Há um ótimo blog sobre como obter o melhor desempenho de nosso serviço de indexação: "Crie o índice certo, obtenha o desempenho certo".Esse blog e seus conselhos resistiram ao teste do tempo. Então, por que não ter um blog relacionado a consultas com o mesmo nome?
De qualquer forma, acho que o mesmo pode ser dito sobre nosso serviço de consulta - para obter o desempenho certo, crie a consulta certa. O serviço de índice pode ser muito criticado por ser o único contribuinte para o desempenho da consulta. Mas há momentos em que tanto a consulta quanto o índice que você está usando precisam ser alterados.
Esperamos poder mostrar aqui um exemplo em que pode ser apenas um ajuste de consulta que precisa ser feito para obter o desempenho de nível empresarial pelo qual o Couchbase é conhecido. O exemplo a seguir é baseado em uma pergunta que nos foi feita por um de nossos clientes, portanto, esperamos que seja útil para várias pessoas que usam o Couchbase "com raiva".
Seu ambiente
Vamos usar um exemplo e, além disso, vamos facilitar o acompanhamento, pois sou um grande fã de blogs que permitem que os leitores acompanhem o processo, se desejarem. Para definir as regras básicas, aqui estão alguns componentes que você poderia usar para fazer esse exemplo acontecer:
- O sempre útil https://cloud.couchbase.com/sign-up ambiente de desenvolvimento. Está na sua rede em uma praia em Bali? Entendo que, se você acionar seu próprio contêiner do docker do Couchbase, os ventiladores ficarão em chamas e haverá areia diretamente no seu Mojito. Desde que você tenha uma conexão com a Internet, podemos lhe oferecer 30 minutos de ambiente de desenvolvimento gratuitamente! Obviamente, você está livre para usar qualquer ambiente do Couchbase que já tenha.
- O conjunto de dados de amostra de viagem
- Sua documentação útil sobre a matriz N1QL
- Este prático blog de referência de bolso sobre como trabalhar com matrizes
N.B. Os exemplos de N1QL aqui usarão nosso recurso de escopos/coleções - como tal, o contexto do bucket é definido como o escopo padrão no conjunto de dados de amostra de viagem.
Alguns contextos do mundo real
Para definir o cenário deste exemplo, podemos usar um caso de uso comum: geração de campanhas de marketing. Um exemplo dessa consulta pode ser encontrar visitantes do hotel que tenham deixado uma avaliação e gostado do hotel. Esses dados podem fazer com que eles tenham direito a recompensas de um programa de fidelidade, estadias em hotéis mais bem direcionados/similares ou apenas uma visão dos usuários que provavelmente deixarão uma avaliação/gosto. Todos esses insights fornecem dados valiosos para atender melhor aos hóspedes do hotel.
O principal objetivo desse exemplo específico é mostrar as possibilidades de consultar várias matrizes em um único documento JSON e, novamente, plantar a semente de que, às vezes, é possível obter ainda mais desempenho do serviço de consulta depois de criar o índice correto. Afinal, você está usando um sistema que permite campos de dados dinâmicos, e as matrizes são uma grande parte da flexibilidade do uso do JSON como formato de dados.
Começos humildes
Uma forma comum de consultar matrizes no n1ql (conforme explicado no blog vinculado) é a seguinte:
|
1 |
SELECT (ANY v IN [1, 2, 3, 4, 5] SATISFIES v > 4 END) as is_found, (ANY v IN [1, 2, 3, 4, 5] SATISFIES v = 7 END) as not_found; |
Neste exemplo, estamos dizendo: "obtenha os itens da matriz que correspondem à condição na instrução SATISFIES".
