A versão 6.5 do Couchbase inclui uma extensa lista de recursos de consulta de banco de dados de nível empresarial que permite aos clientes expandir a adoção do banco de dados NoSQL em aplicativos de banco de dados tradicionais. A versão adicionou recursos transacionais, funções Analytical Window, funções JS definidas pelo usuário, bem como Index Advisor para melhorar o desempenho das consultas. Como o desempenho é um dos aspectos mais importantes da plataforma Couchbase, a nova versão também inclui um conjunto de novos aprimoramentos para fortalecer ainda mais o Couchbase Index Service e melhorar a eficiência operacional. Esses recursos estão agrupados sob o título geral de Confiabilidade, capacidade de gerenciamento e capacidade de serviço - Index Service RMS.
1. ALTER INDEX para alterar a contagem de réplicas do índice
Na versão 6.5.0, adicionamos o tão solicitado suporte para alterar o número de réplicas de um índice usando o comando ALTER INDEX. A contagem de réplicas pode ser alterada usando o comando ALTER, como no exemplo abaixo -
|
1 |
ALTER INDEX `travel-sample`.airlines_idx WITH {"action":"replica_count","num_replica": 3}' |
ação para ALTER INDEX é replica_count e o parâmetro num_replica especifica o novo número de réplicas do índice. Se o valor num_replica na instrução ALTER for maior que a contagem atual de réplicas, serão criadas réplicas adicionais; se for menor que a contagem atual de réplicas, as réplicas serão removidas.
2. ALTER INDEX para eliminar uma réplica de índice
O comando ALTER INDEX foi aprimorado para eliminar uma réplica de índice individual usando a sintaxe a seguir:
|
1 |
ALTER INDEX `travel-sample`.airlines_idx WITH {"action":"drop_replica","replicaId": 2}' |
ação é índice de queda e replicaId é o ID da réplica, que é um número que identifica uma réplica. O replicaId de uma réplica e o host em que ela reside podem ser obtidos na API REST getIndexStatus.
Quais são os benefícios? Melhor capacidade de gerenciamento das réplicas de índice - maneira mais fácil de aumentar/diminuir a contagem de réplicas ou eliminar uma réplica de índice específica. Obtenha mais informações em:
https://docs.couchbase.com/server/6.5/n1ql/n1ql-language-reference/alterindex.html
3. Aprimorar o tratamento de reversão de DCP
A reversão do DCP acontece no serviço de índice quando ocorre uma falha em um dos nós de dados e uma réplica de dados é promovida a ativa. Nem todo failover leva à reversão. Essa situação só acontece quando o serviço de índice tem mais dados/vbuuid recentes do que a réplica de dados antes do failover. Se a réplica de dados se tornar ativa após um failover, o serviço de índice receberá uma reversão. Consulte a seção Documentação do DCP para obter mais detalhes. Na pior das hipóteses, o DCP pode solicitar que o serviço de índice reverta para 0.
Com esse aprimoramento, o tratamento de reversão do DCP para o serviço de índice ficou mais robusto.
Quando o serviço de índice receber uma reversão de DCP para 0, ele tentará reverter para seus instantâneos de índice mais atuais, em vez de reconstruir o índice inteiro.
Quais são os benefícios:
- O serviço de índice não precisará mais reconstruir seus índices do zero quando o nó de dados sofrer failover automático.
- O serviço de índice continuará atendendo aos clientes de consulta sem nenhuma interrupção usando seu instantâneo mais atual.
- Como os instantâneos do disco de índice são tirados uma vez a cada 10 minutos, ele pode estar fornecendo dados obsoletos durante o período em que o índice está se recuperando do serviço de dados. Se scan_consistency for definido como request_plus, as varreduras aguardarão até que um instantâneo consistente seja criado e os resultados obsoletos não serão retornados.
