Quando foi a última vez que você usou um banco de dados? A maioria de nós está tão acostumada a interfaces fáceis de usar, como o TikTok, aplicativos bancários e programas de trabalho, que não percebe que está interagindo com bancos de dados o tempo todo. Estamos ainda menos inclinados a pensar no que está acontecendo nos bastidores, que podem ser divididos em dois tipos de atividade: transacional e analítica. Uma transação pode ser o upload de um vídeo ou a realização de uma compra. A análise de dados pode ser tão simples quanto analisar os números em uma planilha.
Em um banco de dados relacionalEm um sistema de dados, os dados de qualquer tipo de atividade são organizados em linhas e colunas que formam uma tabela (ou tabelas) para mostrar a relação entre os pontos de dados. Os dados podem ser armazenados de duas maneiras diferentes: Em um banco de dados colunar (column store), todos os dados são agrupados por coluna. Em um banco de dados orientado a linhas (armazenamento de linhas), todos os dados são agrupados por linha.
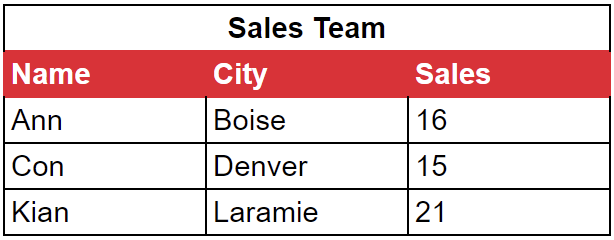
Os bancos de dados colunares são excelentes para lidar com cargas de trabalho analíticasEnquanto os bancos de dados orientados por linha são mais adequados para cargas de trabalho transacionais. Para explicar as diferenças e discutir os prós e contras relativos, usaremos os dados desta tabela que rastreia uma equipe de vendas:
O que é um banco de dados colunar?
Um banco de dados colunar armazena dados agrupados por colunas em vez de por linhas, otimizando o desempenho de consultas analíticas. Cada coluna contém dados do mesmo tipo, o que permite uma compactação eficiente. E como uma consulta precisa acessar apenas as colunas relevantes, o design aumenta a velocidade de recuperação de dados.
Enquanto um banco de dados colunar é um tipo de banco de dados relacional, o Couchbase Capella™ é um NoSQL DBaaS que também usa agrupamento de colunas para realizar análises extremamente rápidas. Para isso, ele ingere rapidamente JSON e outras fontes de dados e convertendo-os em armazenamento colunar.
Gravação em bancos de dados de armazenamento de colunas
Em um banco de dados colunar, os dados são gravados no disco por coluna. Isso significa que os dados da nossa equipe de vendas seriam agrupados e armazenados da seguinte forma:
|
1 |
Ann Con Kian | Boise Denver Laramie | 16 15 21 |
Vamos adicionar o seguinte registro para um novo funcionário, Gene:

Para adicionar os dados do Gene, nós os anexamos ao final das respectivas colunas da seguinte forma:
|
1 |
Ann Con Kian Gene | Boise Denver Laramie Hanford | 16 15 21 0 |
Leitura de bancos de dados de armazenamento de colunas
Em um banco de dados colunar, os dados são lidos acessando colunas específicas em vez de linhas inteiras. Quando uma consulta é executada, o banco de dados recupera apenas as colunas necessárias para atender às condições da consulta. Esse processo envolve o acesso direto aos dados da coluna relevante, o que pode reduzir significativamente a sobrecarga de E/S e melhorar o desempenho da consulta, especialmente para cargas de trabalho analíticas que normalmente envolvem agregações, filtragem e projeções seletivas.
Ao ler apenas as colunas necessárias, os bancos de dados colunares minimizam a transferência de dados e maximizam a utilização do cache da CPU. Para consultas analíticas, isso resulta em tempos de execução de consulta mais rápidos em comparação com bancos de dados orientados por linhas.
