Todo benchmark levanta alguns pontos de interrogação e responde a outros. Portanto, com cada benchmark, você mesmo precisa examinar os dados para obter informações completas. Eu venho fazendo benchmarking há algum tempo, começando na era TPC com as guerras de benchmark e não aqui no Couchbase, onde impulsionamos o desempenho profundamente no produto por meio de benchmarks internos e externos com muitos de nossos clientes e parceiros.
Espero que alguns de vocês já tenham visto os resultados de benchmark da Avalon comparando o MongoDB 3.2 e o Couchbase Server 4.5. Você pode encontrar a divulgação completa aqui. Vou me aprofundar em alguns detalhes do benchmark aqui e tentar explicar por que o Couchbase Server é mais rápido na execução de consultas (YCSB Workload E) e no acesso a valores-chave (YCSB Workload A). Vamos analisar os resultados:
Carga de trabalho E: consulta de conversas encadeadas
Carga de trabalho E no YCSB simula uma conversa encadeada e o objetivo é recuperar uma consulta de intervalo o mais rápido possível que está procurando por aproximadamente 50 conversas (itens). Há também uma carga de trabalho de inserção leve que acompanha a consulta (%5 das operações são INSERTs). Portanto Como o Couchbase Server é capaz de executar >3,7 vezes mais consultas/seg. do que o MongoDB?
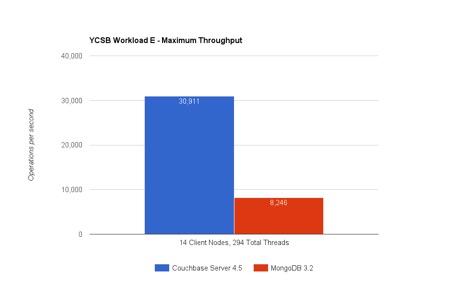
#1 Execução de consultas com índices globais no Couchbase Server
A distribuição (sharding) do Couchbase e do MongoDB permite que os dados sejam distribuídos uniformemente entre os nós. Cada nó recebe uma fatia igual do total de itens. Esse teste tem 150 milhões de itens distribuídos em 9 nós. Carga de trabalho A consulta de varredura de intervalo E opera sobre um índice. Os índices do MongoDB são particionados para se alinharem aos dados em cada nó. Ou seja, cada nó recebe uma partição de índice que indexa localmente os dados. Nesse teste, o Couchbase Server usa índices globais. Os índices globais particionam o índice de forma independente.
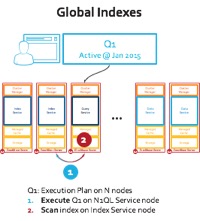
Por que isso é importante? Isso significa que a execução de consultas do MongoDB exige uma coleta dispersa nos 9 nós de servidor que ele tem: veja a imagem do índice local abaixo. Em vez disso, o mecanismo N1QL do Couchbase Server usa um dos índices para fazer um único salto de rede para executar a varredura de intervalo: veja a imagem do índice global abaixo.
 |
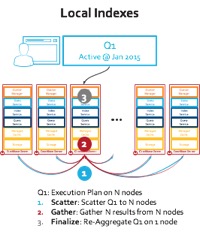 |
Figura: Execução de consulta com distribuição de índice global e local
Há um problema fundamental aqui com a arquitetura do índice local: Na etapa #1, a consulta de intervalo é distribuída para todos os nós. Nesse modelo, nenhum nó do cluster pode responder à pergunta, pois o índice usado para a execução da consulta é distribuído de acordo com a distribuição de dados. Cada nó precisa executar a mesma varredura de intervalo (a propósito, a consulta na carga de trabalho E do YCSB executa uma varredura de intervalo com "order by" e "limit 50") e pegar os itens que se enquadram no intervalo. Isso significa que você tem node-count*50 itens viajando para o nó de coordenação. Esse teste executa milhares de consultas e o desperdício se replica até que a rede fique saturada! Mas esse não é o problema mais sério dos índices locais...
Digamos que adicionemos um novo nó ou expandamos esse cluster para 100 nós, cada novo nó ainda terá que executar a consulta. Não é possível dimensionar a consulta adicionando nós! Na verdade, as coisas pioram à medida que a rede se satura entre os nós. Você também desperdiça uma grande soma de capacidade da CPU e envolve todos os nós o tempo todo.
