Couchbase com Windows e .NET - Parte 2 - Linguajar
Esta postagem do blog é a parte 2 de uma série. A Parte 1 abordou como instalar e configurar o Couchbase no Windows.
Em Parte 1 - ConfiguraçãoNa seção "Como obter um produto", mostrei os princípios básicos de como obter Servidor Couchbase em funcionamento. Se você for como eu, está ansioso para começar a programar e ver o que pode fazer. Mas, antes disso, quero falar um pouco sobre o jargão do Couchbase. Não é uma ferramenta difícil de usar, mas é diferente dos sistemas RDBMS, como o SQL Server, com os quais você provavelmente está acostumado. Portanto, esta série de postagens no blog é tanto para você quanto para mim: Estou aprendendo à medida que vou avançando.
Aqui está a versão resumida do ponto de vista de um desenvolvedor: Um Couchbase agrupamento contém nós. Os nós contêm baldes. As caçambas contêm documentos. Os documentos podem ser recuperados de várias maneiras: por suas chaves, consultados com N1QLe também por meio de visualizações (que usam map/reduce). (Com o Couchbase 4.5, peças de documentos podem ser atualizados com o subdocumento API). Agora vamos examinar cada elemento em mais detalhes.
Aglomerado
Para começar, vamos falar sobre um "agrupamento." Um dos pontos fortes do Couchbase é sua capacidade de expansão: instalar servidores adicionais para lidar com mais dados de forma eficiente. Isso contrasta com o aumento de escala, que consiste em substituir um servidor por outro mais robusto e rápido (o que também pode ser feito com o Couchbase). Um cluster é uma coleção de nós relacionados que se coordenam entre si e atuam como um servidor lógico. Ao usar o Couchbase, você está sempre lidando com um cluster, mesmo que tenha apenas um nó nesse cluster. "Couch" é um acrônimo de "Cluster Of Unreliable Commodity Hardware".
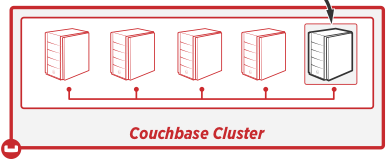
Nó
Um nó é um componente único em um cluster. Geralmente corresponde a um servidor. Ao definir um cluster, você define uma cota de RAM (por cada serviço). Essa é a quantidade de RAM que cada nó do cluster usará para fornecer um determinado serviço. Portanto, se a cota de RAM de dados for de 2 gb, cada nó do cluster que fornece um serviço de dados terá 2 gb de RAM para trabalhar. Cada nó também contribui com espaço em disco para o cluster.
Um nó fornece um ou mais serviços: armazenamento de dados, indexação, consulta e pesquisa de texto completo. Você pode configurar seu cluster da maneira que desejar: um nó que forneça todos os serviços até um nó para cada tipo de serviço e, em seguida, você pode reduzir e/ou aumentar a escala. (Exemplo: Eu poderia adicionar mais 5 nós para armazenamento de dados, mais 1 nó para indexação e usarei um único servidor realmente robusto para consulta).
Os nós também armazenam dados de réplica de outros nós. Dessa forma, se outro nó ficar inativo, os dados da réplica poderão ser "promovidos" para ativos e o aplicativo poderá continuar seu caminho.
Do ponto de vista da escrita do código, todo esse comportamento deve ser transparente. A configuração dos nós em um cluster pode mudar (e mudará), mas o código não precisa mudar.
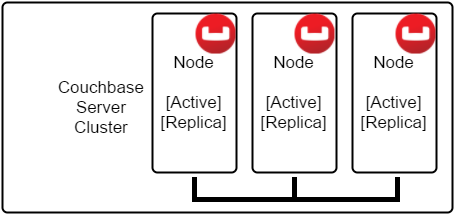
Balde
A balde é um local para armazenar documentos. Cada documento tem uma chave. Em um bucket, cada chave deve ser exclusiva. Os documentos em um compartimento não precisam ser semelhantes. Você pode armazenar um documento que contenha informações sobre um usuário e um documento com informações sobre um edifício. É possível configurar vários compartimentos em um nó, mas é recomendável limitar-se a 10 compartimentos ou menos. Para usar uma analogia com o banco de dados relacional, um bucket é mais parecido com uma instância ou catálogo de banco de dados. Não é como uma tabela.
