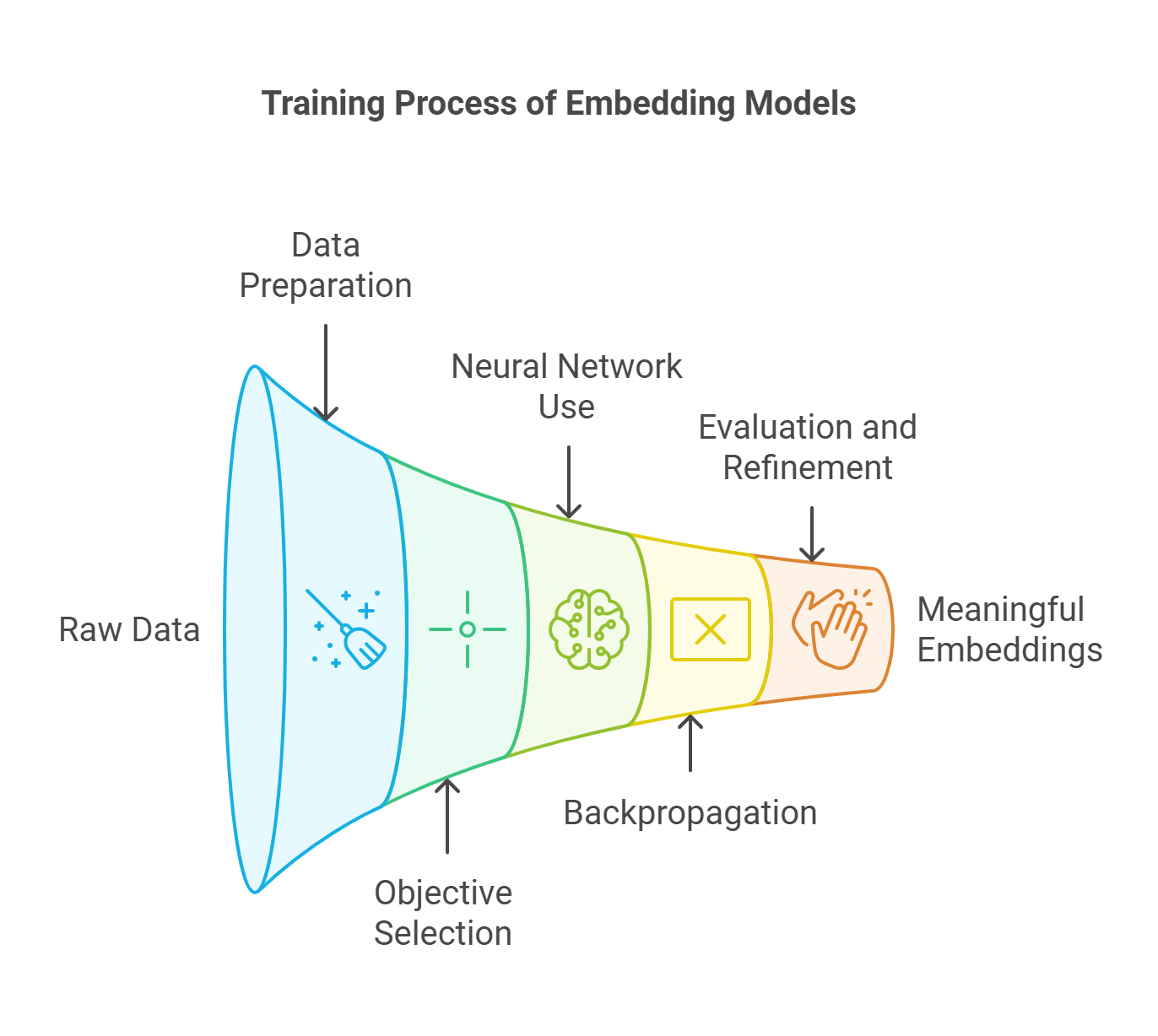
O processo de treinamento para modelos de incorporação
1. Coleta e preparação de dados
-
- Conjuntos de dados: São necessários grandes conjuntos de dados (como corpora de texto) para incorporação de idiomas, conjuntos de dados de imagens rotuladas para incorporação visual e conjuntos de dados emparelhados (por exemplo, imagens e legendas) para incorporação multimodal.