No caso da execução de uma consulta no N1QL com índice global, o quadro é muito diferente. O N1QL empurra "order by" e "limit" para o índice e traz apenas 50 itens. Não há sobrecarga de rede... Na verdade, o N1QL acrescenta uma recuperação mais eficiente usando um conjunto de resultados compactado (RAW). Você pode adicionar um nó ou expandir para 100 nós e verá benefícios reais na taxa de transferência. Na verdade, você pode repetir o teste YCSB Workload E com 20 ou 30 nós, e eu esperaria ver uma diferença maior entre as taxas de transferência do Couchbase Server e do MongoDB.
#2 Índices otimizados para memória
Os índices globais são ótimos, mas sua manutenção é um desafio. O índice global que reside em um dos nós está acompanhando as atualizações que ocorrem em todo o cluster - ou, pelo menos, todas as mutações relevantes para o índice. Você precisa de uma estrutura de índice extremamente eficiente que possa acompanhar as atualizações dos dados e, ao mesmo tempo, realizar varreduras de alta velocidade.
O Couchbase Server 4.5 introduziu uma nova arquitetura de armazenamento para índices globais chamada de índices otimizados para memória (MOI). O MOI otimiza o armazenamento em memória e ocupa menos espaço na memória, além de usar uma lógica de manutenção de índice sem bloqueio para indexar atualizações pesadas de dados com paralelismo maciço. O MongoDB usa uma versão de um índice B-Tree que é bastante clássico entre muitos bancos de dados relacionais e NoSQL. O Couchbase Server também vem com HB+Tree e alguns índices HB+Trie. Eles são usados com o modo de armazenamento padrão de índices e em visualizações Map-Reduce. No entanto, o que descobrimos é que essa nova estrutura skiplist e a abordagem sem bloqueio aumentam muito a manutenção do índice e o desempenho da varredura no caso de índices globais.
Figura: Indexação sem bloqueio de lista de esqui com índices globais otimizados para memória
Para que você tenha uma rápida noção da diferença que estamos vendo, aqui está a comparação da indexação do Couchbase Server com os modos de armazenamento de índice padrão e otimizado para memória. Os índices otimizados para memória são 20 vezes mais rápidos em termos de tempos de resposta de consulta.
Embora alguns desses recursos não estejam em uso no benchmark, vale a pena mencionar que o Couchbase Server pode indexar estruturas de matriz com aninhamento de vários níveis. Por exemplo, filmes e horários de exibição podem ser normalizados em duas tabelas separadas no mundo relacional; no entanto, tanto o MongoDB quanto o Couchbase modelam os dados com um único documento "filme" que contém uma matriz de horários de exibição. Para atualizar os horários de exibição de um único filme, você emite uma única atualização. Entretanto, um índice de matriz receberia muitas atualizações, pois indexa cada showtime individual. A taxa de atualização do índice é ampliada de forma igual ao tamanho da matriz... Então, tudo isso significa uma coisa: mesmo os sistemas que podem ter uma baixa taxa de atualização de itens podem precisar de índices de matriz que precisam acompanhar 10x, 20x ou 100x a quantidade de atualizações, dependendo do tamanho das matrizes incorporadas nos documentos. A MOI ajuda muito nessas condições, pois pode acompanhar mais de 100 mil atualizações com recursos computacionais suficientes.
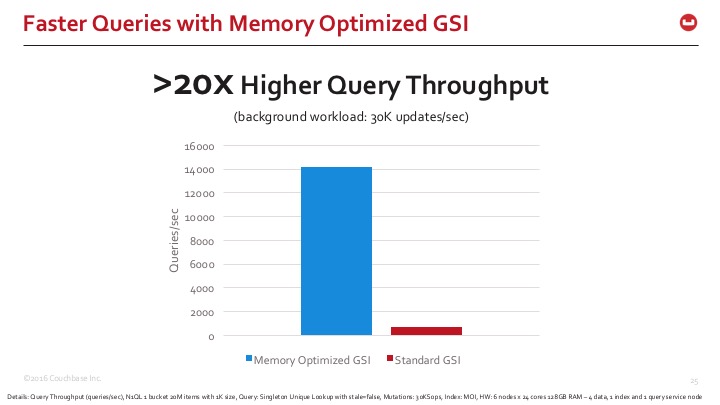
Mergulhe mais fundo nos resultados do YCSB Workload E
One consolidated view that tells the whole story is the %95th latency and throughput overlaid graph. This is how I view all performance results personally. – If you are the benchmarking type, you know the saying: “não faz sentido analisar a latência sem a taxa de transferência e vice-versa".