4. Otimizar o snapshotting na memória
O servidor Couchbase foi projetado para ser eventualmente consistente. No entanto, o aplicativo pode alterar esse comportamento solicitando que o serviço de índice inclua todos os documentos atualizados em seus índices antes de processar a consulta, por meio da configuração de consistência de consulta request_plus. Espera-se que o tempo de resposta da consulta tenha algum atraso, pois o serviço precisa garantir que os índices sejam atualizados antes de processar a consulta. A frequência da geração de instantâneos na memória para índices foi aumentada para cada 10 ms para acelerar as consultas request_plus.
Quais são os benefícios:
- No Couchbase 6.5, otimizamos esse processo acelerando a captura de instantâneos do índice na memória. As consultas de aplicativos, usando essa configuração (request_plus), agora podem ver o tempo de resposta reduzido em mais de 45%.
5. Aprimoramentos no uso da memória do projetor
O Projector é um processo que reside no nó de dados que processa as mutações recebidas em nome do serviço de índice. O Projector garante que somente as mutações que envolvem os campos do documento, que fazem parte de qualquer índice, sejam enviadas para o Serviço de índice. O uso da memória do Projector pode ser afetado negativamente com altas taxas de mutação, tamanho grande do documento e downstream mais lento. Esse aprimoramento envolve a reconfiguração das várias configurações internas do projetor para garantir que o uso da memória do processo seja mantido em um nível ideal.
Quais são os benefícios:
- Os casos de teste de desempenho mostram que o RSS (uso de memória) do projetor de pico diminuiu de 1,5 GB para 176 MB (para uma carga de trabalho específica) sem afetar o tempo de criação do índice.
6. Melhorar o tempo de resposta do projetor ao indexador
Sob carga pesada, o processo do projetor pode ficar lento na resposta ao serviço de indexação, o que se deve à lentidão das mensagens de controle de comunicação no canal do projetor. Foi introduzida uma otimização para separar os canais de controle e de dados no projetor e também para priorizar as mensagens de controle em relação aos dados.
Quais são os benefícios:
- Sob pressão de memória, o projetor continua a responder às mensagens de controle do indexador e podemos ver uma redução nas falhas de rebalanceamento.
7. Criar todos os índices não criados de uma só vez
O comando N1QL para BUILD index atualmente usa um único nome ou uma lista de nomes de índices. Esse comando foi aprimorado para receber o resultado de uma consulta, permitindo que os administradores enviem um único comando para criar todos os índices não criados. Isso é particularmente útil após uma restauração do banco de dados, quando o administrador precisa reconstruir todos os índices que estão em estado diferido.
|
1 2 3 4 5 6 |
BUILD INDEX ON `travel-sample` ((SELECT RAW name FROM system:indexes WHERE keyspace_id = 'travel-sample' AND state = 'deferred' )); |
Quais são os benefícios:
- O administrador do banco de dados pode emitir um único comando BUILD para reconstruir todos os índices não construídos (diferidos).
8. Permitir varreduras durante o aquecimento do indexador
Quando o indexador é reiniciado, os índices são recuperados de persistiu armazenamento. Se o número de índices por nó for alto, isso pode levar muito tempo (até alguns minutos). Antes dessa melhoria, as varreduras eram desativadas durante o aquecimento do indexador. Aprimoramos esse comportamento para permitir varreduras nos índices que estão aquecidos e que têm um instantâneo consistente disponível. Se um instantâneo consistente não estiver disponível durante o aquecimento (isso acontece quando o serviço de dados avança), um erro será retornado para que um índice de réplica em outro nó do indexador possa ser tentado novamente.
Quais são os benefícios:
- Esse aprimoramento permite melhor continuidade do aplicativo e disponibilidade do serviço no caso de reinicializações do processo do indexador.
9. Aplicar alterações nas configurações dinamicamente sem reiniciar o indexador
Antes desse aprimoramento, a alteração das configurações que permitem/desproíbem chaves grandes, controlam o tamanho das chaves indexadas e dos buffers de tempo de execução correspondentes necessários para processar as chaves de índice exigia a reinicialização do processo do indexador, causando a reinicialização dos indexadores em todo o cluster, o que levava à indisponibilidade do serviço. Aprimoramos o comportamento para garantir que esses tamanhos sejam aplicados dinamicamente e que todos os buffers sejam redimensionados dinamicamente sem afetar o processamento das mutações.