Por exemplo, se quiséssemos calcular o número médio de vendas da equipe de vendas, um banco de dados colunar só precisaria acessar a coluna com os números de vendas. Isso seria muito mais rápido e eficiente do que um banco de dados orientado por linhas, que teria de acessar todos os dados linha por linha para extrair os dados de vendas relevantes.
O que é um banco de dados de armazenamento em linha?
Um banco de dados orientado a linhas organiza os dados por linhas, sendo que cada linha contém informações sobre uma única entidade ou registro. Esse design é adequado para cargas de trabalho transacionais em que linhas inteiras são acessadas ou modificadas com frequência. Os bancos de dados orientados a linhas são excelentes em sistemas de processamento de transações, onde podem garantir inserções, atualizações e exclusões rápidas, armazenando dados de forma contígua no disco para minimizar a sobrecarga das operações em nível de linha.
Gravação em bancos de dados de armazenamento em linha
Em um banco de dados de armazenamento em linha, os dados são gravados no disco por linha e não por coluna.
Os dados da nossa equipe de vendas seriam armazenados da seguinte forma:
|
1 |
Ann Boise 16 | Con Denver 15 | Kian Laramie 21 |
Para adicionar o registro de Gene, nós o anexaríamos integralmente ao final dos dados existentes, da seguinte forma:
|
1 |
Ann Boise 16 | Con Denver 15 | Kian Laramie 21 | Gene Hanford 0 |
Essa abordagem garante que todos os atributos do registro sejam armazenados juntos, facilitando a recuperação rápida e as atualizações de linhas inteiras. Além disso, os bancos de dados orientados por linhas geralmente usam mecanismos de registro e buffer para otimizar as operações de gravação.
Leitura de bancos de dados de armazenamento em linha
Em um banco de dados de armazenamento em linha, os dados são lidos acessando linhas inteiras sequencialmente ou por meio de pesquisas de índice. Quando uma consulta é executada, o banco de dados recupera as linhas relevantes que contêm os dados solicitados. Esse processo de recuperação envolve a varredura das linhas no disco e a busca de registros inteiros que correspondam aos critérios da consulta. Embora os bancos de dados orientados por linhas sejam excelentes na recuperação rápida de registros inteiros, eles podem incorrer em sobrecarga quando apenas colunas específicas são necessárias. Como as linhas precisam ser recuperadas em sua totalidade, isso pode levar à transferência e ao processamento desnecessários de dados.
Banco de dados colunar vs. banco de dados de linhas
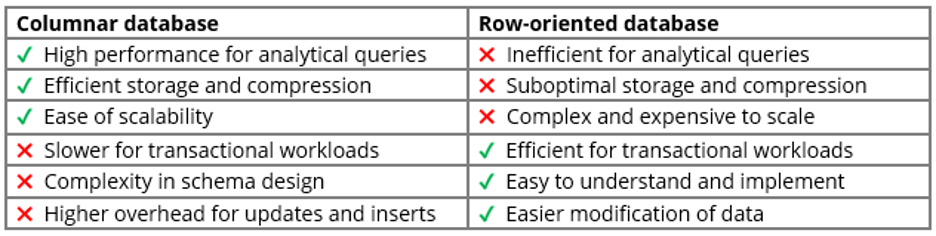
Os bancos de dados colunares e orientados por linhas têm vantagens e desvantagens distintas relacionadas à forma como os dados são organizados. Os bancos de dados colunares são excelentes em consultas analíticas e oferecem armazenamento eficiente, mas podem ter dificuldades com cargas de trabalho transacionais e são mais difíceis de atualizar. Por outro lado, os bancos de dados orientados por linhas são eficientes para cargas de trabalho transacionais e são mais fáceis de implementar e modificar, mas são ineficientes para consultas analíticas e oferecem armazenamento abaixo do ideal. Veja a seguir uma análise mais detalhada de seus prós e contras:
Prós dos bancos de dados colunares
-
- Alto desempenho para consultas analíticas - Os bancos de dados colunares são excelentes em cargas de trabalho analíticas de leitura intensa, oferecendo tempos de processamento de consulta rápidos devido à sua capacidade de ler apenas as colunas necessárias. Isso maximiza a utilização do cache da CPU e minimiza a sobrecarga de E/S.
