Dada a arquitetura e o design dos sistemas NoSQL, especialmente os bancos de dados da família de documentos, como o Couchbase, que não impõem o esquema na gravação, a modelagem de dados para NoSQL pode ser desafiadora ao migrar de sistemas relacionais para NoSQL ou ao criar aplicativos básicos usando NoSQL. De fato, a modelagem de dados costuma ser um fator crítico de sucesso para as implantações do Couchbase, e a otimização progressiva dos modelos de dados pode ser um grande impulsionador do desempenho dos aplicativos, dada a natureza em rápida evolução dos aplicativos de Big Data.
Tradicionalmente, a modelagem de dados para sistemas relacionais era a ciência de identificar os objetos de dados, seus relacionamentos entre si e sua representação precisa, o que estabelecia a base para um bom projeto de banco de dados. A modelagem para NoSQL, por outro lado, explora padrões de acesso específicos do aplicativo, por exemplo, "quais são os tipos de perguntas que os usuários gostariam de responder com esses dados?" Isso, por sua vez, determina o tipo de consultas que precisam ser suportadas e se concentra na melhor forma de dispor os dados para otimizar o desempenho. Essas considerações nos levam a mudar nossa abordagem de modelagem de dados das restrições tradicionais do RDBMS (esquema na gravação) para a modelagem de dados para o aplicativo específico (esquema na leitura).
Outra diferença entre os sistemas RDBMS e NoSQL que afeta os paradigmas de modelagem é o conceito de normalização e desnormalização dos dados. Enquanto os sistemas RDBMS enfatizavam a normalização dos dados para entender as relações estritas e atender às limitações rígidas de armazenamento no passado, os sistemas NoSQL flexíveis se inclinam para a desnormalização dos dados, pois eles são distribuídos em clusters e a redundância pode facilitar o dimensionamento das leituras de dados. Muitas vezes, o modelo de dados ideal é uma combinação das duas abordagens, dependendo do caso de uso.
Portanto, a modelagem precisa de dados continua sendo uma disciplina essencial para o sucesso com os bancos de dados NoSQL.
Agora, vamos nos aprofundar na modelagem usando o erwin DM NoSQL. O erwin DM NoSQL oferece três funcionalidades principais:
Engenharia avançada
O processo de conversão de seus modelos relacionais em modelos JSON compatíveis com o Couchbase.
Transformação
Capacidade de escolher a forma desejada de transformação (normalizada, desnormalizada, personalizada) para seus modelos.
Engenharia reversa
Capacidade de importar o esquema dos dados de produção no Couchbase para o ambiente erwin.
Veja a seguir o guia passo a passo para modelar dados para a Couchbase Data Platform usando o erwin DM NoSQL:
Preparação:
Etapa 1:
Solicitação de uma conta aqui e faça login no erwin DM NoSQL usando suas credenciais.

Etapa 2:
Envie um modelo de Entidade-Relacionamento gerado a partir do erwin DM ou de qualquer outra ferramenta de modelagem relacional no formato "XML" usando a opção de importação para o erwin DM NoSQL.
Etapa 3:
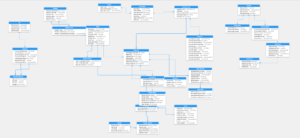
Visualize seus diagramas ER em um ambiente erwin.
Transformação
Etapa 1:
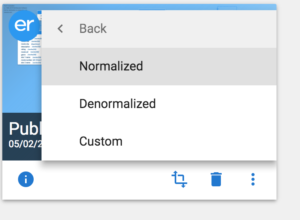
Escolha transformar os modelos usando transformação normalizada, desnormalizada ou personalizada.
Etapa 2:
a. Transformação normalizada:
Normalmente, a normalização é o processo de organização dos dados no banco de dados por meio da criação de tabelas separadas e do estabelecimento de relacionamentos para remover a duplicação. Os objetos ou entidades nesse processo geralmente são referenciados. Ao criar modelos JSON, as tabelas referenciadas normalmente seriam documentos separados.
b. Transformação desnormalizada:
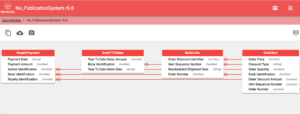
Nesse processo, os objetos de dados geralmente são incorporados. Como objetos semelhantes são incorporados em muitos documentos, essa organização apresenta redundância. A desnormalização costuma melhorar significativamente o desempenho, pois não precisamos de junções para buscar os dados necessários. Isso é frequentemente adotado em sistemas NoSQL. Nessa ferramenta, o modelo transformado gerado usando a desnormalização é uma combinação de objetos incorporados e referenciados.