Quais são os benefícios: As seguintes configurações agora podem ser alteradas dinamicamente sem causar a reinicialização do processo do indexador: max_seckey_size, max_array_seckey_size e allow_large_keys.
Não é necessária nenhuma alteração de configuração para ativar esse aprimoramento. Isso permite a continuidade do aplicativo e a disponibilidade do serviço quando as configurações acima são modificadas.
10. Localizar índices não utilizados
Em aplicativos grandes que usam banco de dados, pode haver muitos índices criados, mas é possível que nem todos estejam sendo usados no passado recente ou não estejam sendo usados. Para facilitar a identificação de quais índices não estão sendo usados, de modo que possam ser descartados, agora fornecemos uma estatística para cada índice que tem o registro de data e hora da última consulta conhecida desse índice como registro de data e hora Unix (que está em nanossegundos). Essa estatística não é redefinida na reinicialização do indexador, pois é mantida localmente no nó do indexador. Essa estatística é uma heurística para obter uma estimativa do tempo da última consulta e não pode ser exata, pois o intervalo de persistência da estatística é de 15 minutos. Ela pode ser obtida usando a API REST de estatísticas do indexador e também está disponível na interface do usuário de definição de índice.
|
1 |
curl -u <username>:<password> <hostname>:9102/api/v1/stats | json_pp | grep last_known_scan_time "travel-sample:airlines_idx:last_known_scan_time" : 1579179249769780000, |
Você também pode usar o N1QL para consultar os índices não utilizados
|
1 2 3 4 5 |
SELECT ARRAY { "index_name":a.name, "last_scan_time":millis_to_str(a.val.last_known_scan_time/1000000) } FOR a IN OBJECT_PAIRS(results) END FROM curl("https://<hostname>:9102/api/v1/stats", {"user":"<username>:<password>"}) results |
11. Melhorias nas estatísticas
Novas estatísticas foram adicionadas ao registro de estatísticas periódicas no indexador e também no projetor. Essas estatísticas são:
| estatísticas | Descrição | Disponível no ponto de extremidade REST compatível |
| num_scan_timeouts | Número de solicitações de varredura que atingiram o tempo limite aguardando um instantâneo ou durante a varredura em andamento. | Sim |
| num_scan_errors | Número de solicitações de varredura que falharam devido a qualquer erro que não seja o tempo limite. | Sim |
| latência média de varredura | Média de execução das latências de varredura observadas para um determinado índice | Não |