- Armazenamento e compactação eficientes - Os dados são organizados por colunas, o que permite a aplicação de técnicas de compactação eficientes. Tipos e propriedades de dados semelhantes nas colunas permitem altas taxas de compactação para reduzir os custos de armazenamento e melhorar o desempenho das consultas.
- Facilidade de escalabilidade - Os bancos de dados colunares são vantajosos em termos de escalabilidade. Como os dados são armazenados em colunas, a adição de mais nós ou servidores pode ser simples, com cada nó lidando com um subconjunto de colunas. Essa escalabilidade é particularmente vantajosa para cargas de trabalho analíticas, em que os conjuntos de dados costumam ser grandes e estão em constante crescimento.
Contras dos bancos de dados colunares
-
- Mais lento para cargas de trabalho transacionais - Embora os bancos de dados colunares sejam excelentes em consultas analíticas, eles podem ter um desempenho mais lento em cargas de trabalho transacionais com muita gravação, envolvendo atualizações, inserções e exclusões frequentes.
- Complexidade no design do esquema - O projeto de um esquema para um banco de dados colunar pode exigir uma consideração cuidadosa da organização das colunas e dos tipos de dados para otimizar o desempenho da consulta e a eficiência do armazenamento.
- Maior sobrecarga para atualizações e inserções A atualização ou inserção de dados em um banco de dados colunar pode ser mais complexa e exigir mais recursos do que em bancos de dados orientados por linhas. Os bancos de dados colunares podem exigir processamento adicional para manter a consistência dos dados e garantir um armazenamento eficiente.
Prós dos bancos de dados em linha
-
- Eficiente para cargas de trabalho transacionais Os bancos de dados orientados por linhas são adequados para cargas de trabalho transacionais em que registros inteiros precisam ser recuperados, atualizados ou inseridos de forma rápida e eficiente. A estrutura de armazenamento baseada em linhas simplifica essas operações e garante o processamento rápido das transações.
- Fácil de entender e implementar - O modelo de armazenamento orientado por linhas se alinha ao entendimento intuitivo da organização de dados, facilitando o projeto, a implementação e a manutenção de bancos de dados com essa abordagem. Os desenvolvedores familiarizados com bancos de dados relacionais consideram os bancos de dados orientados por linhas fáceis de trabalhar.
- Modificação mais fácil dos dados - Os bancos de dados orientados por linhas facilitam a modificação de dados, permitindo atualizações, inserções e exclusões diretas sem sobrecarga significativa. Isso os torna adequados para cenários com operações de gravação frequentes ou requisitos de dados em evolução.
Contras dos bancos de dados em linha
-
- Ineficiente para consultas analíticas - Os bancos de dados orientados por linhas podem apresentar desempenho mais lento para consultas analíticas de leitura pesada que envolvem agregações, projeções e filtragem. A recuperação de linhas inteiras para essas consultas pode levar à transferência desnecessária de dados e à sobrecarga de processamento, reduzindo o desempenho da consulta em comparação com os bancos de dados colunares.
- Armazenamento e compactação abaixo do ideal - O armazenamento de dados em linhas pode resultar em taxas de compactação abaixo do ideal em comparação com bancos de dados colunares. Em bancos de dados orientados por linhas, as linhas geralmente contêm diversos tipos e propriedades de dados, o que torna difícil obter altos níveis de compactação e armazenamento eficiente.
- Complexo e caro para ser dimensionado Como os bancos de dados orientados por linhas precisam armazenar dados em linhas, pode ser mais complicado distribuir os dados de forma eficaz em vários servidores e nós. A solução geralmente envolve a adição de hardware mais potente, como o aumento dos recursos de CPU ou memória nos servidores existentes, o que pode se tornar proibitivamente caro à medida que o conjunto de dados cresce.
