Comecei a usar o Zeppelin recentemente. Ele é um excelente notebook baseado na Web que permite análises em tempo real. Ele oferece suporte a uma variedade de back-ends por meio do conceito de intérpretes.
O Zeppelin Interpreter é o plug-in que permite que o usuário do Zeppelin use uma linguagem/backend de processamento de dados específico. Por exemplo, para usar o código scala no Zeppelin, você precisa do interpretador spark.
Você já pode fazer algum trabalho relacionado ao Couchbase usando o interpretador Spark e o Conector do Couchbase Spark. Mas eu só quero executar algumas consultas N1QL em pads, como com Spark SQL e DataFrames. Portanto, preciso criar um interpretador N1QL do Couchbase. Fazer isso é fácil e documentadoVocê precisa de apenas uma classe.
Essa classe deve estender a classe abstrata org.apache.zeppelin.interpreter.Interpreter resultando na implementação dos seguintes métodos abstratos: aberto, próximo, interpretar, getFormType, getProgress, conclusão.
Foi basicamente o que fiz aqui:
aberto e próximo são responsáveis, respectivamente, por abrir e fechar a conexão com o Cluster e o Bucket. O método interpret é aquele chamado quando você executa o pad. É nele que você transforma o texto do bloco no que quiser. Para esse interpretador, pegarei uma consulta N1QL, a executarei e transformarei o resultado para que possa ser usado no Zeppelin. Aqui, transformar significa achatar os documentos JSON resultantes, pois tudo precisa estar em um formato de tabela.
Agora posso executar qualquer consulta N1QL que eu quiser. Aqui está um exemplo simples extraído do bucket de amostra de jogos:
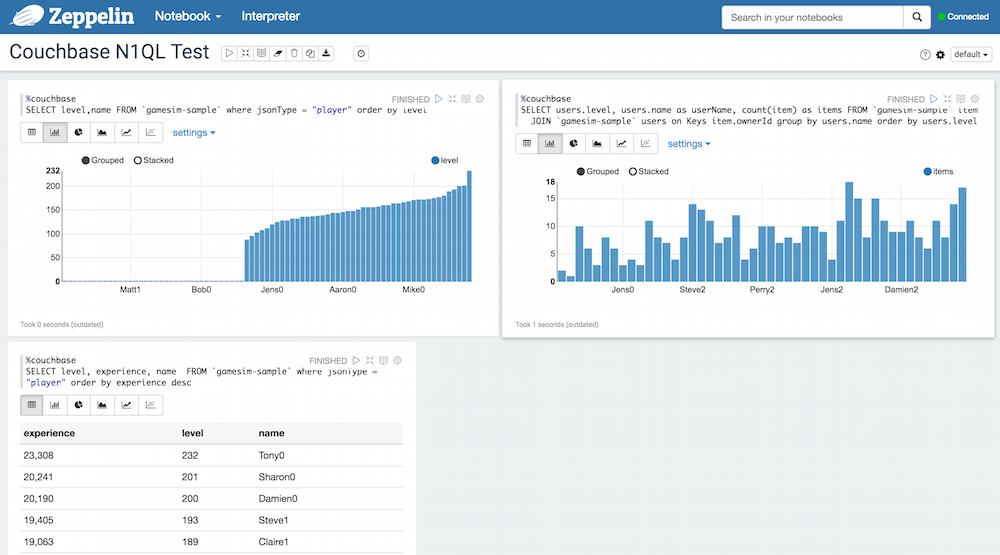
Você pode ver um quadro de líderes no canto inferior esquerdo, a lista de jogadores classificada por nível no canto superior esquerdo e a distribuição de itens por jogador também classificada por nível. Você pode ver que não há correlação entre o nível do jogador e o número de itens que ele tem. A consulta subjacente está usando um JOIN, que está disponível nativamente com o N1QL.
Agora, há muitos outros recursos que poderíamos adicionar. Presumo que o primeiro que vem à mente quando você conhece o Zeppelin é o autocompletar. Ele pode ser útil em muitas situações, seja para palavras-chave N1QL ou campos json. Na verdade, temos esse recurso disponível no IU de consulta se você inserir o guia ou Ctrl+Espaço. Outros recursos interessantes poderiam ser o suporte de visualizações, especialmente para consultas geoespaciais, e do Couchbase FTS. Iniciei o desenvolvimento do plug-in em Githube você pode segui-lo no Apache rastreador de problemas. Como sempre, comentários e contribuições são mais do que bem-vindos!