| last_known_scan_time | Um registro de data e hora Unix int64 que representa a última hora conhecida de um índice. | Sim |
| key_size_distribution | Uma distribuição de tamanhos de chaves em vários grupos de tamanhos | Não |
| arrkey_size_distribution | key_size_distribution - Uma distribuição de tamanhos de chave em vários intervalos de tamanho | Não |
| num_items_flushed | Número de chaves de índice gravadas no armazenamento de índices. | Sim |
| initial_build_progress | Progresso da construção inicial de um índice em porcentagem | Sim |
| taxa de drenagem média | Uma média contínua do número de itens descarregados no armazenamento de índices | Sim |
| num_pending_requests | Número de solicitações de varredura que estão pendentes ou em andamento no momento. | Sim |
| memory_total_storage | memory_total_storage - Tamanho do uso total do jemalloc pelo armazenamento do índice. | Sim |
| projetor_latência | Essa estatística mede a latência média do processamento de mutação no projetor, ou seja, do momento em que a mutação chega do nó de dados até o momento em que é enviada ao nó indexador pelo projetor. Ela é mantida por nó de dados no indexador. Isso ajuda a identificar qual projetor (em um nó de dados) está levando mais tempo para processar as mutações. | Não |
12. Melhorias na interface do usuário do índice
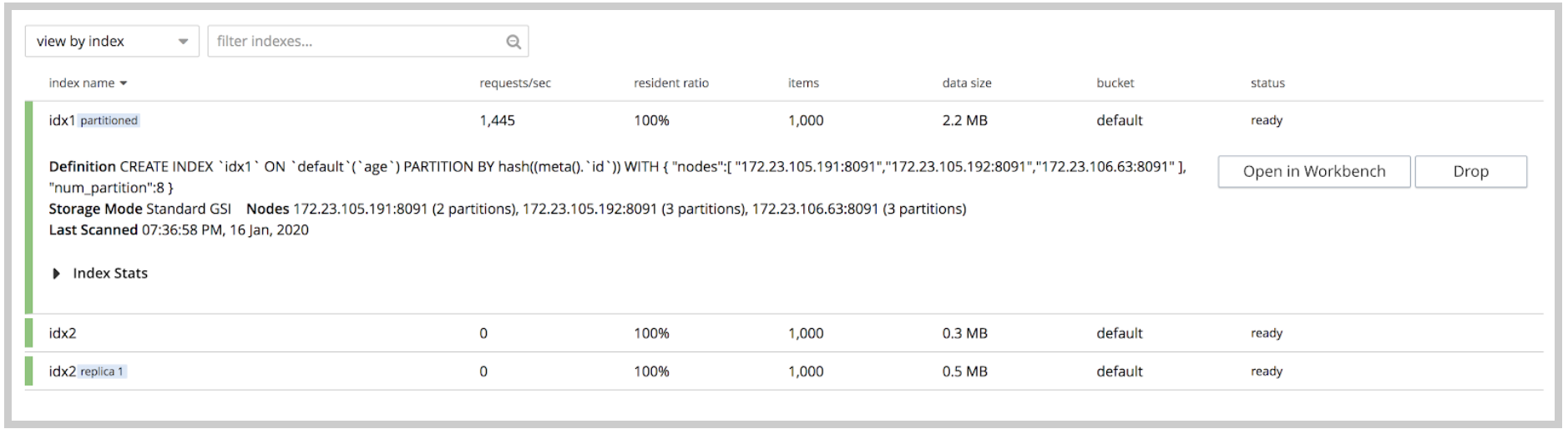
A interface do usuário do índice na versão 6.5 foi aprimorada para incluir informações resumidas importantes sobre o índice, como solicitações/seg, taxa de residentes, itens, tamanho dos dados e status. A expansão de um índice individual mostra a definição do índice e, no caso de um índice particionado, as informações sobre seus nós e partições.
Resumo do índice
Estatísticas do índice
Um novo acréscimo significativo à Index UI são as estatísticas de índice para cada índice, que exibem uma visualização gráfica das principais estatísticas, como porcentagem de residentes, tamanho dos dados, tamanho do disco, fragmentação do índice, taxa de drenagem, entre outras. Um resumo completo das estatísticas de todo o serviço de serviço de índice (em todos os índices) é exibido na parte inferior da página, capturando informações como cota de RAM do serviço de índice, RAM usada/restante, porcentagem de RAM do serviço de índice, taxa de varredura total e fragmentação de índices. Esses aprimoramentos na interface do usuário do índice ajudam a facilitar o monitoramento dos índices com as estatísticas mais importantes prontamente disponíveis.