O motivo pelo qual o Couchbase é tão rápido é que cada bucket armazena muitos de seus documentos na RAM. Quando chega uma solicitação de um documento, o documento (ou pelo menos os metadados do documento) provavelmente já estará na RAM, pronto para ser usado - sem necessidade de acesso ao disco. Quando um documento novo ou atualizado é recebido, ele é atualizado na RAM e, em seguida, colocado em uma fila para gravá-lo no disco e replicá-lo para outros nós. Quando a memória precisa ser liberada para outros documentos, os metadados permanecem na RAM para recuperação posterior: somente o valor é ejetado (a menos que você configurar o bucket de outra forma).
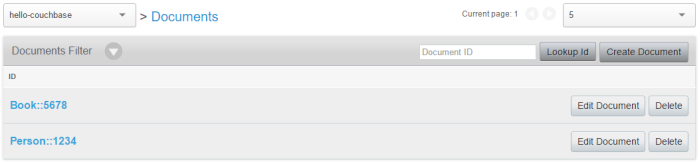
Documento
Em um sentido muito básico, um bucket do Couchbase é apenas um Dictionary gigante. Você pode usar o que quiser para a chave (desde que seja exclusiva) e pode colocar o que quiser no valor. No entanto, se você decidir armazenar JSON no valor, também obterá funcionalidades adicionais: estrutura, indexação, N1QL, exibições etc. Portanto, embora seja possível e suportado o uso de valores não JSON, normalmente a maioria dos valores será armazenada como JSON. É por isso que o Couchbase é chamado de "banco de dados de documentos". Cada bucket contém documentosque são um valor e metadados associados (como a chave).
Portanto, em inglês, faria sentido dizer coisas como:
- "Ei, cluster X do Couchbase, no bucket 'foo', por favor me dê o valor do documento com a chave 'bar'"
- "Ei, cluster X do Couchbase, no bucket 'foo', aqui está um novo documento com o valor 'baz', que tem uma chave de 'qux'
- "Ei, cluster X do Couchbase, no bucket 'foo', por favor, altere o valor do documento com a chave 'corge' para ter um valor de 'grault'
N1QL
O Couchbase reconhece que os bancos de dados relacionais têm sido uma grande parte da carreira de muitos desenvolvedores. Muitos desenvolvedores se sentem à vontade para escrever SQL. No entanto, os bancos de dados de documentos não funcionam da mesma forma que os bancos de dados relacionais, portanto, muitas vezes eles precisam aprender uma maneira totalmente nova de fazer as coisas. No entanto, com o Couchbase Server, se você estiver usando documentos JSON, poderá escrever consultas em uma linguagem chamada N1QL (N1QL significa "Non-first Normal Form Query Language" e se pronuncia "nickel"). N1QL é um superconjunto de SQL. Isso significa que, basicamente, se você conhece SQL, então conhece N1QL. Há algumas diferenças e algumas palavras-chave extras, mas aqui está um exemplo para mostrar como elas são semelhantes:
|
1 2 3 4 |
SELECIONAR nome, autor DE `livros-balde` ONDE ANO(publicado) >= 1998 |
Isso retornará algo como:
|
1 2 3 4 5 6 7 |
{ "resultados": [ { "name" (nome) : "O Pequeno Livro da Calma", "autor" : "Manny Bianco" }, { "name" (nome) : "AOP em .NET", "autor" : "Matthew D. Groves" } ] } |
Como mostrarei em posts posteriores do blog, o Linq2Couchbase A biblioteca aproveita o N1QL para oferecer um provedor Linq que será muito semelhante ao Entity Framework, NHibernate.Linq ou outros provedores Linq com os quais você está acostumado.
Índices
Índices no Couchbase são tão importantes quanto nos bancos de dados relacionais. Provavelmente mais, devido ao volume de dados que o Couchbase pode manipular à medida que se expande.
Para habilitar as consultas N1QL em um bucket, você precisa, no mínimo, criar um índice primário. Esse é um índice no próprio bucket. Veja como criar um com o N1QL: CREATE PRIMARY INDEX ON my-bucket;
Se estiver usando documentos JSON, você poderá criar índices com base nos campos dos documentos JSON. Por exemplo, se você tiver muitos documentos com "nome" ou "autor" e fizer consultas com frequência com base nesses campos, poderá criar índices para eles. Esses índices são chamados de "índices secundários".
Conclusão
Estou tão ansioso quanto você para mergulhar no código, mas é bom aprender esse jargão primeiro. Tentei me concentrar nos conceitos mais importantes em detrimento de alguns detalhes. Portanto, se você tiver dúvidas, deixe um comentário abaixo, Entre em contato comigo no Twitterou envie-me um e-mail para matthew.groves AT couchbase DOT com. Gostaria muito de ouvir sua opinião.