Aqui está uma análise detalhada das latências e taxas de transferência da execução da consulta da Carga de Trabalho E.
-As barras representam a taxa de transferência - azul é o Couchbase e verde é o MongoDB. O eixo Y é o número da taxa de transferência.
-As linhas representam a latência - azul é o Couchbase e laranja é o MongoDB. O eixo Y secundário à direita representa os números de latência com a linha de latência descendente representando uma latência pior ou maior. Em outras palavras, o eixo secundário da latência é uma linha descendente eixo (as linhas pontilhadas que caem representam maior latência).
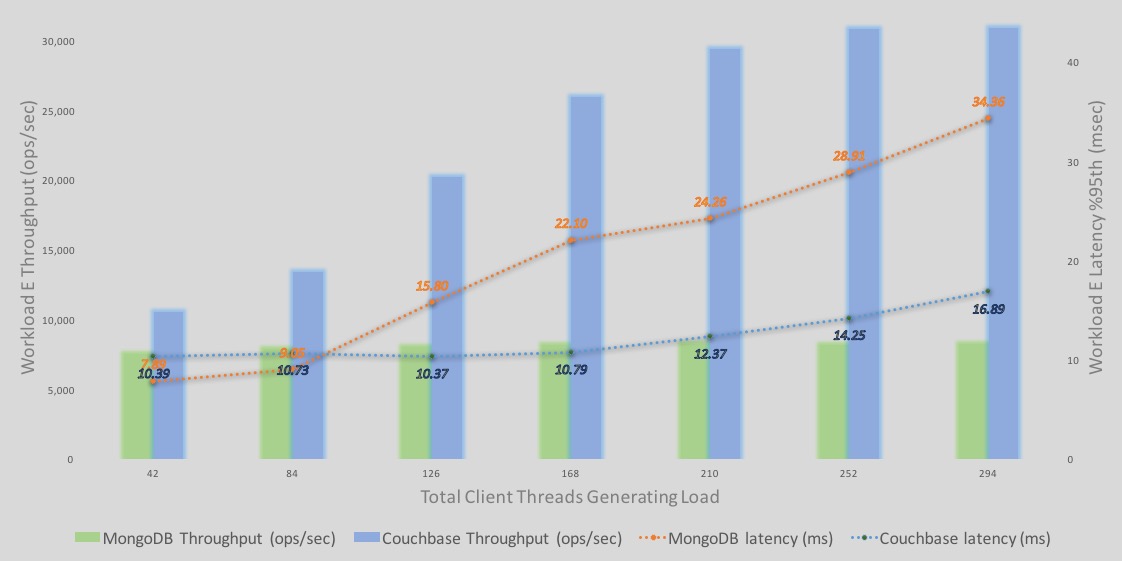
Algumas observações;
-Taxa de transferência: A taxa de transferência do Couchbase Server continua a aumentar com mais carga. A taxa de transferência do MongoDB também aumenta, mas apenas uma pequena quantidade antes de se estabilizar rapidamente.
-Latência para o Couchbase começam mais altos do que para o MongoDB (42 e 84 clientes). No entanto, a taxa de transferência do Couchbase Server é maior sob cargas de 42 e 84 clientes. Eu apostaria que, sob a mesma taxa de transferência, as latências em ambos os mecanismos podem ser semelhantes sob essa carga leve. Entretanto, à medida que a carga aumenta, as latências aumentam. No entanto, com o efeito dos índices globais e do MOI, o Couchbase apresenta melhor taxa de transferência até chegarmos a mais de 250 clientes. O Couchbase Server também se estabiliza nesse ponto.
Carga de trabalho A: Gravação e leitura de sessões de usuário
Carga de trabalho A no YCSB simula uma carga de trabalho que captura e lê ações recentes do usuário com 50% leituras e 50% atualizações. Essa é uma carga de trabalho básica de chave/valor. Você perceberá que as operações/seg. são muito mais altas aqui. Isso ocorre porque cada operação lida apenas com um único item. A carga de trabalho E, por outro lado, lida com 50 itens por consulta.
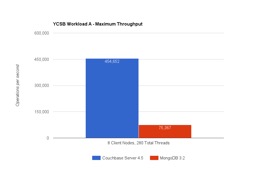
Você pode revirar os olhos e pensar que a simples leitura e gravação de mais de 1K de dados não é um grande desafio. No entanto, fazer isso de forma eficiente é difícil. Muitos bancos de dados se ajustam à leitura ou à gravação, mas não a ambas! Quando você junta as duas coisas, fica difícil manter o ritmo. Mas Como o Couchbase Server é capaz de executar 6 vezes mais operações no mesmo HW (9 nós c3.8xlarge no Amazon Web Services) em comparação com o MongoDB?