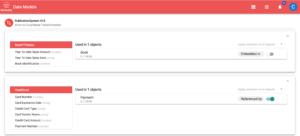
Na figura acima, pedido de compra e item de pedido são objetos incorporados, enquanto Publisher, Store name e BookReturn são objetos referenciados.
c. Transformação personalizada:
O erwin DM NoSQL normalmente analisa a organização dos dados usando seu diagrama E-R e transforma seus modelos em modelos JSON compatíveis com o Couchbase com base em determinadas regras. No entanto, como você, como desenvolvedor de aplicativos ou proprietário de aplicativos, conhece melhor o seu aplicativo, oferecemos a possibilidade de personalizar os seus modelos. Você tem a opção de fazer referência a determinados objetos incorporados e nós fornecemos algumas diretrizes na ferramenta para ajudá-lo a fazer a escolha certa.
Observação: Você pode clonar qualquer um desses modelos e ajustá-los adicionando ou removendo atributos, propriedades etc,
Engenharia avançada:
Etapa 1:
Faça o download do modelo criado em seu sistema local.

Etapa 2:
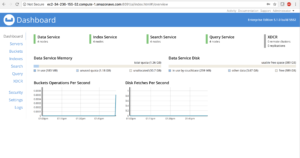
Configure os clusters do Couchbase no AWS e acesse o console da Web usando a porta 8091
Etapa 3:
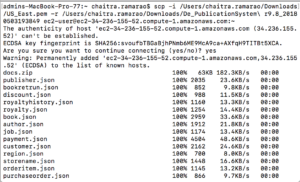
Use a cópia segura e copie o arquivo baixado de seu computador local para a instância do Couchbase EC2.
Sintaxe (OSX): scp -i caminho para a chave -r caminho para o diretório ec2-user@hostname:~
Ex: scp -i /Users/chaitra.ramarao/Downloads/US_East.pem -r /Users/chaitra.ramarao/Downloads/Cl_De_EMOVIES\ r9.64_20180329185059 ec2-user@ec2-54-152-108-80.compute-1.amazonaws.com:~
Etapa 4:
Faça login na sua instância do AWS usando ssh
Sintaxe (OSX):ssh -i caminho para key.pair ec2-user@remote ip
Ex: ssh -i /Users/chaitra.ramarao/Downloads/US_East.pem ec2-user@ec2-34-203-230-73.compute-1.amazonaws.com
Etapa 5:
Verifique se os arquivos foram copiados, listando-os usando "ls"
Etapa 6:
Navegue até o arquivo bulkInsert.sh
Ex:Cd /De_movies../scripts/5.x para localizar o bulkInsert.sh
Etapa 7:
Torne o arquivo bulkInsert um executável e defina o caminho
Chmod +x bulkInsert.sh
PATH=/opt/couchbase/bin:$PATH
Etapa 8:
Execute o script bulkInsert com a seguinte sintaxe
./bulkInsert.sh
Ex: ./bulkInsert.sh localhost 8091 Amostra de senha de administrador
Você pode ver os dados de amostra modelados carregados no Couchbase com o nome do bucket especificado por você.
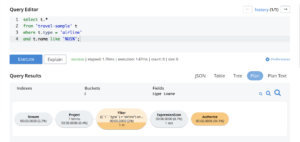
O script normalmente cria modelos em dados inúteis, mas pode ser modificado pelos desenvolvedores de aplicativos para criar modelos para amostras de dados reais e usá-los para implantar no Couchbase usando os scripts de implantação fornecidos.
Você também pode consultar os dados depois de carregados no Couchbase usando N1QL (SQL para JSON) e testar a precisão e a eficiência dos seus modelos usando o Query Workbench e o planejador de consultas.
Engenharia reversa:
Etapa 1:
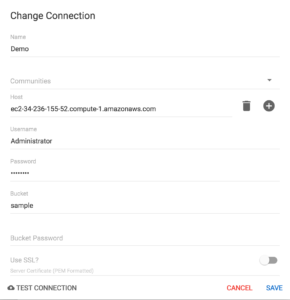
Configure a conexão com o Couchbase usando o gerenciador de conexões, conforme mostrado abaixo:
Etapa 2:
Escolha a engenharia reversa do Couchbase
Etapa 3:
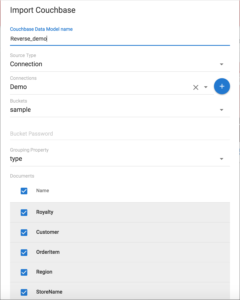
Importação de esquema de dados de produção do Couchbase
Etapa 4:
Visualize os modelos de engenharia reversa do Couchbase no ambiente erwin
Continue ajustando seus modelos periodicamente para garantir que eles sejam otimizados para oferecer o melhor desempenho.
A modelagem de dados com o uso da erwin o ajudará a acelerar o tempo de lançamento no mercado, fornecerá a interface para visualizar o processo de modelagem e aumentará tremendamente a precisão dos seus modelos. Melhores modelos de dados garantem melhor desempenho e maior sucesso com o Couchbase.
Compartilhe seus comentários aqui ou entre em contato conosco em forums.couchbase.com