Se aplicássemos esse método às nossas tentativas de consultar várias matrizes em um documento JSON, provavelmente teríamos a seguinte aparência:
|
1 2 3 |
SELECT public_likes, reviews FROM _default WHERE type="hotel" AND ANY r IN reviews SATISFIES r.author = "Ozella Sipes" END AND ANY l IN public_likes SATISFIES l = "Ozella Sipes" END LIMIT 1; |
No entanto, isso não resultaria em uma consulta de alto desempenho, pois o N1QL atualmente exige que você construa uma única matriz indexável a partir das matrizes do documento, conforme observado aqui.
Criação de índices para vários campos de matriz
Então, como posso construir esse índice? Vamos dar um exemplo, usando nosso caso de uso de coleta de dados sobre hóspedes que gostaram e avaliaram nossos hotéis.
|
1 2 3 4 5 |
CREATE INDEX `reviewers_likes_idx` ON `_default`( DISTINCT ARRAY ( DISTINCT ARRAY [l,r.author] FOR r IN reviews END) FOR l in public_likes END) WHERE type="hotel"; |
O que estamos fazendo aqui é criar um índice com uma única matriz de curtidas e avaliações combinadas. Essas são as práticas recomendadas e estão de acordo com a observação em nossa documentação. Apenas para mostrar uma maneira que você pode ter pensado ser a correta: aqui está a maneira não suportada e definitivamente não indexar vários campos de matriz:
|
1 |
CREATE INDEX `not_the_right_idx` ON `_default`( DISTINCT (ARRAY r.field FOR r in json_obj END), likes); |
Isso indexaria vários campos de matriz - o que não é aconselhável.
Aprimorando a consulta
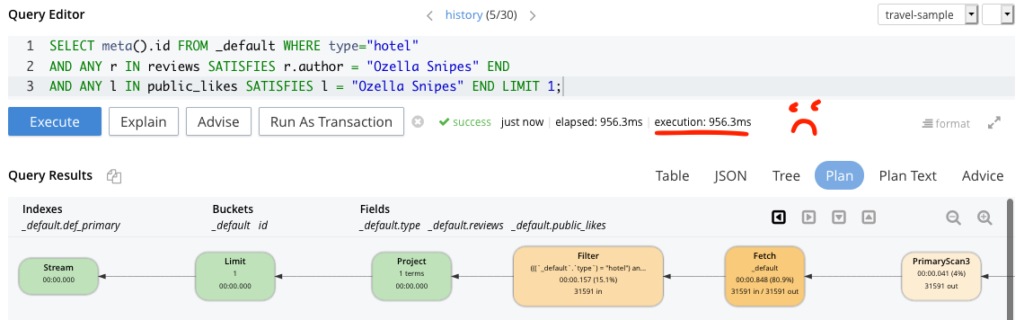
Abaixo estão dois exemplos de consultas que foram executadas em nosso query workbench. Usando minha consulta aprimorada, reduzi meu tempo de execução de 956,3 ms para aproximadamente 4 ms. Experimente você mesmo, a consulta aprimorada está no final deste blog.
Consulta sem desempenho
Consulta com desempenho aprimorado

Em essência, ambas as consultas funcionariam, mas o tempo necessário para executá-las é muito diferente, e isso se deve ao fato de estarmos usando o índice cuidadosamente elaborado e de práticas recomendadas na última consulta. Se você acompanhou o processo até aqui, pode executá-lo por conta própria. Observe que adicionei "Ozella Sipes" para ser tanto um autor de avaliação quanto um curtidor público em um dos documentos do hotel para testar o funcionamento da minha consulta! Seus resultados podem ser diferentes dependendo do nome que você usar.
|
1 2 3 4 5 |
SELECT META().id FROM _default WHERE type="hotel" AND ANY l IN public_likes SATISFIES ( ANY r IN reviews SATISFIES [l,r.author] = ["Ozella Sipes", "Ozella Sipes"] END) END LIMIT 1; |
Espero que este blog tenha sido útil e que tenha lhe dado uma ideia de que, em alguns casos, também é necessário considerar o uso da consulta certa para obter o desempenho certo!