- Pré-processamento: O texto é tokenizado em palavras ou subpalavras, as imagens são redimensionadas e normalizadas e o áudio é transformado em espectrogramas ou outros formatos.
2. Escolha de um objetivo de treinamento
O modelo aprende a criar incorporações por meio da otimização para um objetivo específico. Os objetivos comuns incluem:
-
- Previsão de contexto (modelos de linguagem)
-
-
-
- Exemplo: O modelo de grama de salto do Word2vec prevê palavras adjacentes para uma determinada palavra. Se a entrada for "The cat sat on the __" (O gato sentou-se no __), o modelo poderá prever "mat" (tapete).
-
-
-
- Minimizar as diferenças nos dados relacionados (aprendizado contrastivo)
-
-
-
- Exemplo: No CLIP, uma imagem e sua legenda são aproximadas no espaço de incorporação, enquanto imagens e legendas não relacionadas são afastadas.
-
-
-
- Classificação ou objetivos específicos da tarefa
-
-
- Exemplo: Um modelo pode prever se uma imagem contém um cachorro ou um gato. Os embeddings são ajustados para facilitar a tarefa, agrupando imagens semelhantes.
-
3. Uso de redes neurais
-
- Modelos rasos: Os primeiros modelos, como o Word2vec, usam redes neurais simples para aprender embeddings com base em padrões de co-ocorrência.
- Modelos profundos: Transformadores (por exemplo, BERT, GPT) e CNNs extraem padrões e relacionamentos mais complexos processando dados em camadas.
4. Retropropagação e otimização
-
- O modelo faz uma previsão, calcula um erro (a diferença entre a previsão e a meta) e ajusta seus parâmetros usando a retropropagação.
- Um otimizador (como o Adam ou o SGD) atualiza os embeddings e os pesos do modelo para minimizar esse erro.
5. Avaliação e refinamento
-
- O modelo é avaliado com o uso de dados de validação para garantir que ele produza incorporações significativas para as tarefas pretendidas.
- Ajustes como o ajuste de hiperparâmetros ou o ajuste fino em conjuntos de dados específicos são feitos para melhorar o desempenho.
Como funcionam os modelos de incorporação?
Agora, vamos nos aprofundar em como esses modelos funcionam:

Processo de modelo de incorporação
1. Processamento de dados de entrada
O modelo insere dados brutos (por exemplo, texto, imagens ou áudio) e os pré-processa da seguinte maneira:
-
- O texto é tokenizado em unidades menores, como palavras ou subpalavras.
- As imagens são divididas em elementos menores, como pixels ou recursos.
- O áudio é convertido em formas de onda ou espectrogramas.
2. Extração de recursos
O modelo de incorporação analisa a entrada para identificar os principais recursos:
-
- Com o texto, ele considera o contexto e o significado das palavras.
- Com imagens, ele detecta padrões visuais, cores ou formas.
- Com o áudio, ele identifica tons, frequências ou ritmos.
Por exemplo, o Word2vec aprende as relações entre as palavras com base na frequência com que elas aparecem juntas em um grande conjunto de dados. Por exemplo, ele pode perceber que "rei" e "rainha" aparecem com frequência em contextos semelhantes e atribui a elas embeddings próximos no espaço vetorial.
3. Redução da dimensionalidade
Dados de alta dimensão (por exemplo, uma imagem com milhões de pixels) são compactados em um vetor de dimensão inferior. Esse vetor preserva as informações essenciais e descarta detalhes desnecessários. Por exemplo, uma imagem pode ser reduzida a um vetor de 512 dimensões, capturando seus principais recursos sem manter a resolução total.
4. Aprendizado por meio de treinamento
Os modelos de incorporação são treinados em grandes conjuntos de dados usando técnicas de aprendizado de máquina para detectar padrões e relacionamentos. Essas técnicas incluem:
-
- Aprendizagem não supervisionada: O modelo aprende a organizar os dados agrupando palavras ou imagens semelhantes.