Exemplos de bancos de dados colunares
Alguns bancos de dados colunares conhecidos são:
-
- Amazon Redshift
- Apache Cassandra
- MariaDB ColumnStore
- Floco de neve
Exemplos de bancos de dados orientados por linhas
Dois dos bancos de dados orientados por linhas mais comuns são:
-
- PostgreSQL
- MySQL
Por que os bancos de dados colunares são melhores para análises
Os bancos de dados colunares superam os bancos de dados orientados por linhas na análise, principalmente devido à eficiência do armazenamento e da recuperação de dados. Aqui estão quatro maneiras pelas quais eles são melhores:
Estrutura de armazenamento colunar - Como os dados são armazenados em colunas e não em linhas, cada coluna pode ser armazenada separadamente no disco. Essa estrutura permite que melhores técnicas de compressão e codificação sejam aplicadas a cada coluna individualmente. Como as colunas normalmente contêm tipos de dados, valores ou propriedades semelhantes, os algoritmos de compactação podem atingir taxas de compactação mais altas em comparação com bancos de dados orientados por linhas, em que as linhas podem conter dados diversos.
Recuperação seletiva - As consultas analíticas geralmente envolvem a agregação ou a análise de um subconjunto de colunas em vez de linhas inteiras. Os bancos de dados colunares são excelentes nesses cenários porque podem recuperar seletivamente apenas as colunas necessárias para a consulta. Essa recuperação seletiva minimiza as operações de E/S do disco e maximiza a utilização do cache da CPU. Por outro lado, os bancos de dados orientados por linhas recuperam linhas inteiras mesmo para consultas que precisam de apenas algumas colunas, resultando em transferência de dados e sobrecarga de processamento desnecessárias.
Eficiência no processamento de dados - Ao executar consultas analíticas, os bancos de dados colunares operam diretamente em dados colunares compactados, permitindo o processamento eficiente de funções analíticas, como agregações, filtragem e projeções. Como tipos de dados semelhantes são armazenados de forma contígua, os bancos de dados colunares podem explorar o paralelismo SIMD (instrução única, vários dados) e outras técnicas de processamento vetorial, permitindo tempos de execução de consulta mais rápidos. Por outro lado, os bancos de dados orientados por linhas podem precisar descompactar linhas inteiras antes de executar operações analíticas, o que pode levar a um aumento da sobrecarga computacional.
Otimização de consultas - Os bancos de dados colunares são otimizados para análise por meio de estratégias de execução de consultas adaptadas ao seu formato de armazenamento. Essas otimizações incluem poda de coluna, pushdown de predicado e técnicas de processamento vetorial. A poda de colunas elimina leituras desnecessárias de colunas durante a execução da consulta, enquanto o predicado pushdown filtra as linhas no início do pipeline de processamento da consulta, reduzindo a quantidade de dados que precisam ser processados. As técnicas de processamento vetorizado operam em lotes de dados, explorando o paralelismo da CPU para melhorar o desempenho da consulta.
Conclusão
Enquanto os bancos de dados orientados por linhas são melhores para o processamento transacional, os bancos de dados colunares são superiores para o processamento analítico. As vantagens de um banco de dados orientado por linhas estão em sua capacidade de realizar inserções, atualizações e exclusões rápidas. Por outro lado, as principais vantagens de um banco de dados colunar são a compactação eficiente e o processamento rápido de consultas. Ao organizar os dados por coluna e empregar estratégias especializadas de execução de consultas, os bancos de dados colunares podem lidar com grandes cargas de trabalho analíticas e consultas complexas com tempos de resposta de consulta mais rápidos e melhor desempenho geral.
Recursos relacionados
Saiba mais sobre como escolher o banco de dados certo para suas cargas de trabalho de análise:
-
- Tipos de bancos de dados
- O que é a análise de Big Data?
- Comparação entre bancos de dados de documentos e bancos de dados relacionais
- Comparação de NoSQL: MongoDB vs. DynamoDB vs. Couchbase
- Couchbase Analytics adiciona serviço de dados em tempo real
- Comparação entre o Couchbase Capella e o Cosmos DB
- Banco de dados vs. Data Warehouse: Diferenças, casos de uso e exemplos
- Experimente o Couchbase Capella DBaaS gratuitamente