#3 Acesso mais rápido aos dados do cache
Um dos principais motivos pelos quais o Couchbase pode fazer a leitura/gravação mais rapidamente (menos de milissegundos) é a utilização do cache integrado. Muitos bancos de dados, inclusive outros em que trabalhei no passado, diriam para você ter uma camada de cache na frente do banco de dados para não sobrecarregar o banco de dados. No entanto, o Couchbase Server nunca é implantado com uma camada de cache separada. Ele tem memcached já incorporados para acesso rápido aos dados. Também podemos armazenar em cache as partes do documento de que precisamos, às vezes apenas seus metadados, às vezes com seus dados.
#4 Comunicação cliente-servidor eficiente e sem proxy
O Couchbase Server vem com um cliente inteligente capaz de armazenar em cache a topologia do cluster e seu mapa de distribuições. Isso significa que os clientes já sabem o nó exato do Couchbase Server com o qual devem se comunicar quando obtiverem o valor da chave. Não há saltos na comunicação. Nenhum intermediário, nenhum redirecionamento... Isso torna a comunicação eficiente.
Há recursos adicionais que têm efeito indireto na comunicação do Couchbase Server: Leituras e atualizações parciais de documentos. Se a carga de trabalho aqui for modificada para ler e atualizar um subconjunto do documento, você poderá ver melhorias nos resultados ao usar o novo API.
Mergulhe mais fundo nos resultados da carga de trabalho A do YCSB
Here is the the %95th latency and throughput overlaid graph.
Aqui está uma análise detalhada dos throughputs e latências de execução de leitura/gravação da carga de trabalho A.
-As barras representam a taxa de transferência - azul é o Couchbase e verde é o MongoDB. O eixo Y é o número da taxa de transferência.
-As linhas representam a latência - azul é o Couchbase e laranja é o MongoDB. O eixo Y secundário à direita representa os números de latência, com a linha de latência descendente representando uma latência pior ou maior. Em outras palavras, o eixo secundário da latência é um eixo descendente.
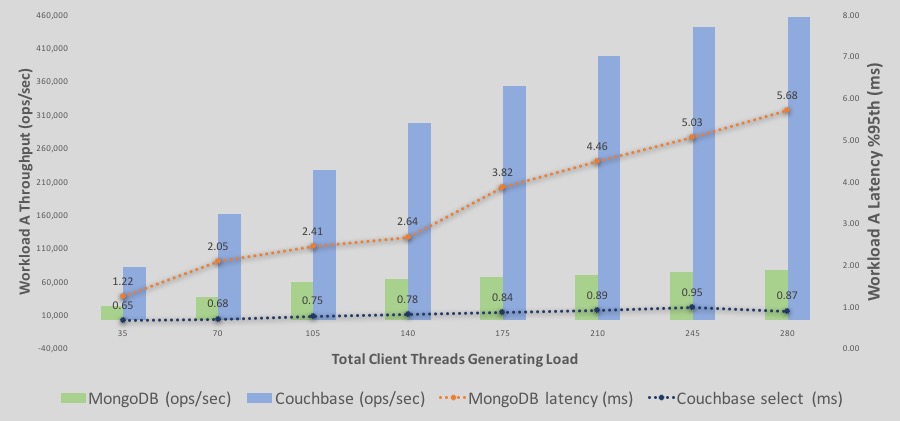
Algumas observações;
-Taxa de transferência: A taxa de transferência do Couchbase Server continua a aumentar com mais carga. A taxa de transferência do MongoDB também aumenta com uma inclinação mais lenta até 140 clientes. No entanto, em torno de >210 threads, ele se estabiliza.
-Latência para o Couchbase começam mais baixos do que os do MongoDB e continuam assim. No final, o Couchbase ainda está na faixa de latência abaixo de milissegundos, enquanto o MongoDB chega a uma latência superior a 5 ms para uma latência de 95%.
Sei que todo benchmark pode suscitar ceticismo, mas incentivo todos vocês a experimentarem o Couchbase Server e nos dizerem o que observam em suas execuções personalizadas do YCSB. Se não estiver obtendo os resultados esperados, informe-nos