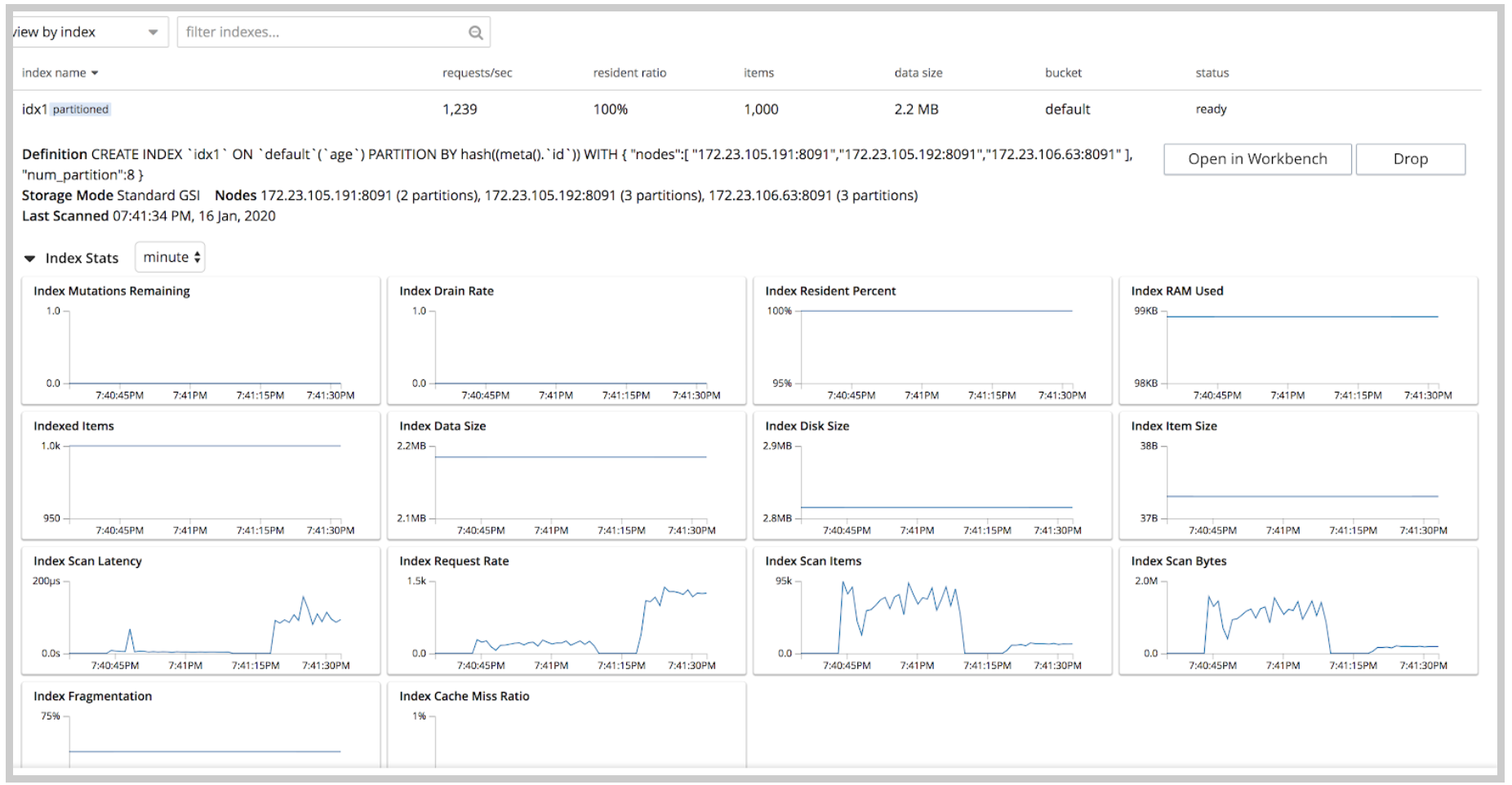
Resumo do serviço de índice na parte inferior da página

Resumo
Estamos muito animados com os aprimoramentos do novo serviço de índice (GSI) RMS para o Couchbase v6.5, pois esses recursos atenderão a muitas solicitações de nossos clientes. Como sempre, esperamos receber feedback sobre esses aprimoramentos,
Recursos
- Baixar: Faça o download do Couchbase Server 6.5
- Documentação: Couchbase Server 6.5 O que há de novo
- Todos os blogs 6.5
Gostaríamos muito de saber se você gostou dos recursos da versão 6.5 e como ela beneficiará sua empresa no futuro. Compartilhe seu feedback por meio dos comentários ou na seção fórum.
Coautor: Prathibha Bisarahalli | Engenheiro de software sênior