- Aprendizagem supervisionada: O modelo aprende a alinhar os embeddings com rótulos específicos ou a distinguir entre pares semelhantes e diferentes (por exemplo, combinar legendas com as imagens corretas).
5. Embeddings de saída
O modelo gera um vetor para cada entrada. Esses embeddings podem ser:
-
- Comparados usando medidas matemáticas como a similaridade de cosseno.
- Agrupados ou agrupados para análise.
- Passado para outros modelos de aprendizado de máquina para tarefas como classificação ou recomendação.
Como escolher o modelo de incorporação correto
A escolha do modelo de incorporação correto depende do tipo de dados com os quais você está trabalhando e da tarefa específica que deseja executar. Aqui estão algumas considerações importantes para ajudá-lo a selecionar o modelo certo.
Tipo de dados
-
- Texto: Se estiver trabalhando com dados de texto, como frases ou documentos, escolha um modelo com base na necessidade de incorporação de palavras estáticas ou incorporação dinâmica baseada no contexto. (por exemplo, Word2vec, GloVe, BERT, GPT).
- Imagens: Se estiver lidando com imagens, precisará de um modelo que possa converter recursos visuais em embeddings. (por exemplo, ResNet, VGG, CLIP).
- Áudio: Se estiver trabalhando com dados de áudio ou fala, procure modelos projetados especificamente para lidar com som. (por exemplo, VGGish ou Wav2vec).
Requisitos da tarefa
-
- Tarefas no nível da palavra: Se você precisar analisar ou comparar palavras individuais, modelos como Word2vec ou fastText podem ser adequados.
- Tarefas no nível da frase ou do documento: Para tarefas que exigem uma representação de frases ou documentos inteiros (por exemplo, similaridade ou classificação), modelos como Doc2vec ou BERT são mais adequados.
- Tarefas multimodais: Se você precisar trabalhar com texto e imagens (ou outras combinações), modelos como o CLIP ou o DALL-E são ideais porque alinham as incorporações em diferentes tipos de dados.
Considerações sobre o desempenho
-
- Velocidade e eficiência: Modelos mais simples, como Word2vec e GloVe, são mais rápidos e consomem menos recursos, o que os torna adequados para conjuntos de dados menores e aplicativos em tempo real. No entanto, eles podem não capturar relações sutis tão bem quanto os modelos mais complexos.
- Precisão e profundidade: Modelos mais avançados, como o BERT e o GPT, oferecem alta precisão ao capturar relações e contextos semânticos profundos; no entanto, eles são computacionalmente caros e de treinamento lento.
Tamanho do conjunto de dados
-
- Grandes conjuntos de dados: Para grandes conjuntos de dados, modelos como o BERT e o CLIP, que são pré-treinados em grandes quantidades de dados, podem ser ajustados para tarefas específicas.
- Conjuntos de dados menores: Se você tiver dados limitados, modelos como fastText ou Word2vec podem ter um desempenho melhor, pois podem ser treinados com menos pontos de dados.
Modelos pré-treinados vs. treinamento personalizado
-
- Se estiver trabalhando em uma tarefa geral e não precisar de um modelo altamente especializado, o uso de embeddings pré-treinados de modelos como BERT, GPT ou ResNet geralmente é suficiente e economiza tempo.
- Se os seus dados forem altamente específicos (por exemplo, um domínio ou idioma de nicho), talvez seja necessário ajustar um modelo pré-treinado ou treinar um modelo personalizado.
Conclusão
Nesta postagem, exploramos como os modelos de incorporação ajudam a transformar dados complexos, como texto, imagens ou áudio, em representações numéricas simplificadas que os computadores podem entender e processar com eficiência. Ao aprender as relações e os padrões dentro dos dados, esses modelos permitem aplicações que vão desde o processamento de linguagem natural até o reconhecimento de imagens e tarefas multimodais. A escolha do modelo de incorporação correto depende de fatores como o tipo de dados, a tarefa específica, o tamanho do conjunto de dados e os recursos computacionais disponíveis.
Você pode visitar esses recursos do Couchbase para continuar aprendendo sobre embeddings vetoriais e pesquisa: